 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDAR-VL: Stable and Efficient Block-wise Diffusion for Vision-Language Understanding
Dec 16, 2025



Block-wise discrete diffusion offers an attractive balance between parallel generation and causal dependency modeling, making it a promising backbone for vision-language modeling. However, its practical adoption has been limited by high training cost, slow convergence, and instability, which have so far kept it behind strong autoregressive (AR) baselines. We present \textbf{SDAR-VL}, the first systematic application of block-wise discrete diffusion to large-scale vision-language understanding (VLU), together with an \emph{integrated framework for efficient and stable training}. This framework unifies three components: (1) \textbf{Asynchronous Block-wise Noise Scheduling} to diversify supervision within each batch; (2) \textbf{Effective Mask Ratio Scaling} for unbiased loss normalization under stochastic masking; and (3) a \textbf{Progressive Beta Noise Curriculum} that increases effective mask coverage while preserving corruption diversity. Experiments on 21 single-image, multi-image, and video benchmarks show that SDAR-VL consistently improves \emph{training efficiency}, \emph{convergence stability}, and \emph{task performance} over conventional block diffusion. On this evaluation suite, SDAR-VL sets a new state of the art among diffusion-based vision-language models and, under matched settings, matches or surpasses strong AR baselines such as LLaVA-OneVision as well as the global diffusion baseline LLaDA-V, establishing block-wise diffusion as a practical backbone for VLU.
AsyncVLA: Asynchronous Flow Matching for Vision-Language-Action Models
Nov 18, 2025



Vision-language-action (VLA) models have recently emerged as a powerful paradigm for building generalist robots. However, traditional VLA models that generate actions through flow matching (FM) typically rely on rigid and uniform time schedules, i.e., synchronous FM (SFM). Without action context awareness and asynchronous self-correction, SFM becomes unstable in long-horizon tasks, where a single action error can cascade into failure. In this work, we propose asynchronous flow matching VLA (AsyncVLA), a novel framework that introduces temporal flexibility in asynchronous FM (AFM) and enables self-correction in action generation. AsyncVLA breaks from the vanilla SFM in VLA models by generating the action tokens in a non-uniform time schedule with action context awareness. Besides, our method introduces the confidence rater to extract confidence of the initially generated actions, enabling the model to selectively refine inaccurate action tokens before execution. Moreover, we propose a unified training procedure for SFM and AFM that endows a single model with both modes, improving KV-cache utilization. Extensive experiments on robotic manipulation benchmarks demonstrate that AsyncVLA is data-efficient and exhibits self-correction ability. AsyncVLA achieves state-of-the-art results across general embodied evaluations due to its asynchronous generation in AFM. Our code is available at https://github.com/YuhuaJiang2002/AsyncVLA.
Nirvana: A Specialized Generalist Model With Task-Aware Memory Mechanism
Oct 30, 2025Specialized Generalist Models (SGMs) aim to preserve broad capabilities while achieving expert-level performance in target domains. However, traditional LLM structures including Transformer, Linear Attention, and hybrid models do not employ specialized memory mechanism guided by task information. In this paper, we present Nirvana, an SGM with specialized memory mechanism, linear time complexity, and test-time task information extraction. Besides, we propose the Task-Aware Memory Trigger ($\textit{Trigger}$) that flexibly adjusts memory mechanism based on the current task's requirements. In Trigger, each incoming sample is treated as a self-supervised fine-tuning task, enabling Nirvana to adapt its task-related parameters on the fly to domain shifts. We also design the Specialized Memory Updater ($\textit{Updater}$) that dynamically memorizes the context guided by Trigger. We conduct experiments on both general language tasks and specialized medical tasks. On a variety of natural language modeling benchmarks, Nirvana achieves competitive or superior results compared to the existing LLM structures. To prove the effectiveness of Trigger on specialized tasks, we test Nirvana's performance on a challenging medical task, i.e., Magnetic Resonance Imaging (MRI). We post-train frozen Nirvana backbone with lightweight codecs on paired electromagnetic signals and MRI images. Despite the frozen Nirvana backbone, Trigger guides the model to adapt to the MRI domain with the change of task-related parameters. Nirvana achieves higher-quality MRI reconstruction compared to conventional MRI models as well as the models with traditional LLMs' backbone, and can also generate accurate preliminary clinical reports accordingly.
Layerwise Recurrent Router for Mixture-of-Experts
Aug 13, 2024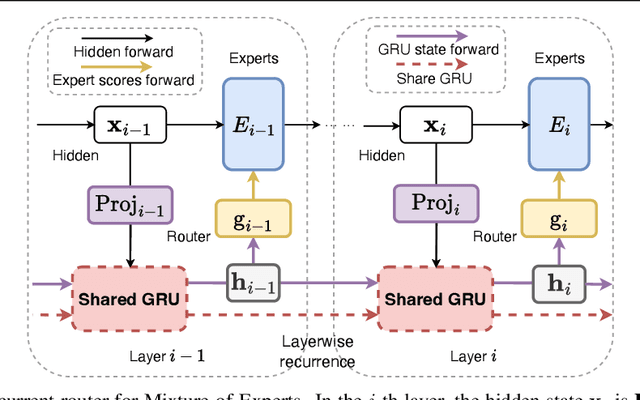
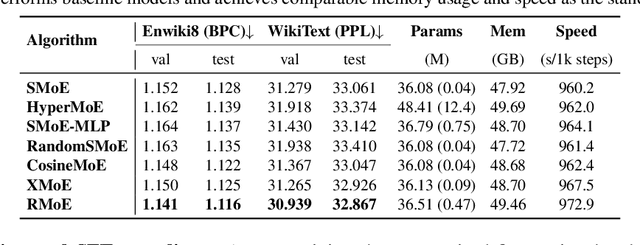
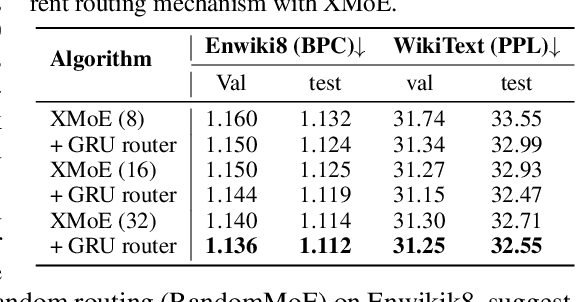
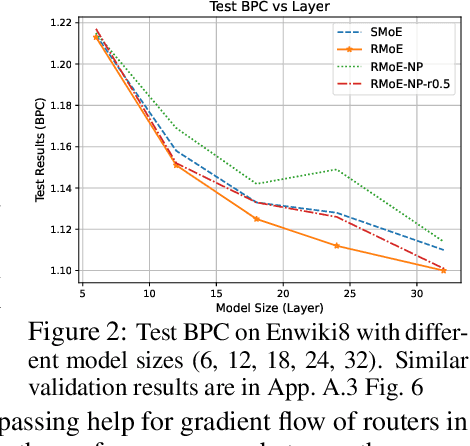
The scaling of large language models (LLMs) has revolutionized their capabilities in various tasks, yet this growth must be matched with efficient computational strategies. The Mixture-of-Experts (MoE) architecture stands out for its ability to scale model size without significantly increasing training costs. Despite their advantages, current MoE models often display parameter inefficiency. For instance, a pre-trained MoE-based LLM with 52 billion parameters might perform comparably to a standard model with 6.7 billion parameters. Being a crucial part of MoE, current routers in different layers independently assign tokens without leveraging historical routing information, potentially leading to suboptimal token-expert combinations and the parameter inefficiency problem. To alleviate this issue, we introduce the Layerwise Recurrent Router for Mixture-of-Experts (RMoE). RMoE leverages a Gated Recurrent Unit (GRU) to establish dependencies between routing decisions across consecutive layers. Such layerwise recurrence can be efficiently parallelly computed for input tokens and introduces negotiable costs. Our extensive empirical evaluations demonstrate that RMoE-based language models consistently outperform a spectrum of baseline models. Furthermore, RMoE integrates a novel computation stage orthogonal to existing methods, allowing seamless compatibility with other MoE architectures. Our analyses attribute RMoE's gains to its effective cross-layer information sharing, which also improves expert selection and diversity. Our code is at https://github.com/qiuzh20/RMoE
Dynamic Object Queries for Transformer-based Incremental Object Detection
Jul 31, 2024



Incremental object detection (IOD) aims to sequentially learn new classes, while maintaining the capability to locate and identify old ones. As the training data arrives with annotations only with new classes, IOD suffers from catastrophic forgetting. Prior methodologies mainly tackle the forgetting issue through knowledge distillation and exemplar replay, ignoring the conflict between limited model capacity and increasing knowledge. In this paper, we explore \textit{dynamic object queries} for incremental object detection built on Transformer architecture. We propose the \textbf{Dy}namic object \textbf{Q}uery-based \textbf{DE}tection \textbf{TR}ansformer (DyQ-DETR), which incrementally expands the model representation ability to achieve stability-plasticity tradeoff. First, a new set of learnable object queries are fed into the decoder to represent new classes. These new object queries are aggregated with those from previous phases to adapt both old and new knowledge well. Second, we propose the isolated bipartite matching for object queries in different phases, based on disentangled self-attention. The interaction among the object queries at different phases is eliminated to reduce inter-class confusion. Thanks to the separate supervision and computation over object queries, we further present the risk-balanced partial calibration for effective exemplar replay. Extensive experiments demonstrate that DyQ-DETR significantly surpasses the state-of-the-art methods, with limited parameter overhead. Code will be made publicly available.
Unlocking Continual Learning Abilities in Language Models
Jun 25, 2024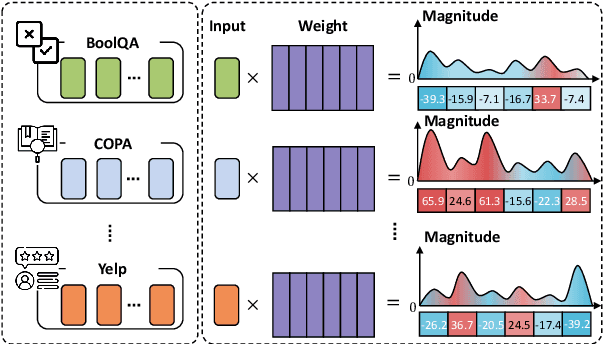
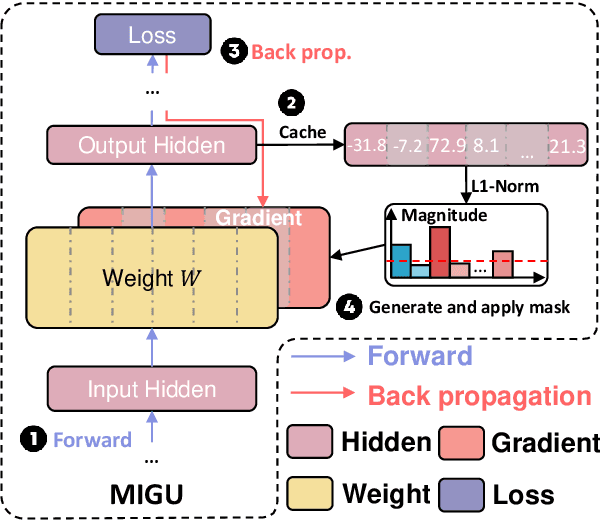
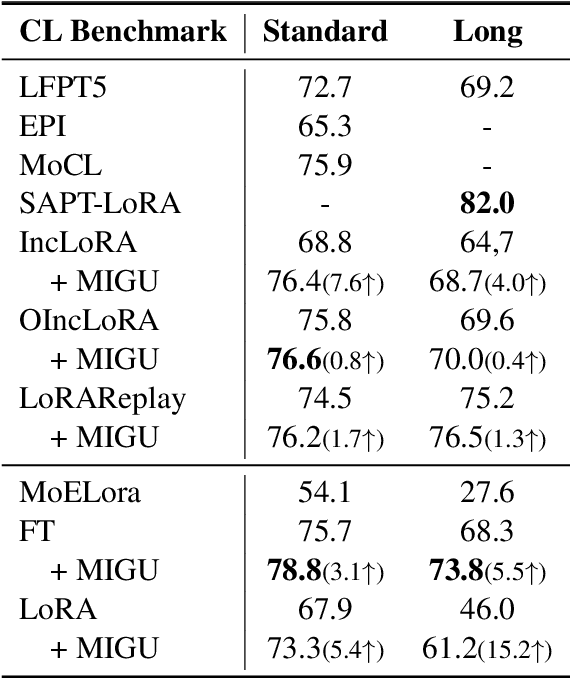
Language models (LMs) exhibit impressive performance and generalization capabilities. However, LMs struggle with the persistent challenge of catastrophic forgetting, which undermines their long-term sustainability in continual learning (CL). Existing approaches usually address the issue by incorporating old task data or task-wise inductive bias into LMs. However, old data and accurate task information are often unavailable or costly to collect, hindering the availability of current CL approaches for LMs. To address this limitation, we introduce $\textbf{MIGU}$ ($\textbf{M}$agn$\textbf{I}$tude-based $\textbf{G}$radient $\textbf{U}$pdating for continual learning), a rehearsal-free and task-label-free method that only updates the model parameters with large magnitudes of output in LMs' linear layers. MIGU is based on our observation that the L1-normalized magnitude distribution of the output in LMs' linear layers is different when the LM models deal with different task data. By imposing this simple constraint on the gradient update process, we can leverage the inherent behaviors of LMs, thereby unlocking their innate CL abilities. Our experiments demonstrate that MIGU is universally applicable to all three LM architectures (T5, RoBERTa, and Llama2), delivering state-of-the-art or on-par performance across continual finetuning and continual pre-training settings on four CL benchmarks. For example, MIGU brings a 15.2% average accuracy improvement over conventional parameter-efficient finetuning baselines in a 15-task CL benchmark. MIGU can also seamlessly integrate with all three existing CL types to further enhance performance. Code is available at \href{https://github.com/wenyudu/MIGU}{this https URL}.
LaDA: Latent Dialogue Action For Zero-shot Cross-lingual Neural Network Language Modeling
Aug 05, 2023Cross-lingual adaptation has proven effective in spoken language understanding (SLU) systems with limited resources. Existing methods are frequently unsatisfactory for intent detection and slot filling, particularly for distant languages that differ significantly from the source language in scripts, morphology, and syntax. Latent Dialogue Action (LaDA) layer is proposed to optimize decoding strategy in order to address the aforementioned issues. The model consists of an additional layer of latent dialogue action. It enables our model to improve a system's capability of handling conversations with complex multilingual intent and slot values of distant languages. To the best of our knowledge, this is the first exhaustive investigation of the use of latent variables for optimizing cross-lingual SLU policy during the decode stage. LaDA obtains state-of-the-art results on public datasets for both zero-shot and few-shot adaptation.