 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaDA: Latent Dialogue Action For Zero-shot Cross-lingual Neural Network Language Modeling
Aug 05, 2023Cross-lingual adaptation has proven effective in spoken language understanding (SLU) systems with limited resources. Existing methods are frequently unsatisfactory for intent detection and slot filling, particularly for distant languages that differ significantly from the source language in scripts, morphology, and syntax. Latent Dialogue Action (LaDA) layer is proposed to optimize decoding strategy in order to address the aforementioned issues. The model consists of an additional layer of latent dialogue action. It enables our model to improve a system's capability of handling conversations with complex multilingual intent and slot values of distant languages. To the best of our knowledge, this is the first exhaustive investigation of the use of latent variables for optimizing cross-lingual SLU policy during the decode stage. LaDA obtains state-of-the-art results on public datasets for both zero-shot and few-shot adaptation.
I3CL:Intra- and Inter-Instance Collaborative Learning for Arbitrary-shaped Scene Text Detection
Aug 16, 2021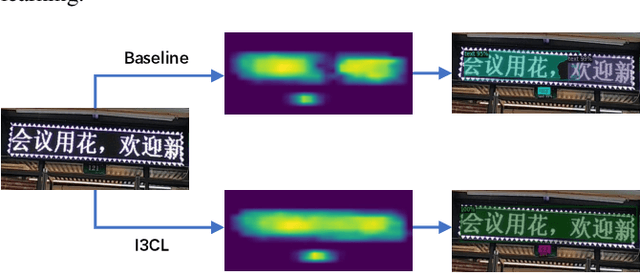
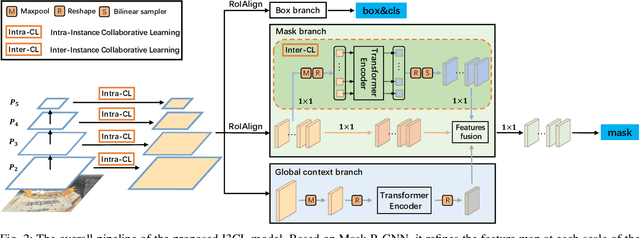

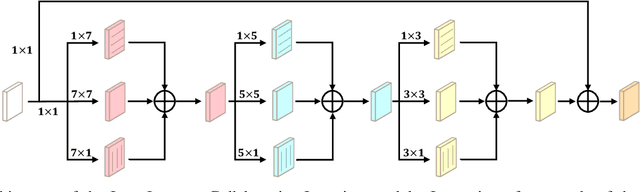
Existing methods for arbitrary-shaped text detection in natural scenes face two critical issues, i.e., 1) fracture detections at the gaps in a text instance; and 2) inaccurate detections of arbitrary-shaped text instances with diverse background context. To address these issues, we propose a novel method named Intra- and Inter-Instance Collaborative Learning (I3CL). Specifically, to address the first issue, we design an effective convolutional module with multiple receptive fields, which is able to collaboratively learn better character and gap feature representations at local and long ranges inside a text instance. To address the second issue, we devise an instance-based transformer module to exploit the dependencies between different text instances and a global context module to exploit the semantic context from the shared background, which are able to collaboratively learn more discriminative text feature representation. In this way, I3CL can effectively exploit the intra- and inter-instance dependencies together in a unified end-to-end trainable framework. Besides, to make full use of the unlabeled data, we design an effective semi-supervised learning method to leverage the pseudo labels via an ensemble strategy. Without bells and whistles, experimental results show that the proposed I3CL sets new state-of-the-art results on three challenging public benchmarks, i.e., an F-measure of 77.5% on ICDAR2019-ArT, 86.9% on Total-Text, and 86.4% on CTW-1500. Notably, our I3CL with the ResNeSt-101 backbone ranked 1st place on the ICDAR2019-ArT leaderboard. The source code will be made publicly available.