 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaoBench: A Large-Scale Multidimensional Lao Benchmark for Large Language Models
Nov 14, 2025The rapid advancement of large language models (LLMs) has not been matched by their evaluation in low-resource languages, especially Southeast Asian languages like Lao. To fill this gap, we introduce LaoBench, the first large-scale, high-quality, and multidimensional benchmark dataset dedicated to assessing LLMs' comprehensive language understanding and reasoning abilities in Lao. LaoBench comprises over 17,000 carefully curated samples spanning three core dimensions: knowledge application, K12 foundational education, and bilingual translation among Lao, Chinese, and English. The dataset is divided into open-source and closed-source subsets, with the closed-source portion enabling black-box evaluation on an official platform to ensure fairness and data security. Our data construction pipeline integrates expert human curation with automated agent-assisted verification, ensuring linguistic accuracy, cultural relevance, and educational value. Benchmarking multiple state-of-the-art LLMs on LaoBench reveals that current models still face significant challenges in mastering Lao across diverse tasks. We hope LaoBench will catalyze further research and development of AI technologies for underrepresented Southeast Asian languages.
Micro-Act: Mitigate Knowledge Conflict in Question Answering via Actionable Self-Reasoning
Jun 05, 2025Retrieval-Augmented Generation (RAG) systems commonly suffer from Knowledge Conflicts, where retrieved external knowledge contradicts the inherent, parametric knowledge of large language models (LLMs). It adversely affects performance on downstream tasks such as question answering (QA). Existing approaches often attempt to mitigate conflicts by directly comparing two knowledge sources in a side-by-side manner, but this can overwhelm LLMs with extraneous or lengthy contexts, ultimately hindering their ability to identify and mitigate inconsistencies. To address this issue, we propose Micro-Act a framework with a hierarchical action space that automatically perceives context complexity and adaptively decomposes each knowledge source into a sequence of fine-grained comparisons. These comparisons are represented as actionable steps, enabling reasoning beyond the superficial context. Through extensive experiments on five benchmark datasets, Micro-Act consistently achieves significant increase in QA accuracy over state-of-the-art baselines across all 5 datasets and 3 conflict types, especially in temporal and semantic types where all baselines fail significantly. More importantly, Micro-Act exhibits robust performance on non-conflict questions simultaneously, highlighting its practical value in real-world RAG applications.
Legend: Leveraging Representation Engineering to Annotate Safety Margin for Preference Datasets
Jun 12, 2024

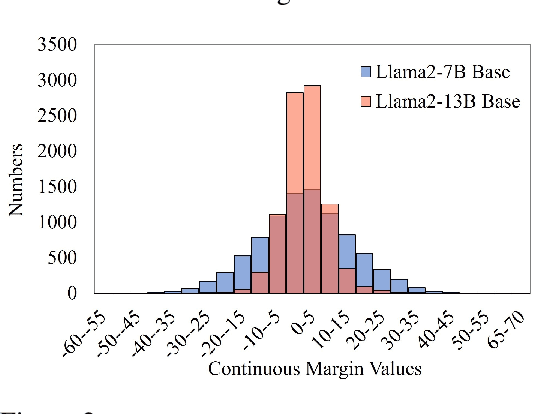

The success of the reward model in distinguishing between responses with subtle safety differences depends critically on the high-quality preference dataset, which should capture the fine-grained nuances of harmful and harmless responses. This motivates the need to develop a dataset involving preference margins, which accurately quantify how harmless one response is compared to another. In this paper, we take the first step to propose an effective and cost-efficient framework to promote the margin-enhanced preference dataset development. Our framework, Legend, Leverages representation engineering to annotate preference datasets. It constructs the specific direction within the LLM's embedding space that represents safety. By leveraging this safety direction, Legend can then leverage the semantic distances of paired responses along this direction to annotate margins automatically. We experimentally demonstrate our effectiveness in both reward modeling and harmless alignment for LLMs. Legend also stands out for its efficiency, requiring only the inference time rather than additional training. This efficiency allows for easier implementation and scalability, making Legend particularly valuable for practical applications in aligning LLMs with safe conversations.
Before Generation, Align it! A Novel and Effective Strategy for Mitigating Hallucinations in Text-to-SQL Generation
May 24, 2024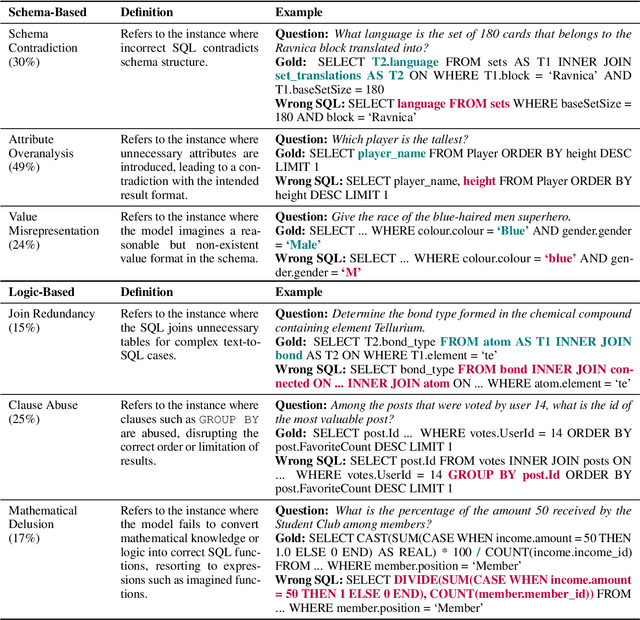
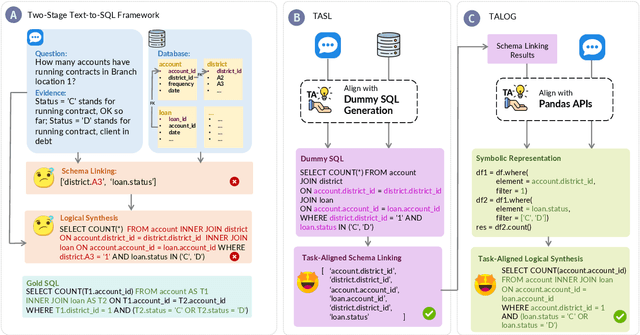
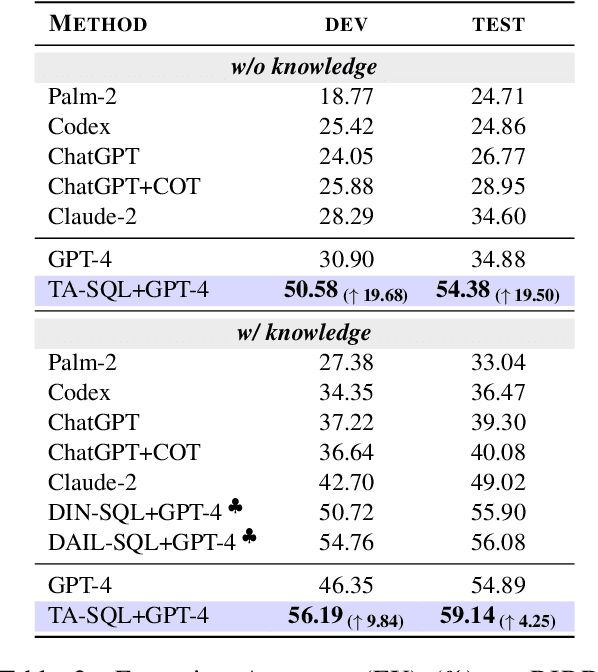
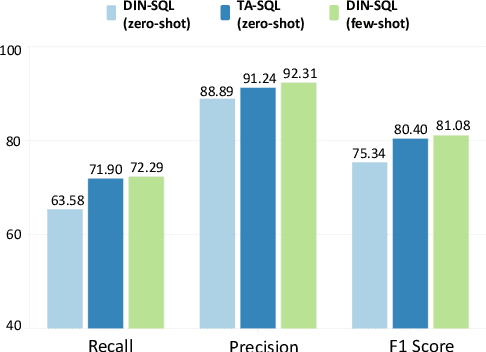
Large Language Models (LLMs) driven by In-Context Learning (ICL) have significantly improved the performance of text-to-SQL. Previous methods generally employ a two-stage reasoning framework, namely 1) schema linking and 2) logical synthesis, making the framework not only effective but also interpretable. Despite these advancements, the inherent bad nature of the generalization of LLMs often results in hallucinations, which limits the full potential of LLMs. In this work, we first identify and categorize the common types of hallucinations at each stage in text-to-SQL. We then introduce a novel strategy, Task Alignment (TA), designed to mitigate hallucinations at each stage. TA encourages LLMs to take advantage of experiences from similar tasks rather than starting the tasks from scratch. This can help LLMs reduce the burden of generalization, thereby mitigating hallucinations effectively. We further propose TA-SQL, a text-to-SQL framework based on this strategy. The experimental results and comprehensive analysis demonstrate the effectiveness and robustness of our framework. Specifically, it enhances the performance of the GPT-4 baseline by 21.23% relatively on BIRD dev and it yields significant improvements across six models and four mainstream, complex text-to-SQL benchmarks.
Towards Understanding the Influence of Reward Margin on Preference Model Performance
Apr 07, 2024



Reinforcement Learning from Human Feedback (RLHF) is a widely used framework for the training of language models. However, the process of using RLHF to develop a language model that is well-aligned presents challenges, especially when it comes to optimizing the reward model. Our research has found that existing reward models, when trained using the traditional ranking objective based on human preference data, often struggle to effectively distinguish between responses that are more or less favorable in real-world scenarios. To bridge this gap, our study introduces a novel method to estimate the preference differences without the need for detailed, exhaustive labels from human annotators. Our experimental results provide empirical evidence that incorporating margin values into the training process significantly improves the effectiveness of reward models. This comparative analysis not only demonstrates the superiority of our approach in terms of reward prediction accuracy but also highlights its effectiveness in practical applications.
Towards Analyzing and Understanding the Limitations of DPO: A Theoretical Perspective
Apr 06, 2024
Direct Preference Optimization (DPO), which derives reward signals directly from pairwise preference data, has shown its effectiveness on aligning Large Language Models (LLMs) with human preferences. Despite its widespread use across various tasks, DPO has been criticized for its sensitivity to the SFT's effectiveness and its hindrance to the learning capacity towards human-preferred responses, leading to less satisfactory performance. To overcome those limitations, the theoretical understanding of DPO are indispensable but still lacking. To this end, we take a step towards theoretically analyzing and understanding the limitations of DPO. Specifically, we provide an analytical framework using the field theory to analyze the optimization process of DPO. By analyzing the gradient vector field of the DPO loss function, we find that the DPO loss function decreases the probability of producing human dispreferred data at a faster rate than it increases the probability of producing preferred data. This provides theoretical insights for understanding the limitations of DPO discovered in the related research experiments, thereby setting the foundation for its improvement.
FLM-101B: An Open LLM and How to Train It with $100K Budget
Sep 17, 2023Large language models (LLMs) have achieved remarkable success in NLP and multimodal tasks, among others. Despite these successes, two main challenges remain in developing LLMs: (i) high computational cost, and (ii) fair and objective evaluations. In this paper, we report a solution to significantly reduce LLM training cost through a growth strategy. We demonstrate that a 101B-parameter LLM with 0.31T tokens can be trained with a budget of 100K US dollars. Inspired by IQ tests, we also consolidate an additional range of evaluations on top of existing evaluations that focus on knowledge-oriented abilities. These IQ evaluations include symbolic mapping, rule understanding, pattern mining, and anti-interference. Such evaluations minimize the potential impact of memorization. Experimental results show that our model, named FLM-101B, trained with a budget of 100K US dollars, achieves performance comparable to powerful and well-known models, e.g., GPT-3 and GLM-130B, especially on the additional range of IQ evaluations. The checkpoint of FLM-101B is released at https://huggingface.co/CofeAI/FLM-101B.
Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs
May 04, 2023



Text-to-SQL parsing, which aims at converting natural language instructions into executable SQLs, has gained increasing attention in recent years. In particular, Codex and ChatGPT have shown impressive results in this task. However, most of the prevalent benchmarks, i.e., Spider, and WikiSQL, focus on database schema with few rows of database contents leaving the gap between academic study and real-world applications. To mitigate this gap, we present Bird, a big benchmark for large-scale database grounded in text-to-SQL tasks, containing 12,751 pairs of text-to-SQL data and 95 databases with a total size of 33.4 GB, spanning 37 professional domains. Our emphasis on database values highlights the new challenges of dirty database contents, external knowledge between NL questions and database contents, and SQL efficiency, particularly in the context of massive databases. To solve these problems, text-to-SQL models must feature database value comprehension in addition to semantic parsing. The experimental results demonstrate the significance of database values in generating accurate text-to-SQLs for big databases. Furthermore, even the most effective text-to-SQL models, i.e. ChatGPT, only achieves 40.08% in execution accuracy, which is still far from the human result of 92.96%, proving that challenges still stand. Besides, we also provide an efficiency analysis to offer insights into generating text-to-efficient-SQLs that are beneficial to industries. We believe that BIRD will contribute to advancing real-world applications of text-to-SQL research. The leaderboard and source code are available: https://bird-bench.github.io/.
Graphix-T5: Mixing Pre-Trained Transformers with Graph-Aware Layers for Text-to-SQL Parsing
Jan 18, 2023



The task of text-to-SQL parsing, which aims at converting natural language questions into executable SQL queries, has garnered increasing attention in recent years, as it can assist end users in efficiently extracting vital information from databases without the need for technical background. One of the major challenges in text-to-SQL parsing is domain generalization, i.e., how to generalize well to unseen databases. Recently, the pre-trained text-to-text transformer model, namely T5, though not specialized for text-to-SQL parsing, has achieved state-of-the-art performance on standard benchmarks targeting domain generalization. In this work, we explore ways to further augment the pre-trained T5 model with specialized components for text-to-SQL parsing. Such components are expected to introduce structural inductive bias into text-to-SQL parsers thus improving model's capacity on (potentially multi-hop) reasoning, which is critical for generating structure-rich SQLs. To this end, we propose a new architecture GRAPHIX-T5, a mixed model with the standard pre-trained transformer model augmented by some specially-designed graph-aware layers. Extensive experiments and analysis demonstrate the effectiveness of GRAPHIX-T5 across four text-to-SQL benchmarks: SPIDER, SYN, REALISTIC and DK. GRAPHIX-T5 surpass all other T5-based parsers with a significant margin, achieving new state-of-the-art performance. Notably, GRAPHIX-T5-large reach performance superior to the original T5-large by 5.7% on exact match (EM) accuracy and 6.6% on execution accuracy (EX). This even outperforms the T5-3B by 1.2% on EM and 1.5% on EX.
SUN: Exploring Intrinsic Uncertainties in Text-to-SQL Parsers
Sep 14, 2022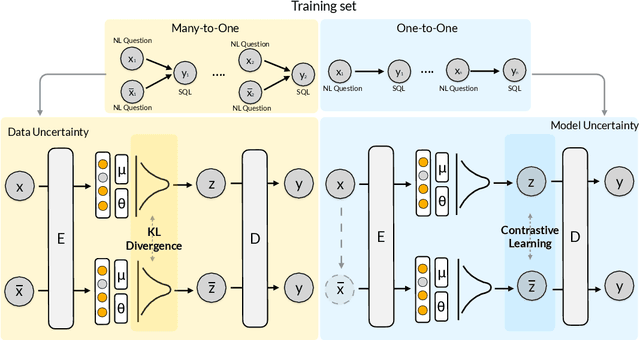
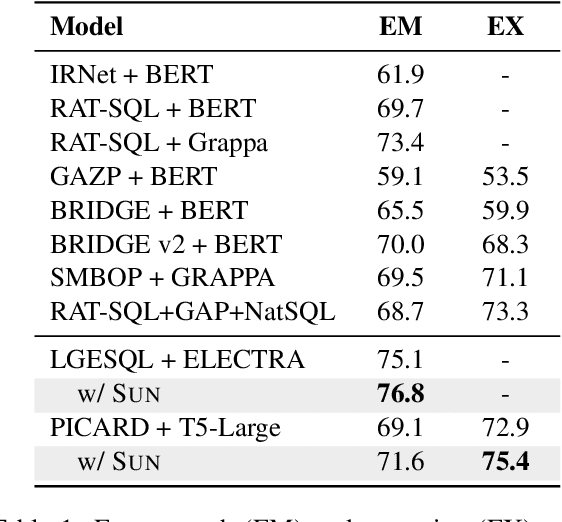
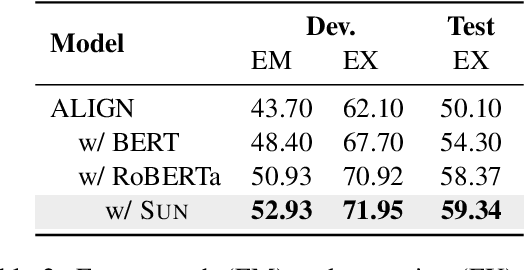
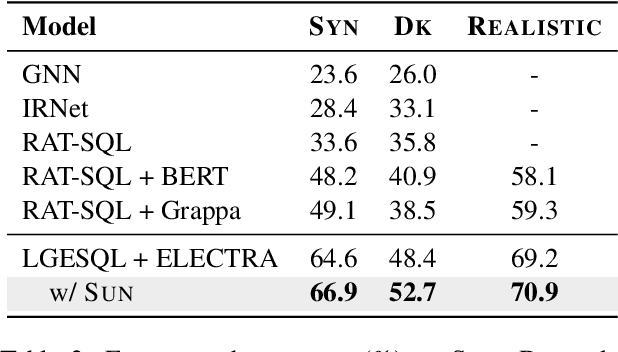
This paper aims to improve the performance of text-to-SQL parsing by exploring the intrinsic uncertainties in the neural network based approaches (called SUN). From the data uncertainty perspective, it is indisputable that a single SQL can be learned from multiple semantically-equivalent questions.Different from previous methods that are limited to one-to-one mapping, we propose a data uncertainty constraint to explore the underlying complementary semantic information among multiple semantically-equivalent questions (many-to-one) and learn the robust feature representations with reduced spurious associations. In this way, we can reduce the sensitivity of the learned representations and improve the robustness of the parser. From the model uncertainty perspective, there is often structural information (dependence) among the weights of neural networks. To improve the generalizability and stability of neural text-to-SQL parsers, we propose a model uncertainty constraint to refine the query representations by enforcing the output representations of different perturbed encoding networks to be consistent with each other. Extensive experiments on five benchmark datasets demonstrate that our method significantly outperforms strong competitors and achieves new state-of-the-art results. For reproducibility, we release our code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/sunsql.