 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBirth-death dynamics for sampling: Global convergence, approximations and their asymptotics
Nov 01, 2022Motivated by the challenge of sampling Gibbs measures with nonconvex potentials, we study a continuum birth-death dynamics. We prove that the probability density of the birth-death governed by Kullback-Leibler divergence or by $\chi^2$ divergence converge exponentially fast to the Gibbs equilibrium measure with a universal rate that is independent of the potential barrier. To build a practical numerical sampler based on the pure birth-death dynamics, we consider an interacting particle system which relies on kernel-based approximations of the measure and retains the gradient-flow structure. We show on the torus that the kernelized dynamics $\Gamma$-converges, on finite time intervals, to the pure birth-death dynamics as the kernel bandwidth shrinks to zero. Moreover we provide quantitative estimates on the bias of minimizers of the energy corresponding to the kernalized dynamics. Finally we prove the long-time asymptotic results on the convergence of the asymptotic states of the kernalized dynamics towards the Gibbs measure.
SUN: Exploring Intrinsic Uncertainties in Text-to-SQL Parsers
Sep 14, 2022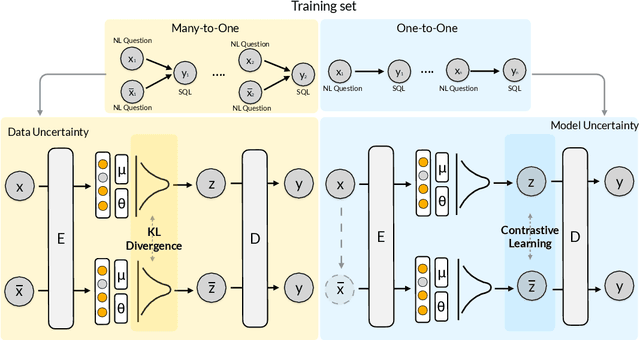
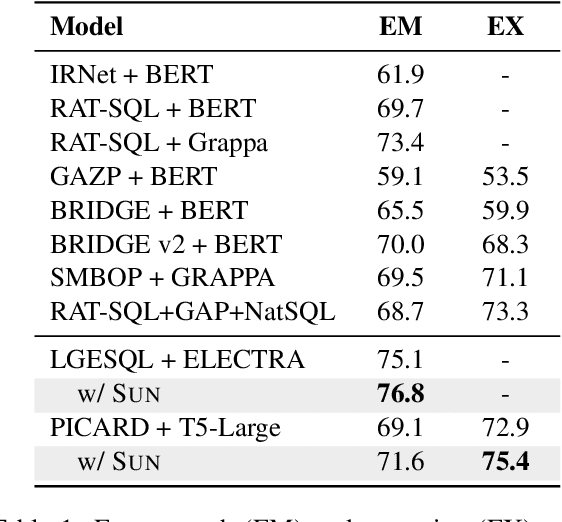
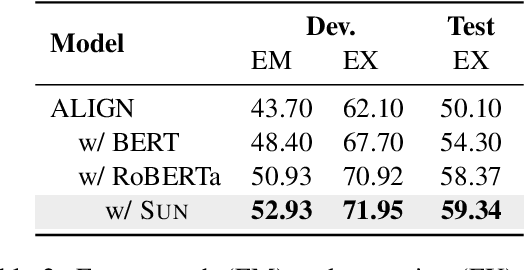
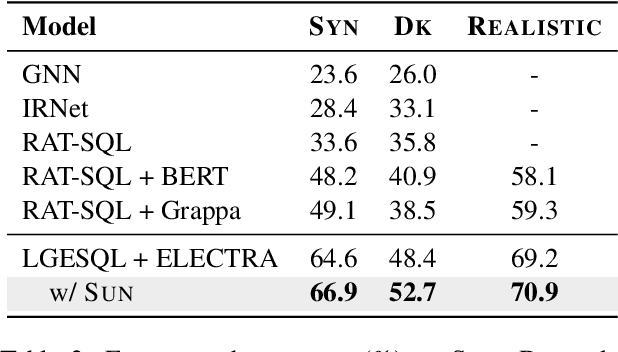
This paper aims to improve the performance of text-to-SQL parsing by exploring the intrinsic uncertainties in the neural network based approaches (called SUN). From the data uncertainty perspective, it is indisputable that a single SQL can be learned from multiple semantically-equivalent questions.Different from previous methods that are limited to one-to-one mapping, we propose a data uncertainty constraint to explore the underlying complementary semantic information among multiple semantically-equivalent questions (many-to-one) and learn the robust feature representations with reduced spurious associations. In this way, we can reduce the sensitivity of the learned representations and improve the robustness of the parser. From the model uncertainty perspective, there is often structural information (dependence) among the weights of neural networks. To improve the generalizability and stability of neural text-to-SQL parsers, we propose a model uncertainty constraint to refine the query representations by enforcing the output representations of different perturbed encoding networks to be consistent with each other. Extensive experiments on five benchmark datasets demonstrate that our method significantly outperforms strong competitors and achieves new state-of-the-art results. For reproducibility, we release our code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/sunsql.
A Survey on Text-to-SQL Parsing: Concepts, Methods, and Future Directions
Aug 29, 2022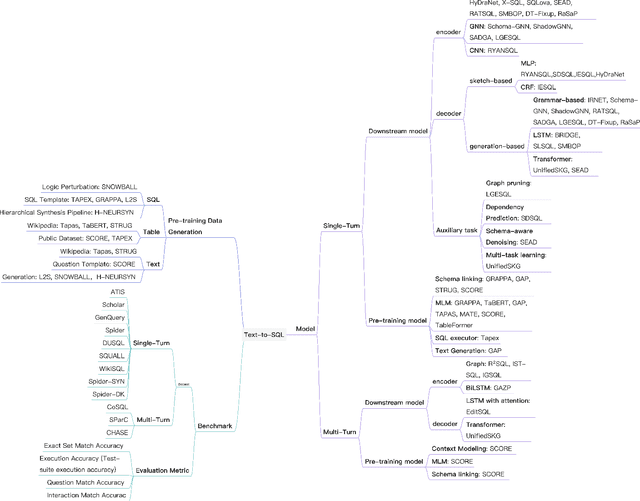


Text-to-SQL parsing is an essential and challenging task. The goal of text-to-SQL parsing is to convert a natural language (NL) question to its corresponding structured query language (SQL) based on the evidences provided by relational databases. Early text-to-SQL parsing systems from the database community achieved a noticeable progress with the cost of heavy human engineering and user interactions with the systems. In recent years, deep neural networks have significantly advanced this task by neural generation models, which automatically learn a mapping function from an input NL question to an output SQL query. Subsequently, the large pre-trained language models have taken the state-of-the-art of the text-to-SQL parsing task to a new level. In this survey, we present a comprehensive review on deep learning approaches for text-to-SQL parsing. First, we introduce the text-to-SQL parsing corpora which can be categorized as single-turn and multi-turn. Second, we provide a systematical overview of pre-trained language models and existing methods for text-to-SQL parsing. Third, we present readers with the challenges faced by text-to-SQL parsing and explore some potential future directions in this field.
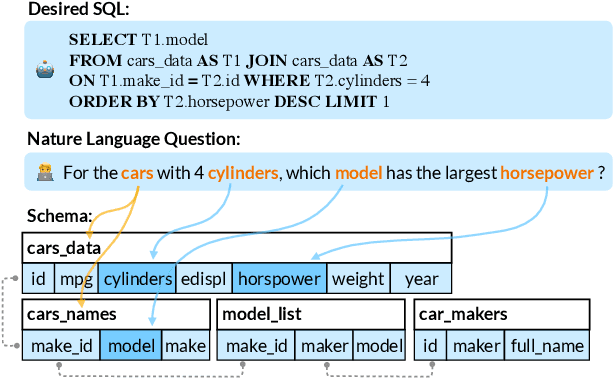
Proton: Probing Schema Linking Information from Pre-trained Language Models for Text-to-SQL Parsing
Jun 28, 2022
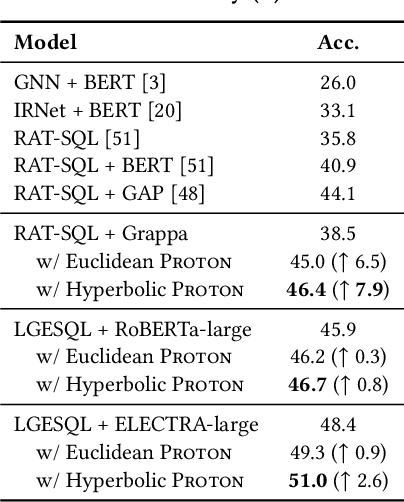
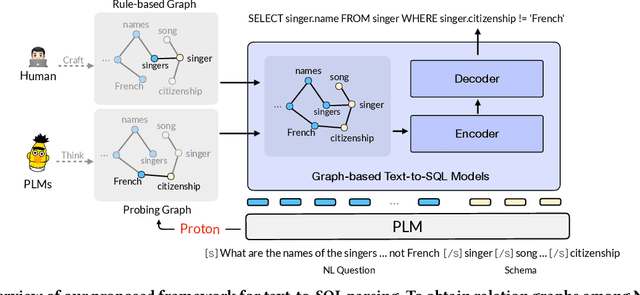
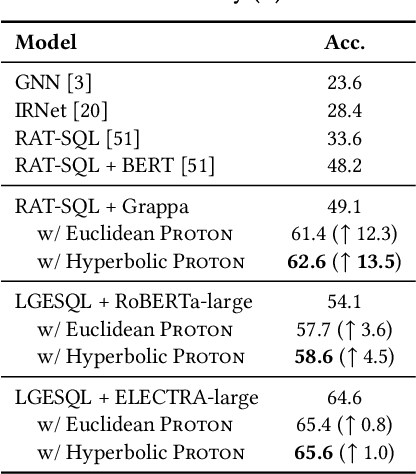
The importance of building text-to-SQL parsers which can be applied to new databases has long been acknowledged, and a critical step to achieve this goal is schema linking, i.e., properly recognizing mentions of unseen columns or tables when generating SQLs. In this work, we propose a novel framework to elicit relational structures from large-scale pre-trained language models (PLMs) via a probing procedure based on Poincar\'e distance metric, and use the induced relations to augment current graph-based parsers for better schema linking. Compared with commonly-used rule-based methods for schema linking, we found that probing relations can robustly capture semantic correspondences, even when surface forms of mentions and entities differ. Moreover, our probing procedure is entirely unsupervised and requires no additional parameters. Extensive experiments show that our framework sets new state-of-the-art performance on three benchmarks. We empirically verify that our probing procedure can indeed find desired relational structures through qualitative analysis.
S$^2$SQL: Injecting Syntax to Question-Schema Interaction Graph Encoder for Text-to-SQL Parsers
Mar 14, 2022
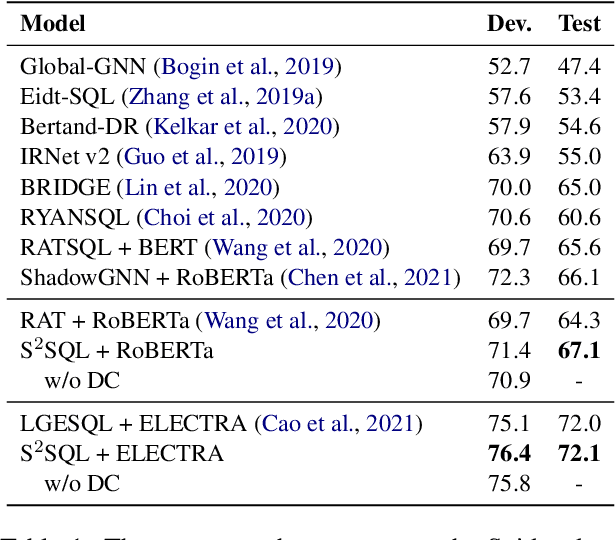
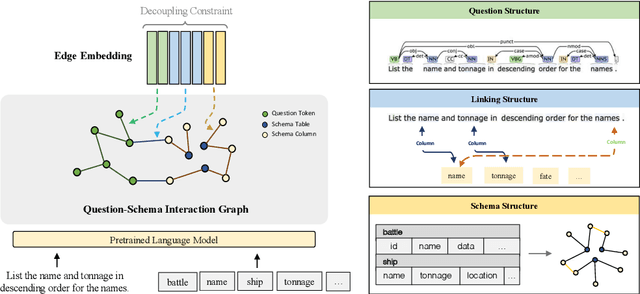

The task of converting a natural language question into an executable SQL query, known as text-to-SQL, is an important branch of semantic parsing. The state-of-the-art graph-based encoder has been successfully used in this task but does not model the question syntax well. In this paper, we propose S$^2$SQL, injecting Syntax to question-Schema graph encoder for Text-to-SQL parsers, which effectively leverages the syntactic dependency information of questions in text-to-SQL to improve the performance. We also employ the decoupling constraint to induce diverse relational edge embedding, which further improves the network's performance. Experiments on the Spider and robustness setting Spider-Syn demonstrate that the proposed approach outperforms all existing methods when pre-training models are used, resulting in a performance ranks first on the Spider leaderboard.
SDCUP: Schema Dependency-Enhanced Curriculum Pre-Training for Table Semantic Parsing
Nov 18, 2021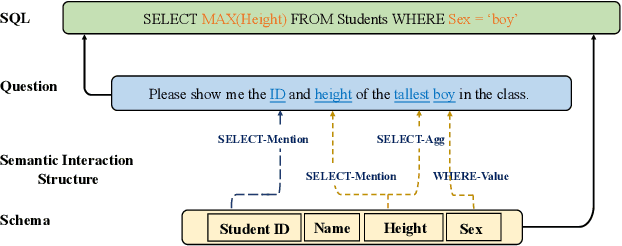
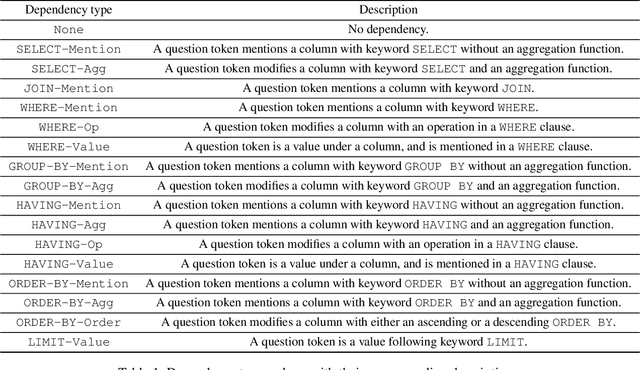
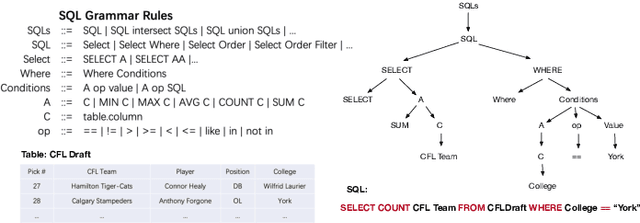

Recently pre-training models have significantly improved the performance of various NLP tasks by leveraging large-scale text corpora to improve the contextual representation ability of the neural network. The large pre-training language model has also been applied in the area of table semantic parsing. However, existing pre-training approaches have not carefully explored explicit interaction relationships between a question and the corresponding database schema, which is a key ingredient for uncovering their semantic and structural correspondence. Furthermore, the question-aware representation learning in the schema grounding context has received less attention in pre-training objective.To alleviate these issues, this paper designs two novel pre-training objectives to impose the desired inductive bias into the learned representations for table pre-training. We further propose a schema-aware curriculum learning approach to mitigate the impact of noise and learn effectively from the pre-training data in an easy-to-hard manner. We evaluate our pre-trained framework by fine-tuning it on two benchmarks, Spider and SQUALL. The results demonstrate the effectiveness of our pre-training objective and curriculum compared to a variety of baselines.
Complexity of zigzag sampling algorithm for strongly log-concave distributions
Dec 21, 2020We study the computational complexity of zigzag sampling algorithm for strongly log-concave distributions. The zigzag process has the advantage of not requiring time discretization for implementation, and that each proposed bouncing event requires only one evaluation of partial derivative of the potential, while its convergence rate is dimension independent. Using these properties, we prove that the zigzag sampling algorithm achieves $\varepsilon$ error in chi-square divergence with a computational cost equivalent to $O\bigl(\kappa^2 d^\frac{1}{2}(\log\frac{1}{\varepsilon})^{\frac{3}{2}}\bigr)$ gradient evaluations in the regime $\kappa \ll \frac{d}{\log d}$ under a warm start assumption, where $\kappa$ is the condition number and $d$ is the dimension.