 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDCUP: Schema Dependency-Enhanced Curriculum Pre-Training for Table Semantic Parsing
Paper and Code
Nov 18, 2021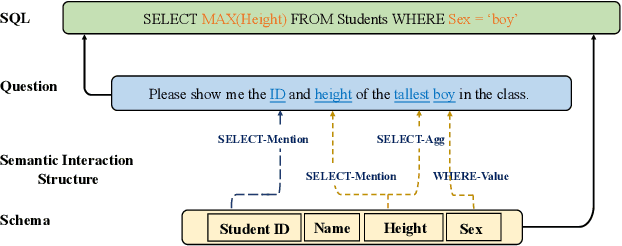
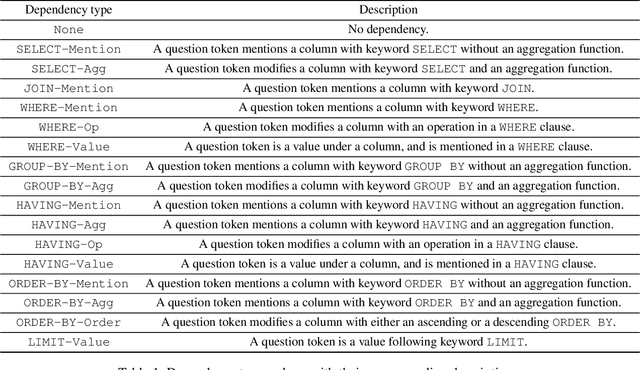
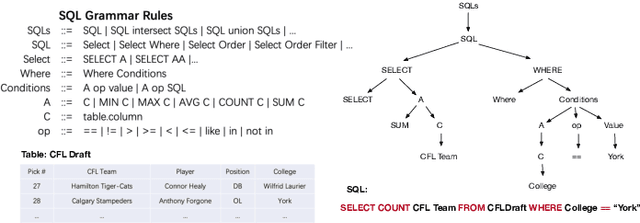

Recently pre-training models have significantly improved the performance of various NLP tasks by leveraging large-scale text corpora to improve the contextual representation ability of the neural network. The large pre-training language model has also been applied in the area of table semantic parsing. However, existing pre-training approaches have not carefully explored explicit interaction relationships between a question and the corresponding database schema, which is a key ingredient for uncovering their semantic and structural correspondence. Furthermore, the question-aware representation learning in the schema grounding context has received less attention in pre-training objective.To alleviate these issues, this paper designs two novel pre-training objectives to impose the desired inductive bias into the learned representations for table pre-training. We further propose a schema-aware curriculum learning approach to mitigate the impact of noise and learn effectively from the pre-training data in an easy-to-hard manner. We evaluate our pre-trained framework by fine-tuning it on two benchmarks, Spider and SQUALL. The results demonstrate the effectiveness of our pre-training objective and curriculum compared to a variety of baselines.