 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory of Diversity for Random Matrices with Applications to In-Context Learning of Schrödinger Equations
Jan 18, 2026We address the following question: given a collection $\{\mathbf{A}^{(1)}, \dots, \mathbf{A}^{(N)}\}$ of independent $d \times d$ random matrices drawn from a common distribution $\mathbb{P}$, what is the probability that the centralizer of $\{\mathbf{A}^{(1)}, \dots, \mathbf{A}^{(N)}\}$ is trivial? We provide lower bounds on this probability in terms of the sample size $N$ and the dimension $d$ for several families of random matrices which arise from the discretization of linear Schrödinger operators with random potentials. When combined with recent work on machine learning theory, our results provide guarantees on the generalization ability of transformer-based neural networks for in-context learning of Schrödinger equations.
In-Context Operator Learning on the Space of Probability Measures
Jan 15, 2026We introduce \emph{in-context operator learning on probability measure spaces} for optimal transport (OT). The goal is to learn a single solution operator that maps a pair of distributions to the OT map, using only few-shot samples from each distribution as a prompt and \emph{without} gradient updates at inference. We parameterize the solution operator and develop scaling-law theory in two regimes. In the \emph{nonparametric} setting, when tasks concentrate on a low-intrinsic-dimension manifold of source--target pairs, we establish generalization bounds that quantify how in-context accuracy scales with prompt size, intrinsic task dimension, and model capacity. In the \emph{parametric} setting (e.g., Gaussian families), we give an explicit architecture that recovers the exact OT map in context and provide finite-sample excess-risk bounds. Our numerical experiments on synthetic transports and generative-modeling benchmarks validate the framework.
On the Dimension-Free Approximation of Deep Neural Networks for Symmetric Korobov Functions
Nov 16, 2025
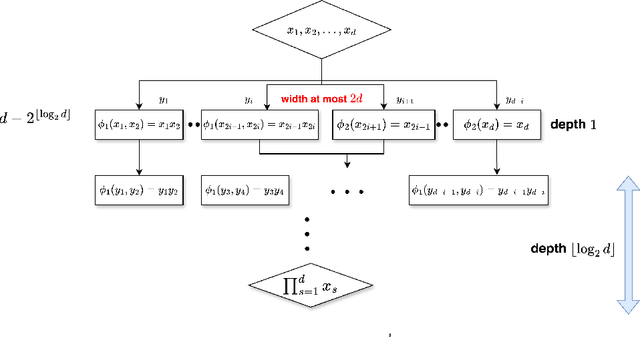
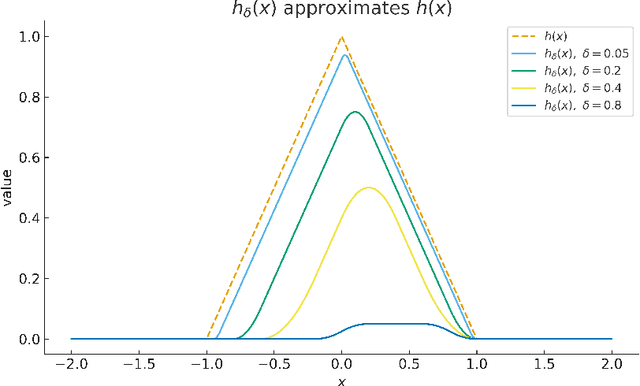
Deep neural networks have been widely used as universal approximators for functions with inherent physical structures, including permutation symmetry. In this paper, we construct symmetric deep neural networks to approximate symmetric Korobov functions and prove that both the convergence rate and the constant prefactor scale at most polynomially with respect to the ambient dimension. This represents a substantial improvement over prior approximation guarantees that suffer from the curse of dimensionality. Building on these approximation bounds, we further derive a generalization-error rate for learning symmetric Korobov functions whose leading factors likewise avoid the curse of dimensionality.
Convergence of Time-Averaged Mean Field Gradient Descent Dynamics for Continuous Multi-Player Zero-Sum Games
May 12, 2025The approximation of mixed Nash equilibria (MNE) for zero-sum games with mean-field interacting players has recently raised much interest in machine learning. In this paper we propose a mean-field gradient descent dynamics for finding the MNE of zero-sum games involving $K$ players with $K\geq 2$. The evolution of the players' strategy distributions follows coupled mean-field gradient descent flows with momentum, incorporating an exponentially discounted time-averaging of gradients. First, in the case of a fixed entropic regularization, we prove an exponential convergence rate for the mean-field dynamics to the mixed Nash equilibrium with respect to the total variation metric. This improves a previous polynomial convergence rate for a similar time-averaged dynamics with different averaging factors. Moreover, unlike previous two-scale approaches for finding the MNE, our approach treats all player types on the same time scale. We also show that with a suitable choice of decreasing temperature, a simulated annealing version of the mean-field dynamics converges to an MNE of the initial unregularized problem.
In-Context Learning of Linear Dynamical Systems with Transformers: Error Bounds and Depth-Separation
Feb 12, 2025This paper investigates approximation-theoretic aspects of the in-context learning capability of the transformers in representing a family of noisy linear dynamical systems. Our first theoretical result establishes an upper bound on the approximation error of multi-layer transformers with respect to an $L^2$-testing loss uniformly defined across tasks. This result demonstrates that transformers with logarithmic depth can achieve error bounds comparable with those of the least-squares estimator. In contrast, our second result establishes a non-diminishing lower bound on the approximation error for a class of single-layer linear transformers, which suggests a depth-separation phenomenon for transformers in the in-context learning of dynamical systems. Moreover, this second result uncovers a critical distinction in the approximation power of single-layer linear transformers when learning from IID versus non-IID data.
Score-based generative models break the curse of dimensionality in learning a family of sub-Gaussian probability distributions
Feb 23, 2024While score-based generative models (SGMs) have achieved remarkable success in enormous image generation tasks, their mathematical foundations are still limited. In this paper, we analyze the approximation and generalization of SGMs in learning a family of sub-Gaussian probability distributions. We introduce a notion of complexity for probability distributions in terms of their relative density with respect to the standard Gaussian measure. We prove that if the log-relative density can be locally approximated by a neural network whose parameters can be suitably bounded, then the distribution generated by empirical score matching approximates the target distribution in total variation with a dimension-independent rate. We illustrate our theory through examples, which include certain mixtures of Gaussians. An essential ingredient of our proof is to derive a dimension-free deep neural network approximation rate for the true score function associated with the forward process, which is interesting in its own right.
Optimal Deep Neural Network Approximation for Korobov Functions with respect to Sobolev Norms
Nov 08, 2023

This paper establishes the nearly optimal rate of approximation for deep neural networks (DNNs) when applied to Korobov functions, effectively overcoming the curse of dimensionality. The approximation results presented in this paper are measured with respect to $L_p$ norms and $H^1$ norms. Our achieved approximation rate demonstrates a remarkable "super-convergence" rate, outperforming traditional methods and any continuous function approximator. These results are non-asymptotic, providing error bounds that consider both the width and depth of the networks simultaneously.
Two-Scale Gradient Descent Ascent Dynamics Finds Mixed Nash Equilibria of Continuous Games: A Mean-Field Perspective
Jan 08, 2023Finding the mixed Nash equilibria (MNE) of a two-player zero sum continuous game is an important and challenging problem in machine learning. A canonical algorithm to finding the MNE is the noisy gradient descent ascent method which in the infinite particle limit gives rise to the {\em Mean-Field Gradient Descent Ascent} (GDA) dynamics on the space of probability measures. In this paper, we first study the convergence of a two-scale Mean-Field GDA dynamics for finding the MNE of the entropy-regularized objective. More precisely we show that for each finite temperature (or regularization parameter), the two-scale Mean-Field GDA with a suitable {\em finite} scale ratio converges exponentially to the unique MNE without assuming the convexity or concavity of the interaction potential. The key ingredient of our proof lies in the construction of new Lyapunov functions that dissipate exponentially along the Mean-Field GDA. We further study the simulated annealing of the Mean-Field GDA dynamics. We show that with a temperature schedule that decays logarithmically in time the annealed Mean-Field GDA converges to the MNE of the original unregularized objective.
Transfer Learning Enhanced DeepONet for Long-Time Prediction of Evolution Equations
Dec 09, 2022



Deep operator network (DeepONet) has demonstrated great success in various learning tasks, including learning solution operators of partial differential equations. In particular, it provides an efficient approach to predict the evolution equations in a finite time horizon. Nevertheless, the vanilla DeepONet suffers from the issue of stability degradation in the long-time prediction. This paper proposes a {\em transfer-learning} aided DeepONet to enhance the stability. Our idea is to use transfer learning to sequentially update the DeepONets as the surrogates for propagators learned in different time frames. The evolving DeepONets can better track the varying complexities of the evolution equations, while only need to be updated by efficient training of a tiny fraction of the operator networks. Through systematic experiments, we show that the proposed method not only improves the long-time accuracy of DeepONet while maintaining similar computational cost but also substantially reduces the sample size of the training set.
Birth-death dynamics for sampling: Global convergence, approximations and their asymptotics
Nov 01, 2022Motivated by the challenge of sampling Gibbs measures with nonconvex potentials, we study a continuum birth-death dynamics. We prove that the probability density of the birth-death governed by Kullback-Leibler divergence or by $\chi^2$ divergence converge exponentially fast to the Gibbs equilibrium measure with a universal rate that is independent of the potential barrier. To build a practical numerical sampler based on the pure birth-death dynamics, we consider an interacting particle system which relies on kernel-based approximations of the measure and retains the gradient-flow structure. We show on the torus that the kernelized dynamics $\Gamma$-converges, on finite time intervals, to the pure birth-death dynamics as the kernel bandwidth shrinks to zero. Moreover we provide quantitative estimates on the bias of minimizers of the energy corresponding to the kernalized dynamics. Finally we prove the long-time asymptotic results on the convergence of the asymptotic states of the kernalized dynamics towards the Gibbs measure.