 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhance Graph Alignment for Large Language Models
Oct 15, 2024



Graph-structured data is prevalent in the real world. Recently, due to the powerful emergent capabilities, Large Language Models (LLMs) have shown promising performance in modeling graphs. The key to effectively applying LLMs on graphs is converting graph data into a format LLMs can comprehend. Graph-to-token approaches are popular in enabling LLMs to process graph information. They transform graphs into sequences of tokens and align them with text tokens through instruction tuning, where self-supervised instruction tuning helps LLMs acquire general knowledge about graphs, and supervised fine-tuning specializes LLMs for the downstream tasks on graphs. Despite their initial success, we find that existing methods have a misalignment between self-supervised tasks and supervised downstream tasks, resulting in negative transfer from self-supervised fine-tuning to downstream tasks. To address these issues, we propose Graph Alignment Large Language Models (GALLM) to benefit from aligned task templates. In the self-supervised tuning stage, we introduce a novel text matching task using templates aligned with downstream tasks. In the task-specific tuning stage, we propose two category prompt methods that learn supervision information from additional explanation with further aligned templates. Experimental evaluations on four datasets demonstrate substantial improvements in supervised learning, multi-dataset generalizability, and particularly in zero-shot capability, highlighting the model's potential as a graph foundation model.
Sketch: A Toolkit for Streamlining LLM Operations
Sep 05, 2024



Large language models (LLMs) represented by GPT family have achieved remarkable success. The characteristics of LLMs lie in their ability to accommodate a wide range of tasks through a generative approach. However, the flexibility of their output format poses challenges in controlling and harnessing the model's outputs, thereby constraining the application of LLMs in various domains. In this work, we present Sketch, an innovative toolkit designed to streamline LLM operations across diverse fields. Sketch comprises the following components: (1) a suite of task description schemas and prompt templates encompassing various NLP tasks; (2) a user-friendly, interactive process for building structured output LLM services tailored to various NLP tasks; (3) an open-source dataset for output format control, along with tools for dataset construction; and (4) an open-source model based on LLaMA3-8B-Instruct that adeptly comprehends and adheres to output formatting instructions. We anticipate this initiative to bring considerable convenience to LLM users, achieving the goal of ''plug-and-play'' for various applications. The components of Sketch will be progressively open-sourced at https://github.com/cofe-ai/Sketch.
Open-domain Implicit Format Control for Large Language Model Generation
Aug 08, 2024
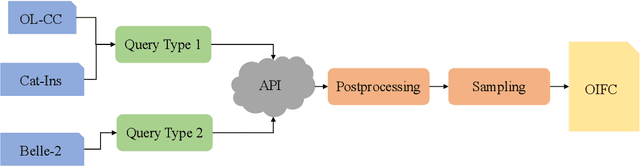
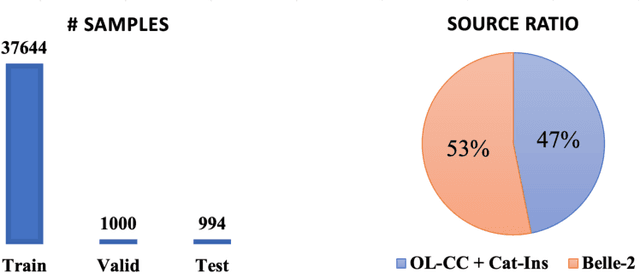

Controlling the format of outputs generated by large language models (LLMs) is a critical functionality in various applications. Current methods typically employ constrained decoding with rule-based automata or fine-tuning with manually crafted format instructions, both of which struggle with open-domain format requirements. To address this limitation, we introduce a novel framework for controlled generation in LLMs, leveraging user-provided, one-shot QA pairs. This study investigates LLMs' capabilities to follow open-domain, one-shot constraints and replicate the format of the example answers. We observe that this is a non-trivial problem for current LLMs. We also develop a dataset collection methodology for supervised fine-tuning that enhances the open-domain format control of LLMs without degrading output quality, as well as a benchmark on which we evaluate both the helpfulness and format correctness of LLM outputs. The resulting datasets, named OIFC-SFT, along with the related code, will be made publicly available at https://github.com/cofe-ai/OIFC.
Not all Layers of LLMs are Necessary during Inference
Mar 04, 2024
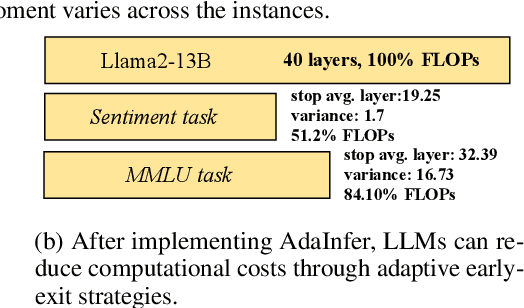
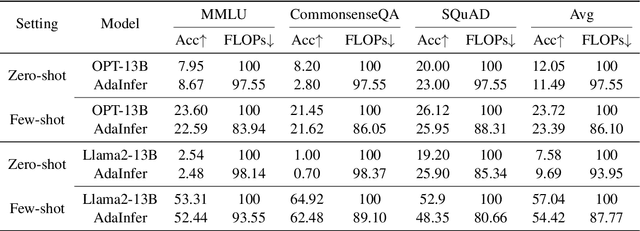
The inference phase of Large Language Models (LLMs) is very expensive. An ideal inference stage of LLMs could utilize fewer computational resources while still maintaining its capabilities (e.g., generalization and in-context learning ability). In this paper, we try to answer the question, "During LLM inference, can we use shallow layers for easy instances; and deep layers for hard ones?" To answer this question, we first indicate that Not all Layers are Necessary during Inference by statistically analyzing the activated layers across tasks. Then, we propose a simple algorithm named AdaInfer to determine the inference termination moment based on the input instance adaptively. More importantly, AdaInfer does not alter LLM parameters and maintains generalizability across tasks. Experiments on well-known LLMs (i.e., Llama2 series and OPT) show that AdaInfer saves an average of 14.8% of computational resources, even up to 50% on sentiment tasks, while maintaining comparable performance. Additionally, this method is orthogonal to other model acceleration techniques, potentially boosting inference efficiency further.
Spectral-based Graph Neural Networks for Complementary Item Recommendation
Jan 11, 2024



Modeling complementary relationships greatly helps recommender systems to accurately and promptly recommend the subsequent items when one item is purchased. Unlike traditional similar relationships, items with complementary relationships may be purchased successively (such as iPhone and Airpods Pro), and they not only share relevance but also exhibit dissimilarity. Since the two attributes are opposites, modeling complementary relationships is challenging. Previous attempts to exploit these relationships have either ignored or oversimplified the dissimilarity attribute, resulting in ineffective modeling and an inability to balance the two attributes. Since Graph Neural Networks (GNNs) can capture the relevance and dissimilarity between nodes in the spectral domain, we can leverage spectral-based GNNs to effectively understand and model complementary relationships. In this study, we present a novel approach called Spectral-based Complementary Graph Neural Networks (SComGNN) that utilizes the spectral properties of complementary item graphs. We make the first observation that complementary relationships consist of low-frequency and mid-frequency components, corresponding to the relevance and dissimilarity attributes, respectively. Based on this spectral observation, we design spectral graph convolutional networks with low-pass and mid-pass filters to capture the low-frequency and mid-frequency components. Additionally, we propose a two-stage attention mechanism to adaptively integrate and balance the two attributes. Experimental results on four e-commerce datasets demonstrate the effectiveness of our model, with SComGNN significantly outperforming existing baseline models.
Self-supervised Multi-view Clustering in Computer Vision: A Survey
Sep 18, 2023



Multi-view clustering (MVC) has had significant implications in cross-modal representation learning and data-driven decision-making in recent years. It accomplishes this by leveraging the consistency and complementary information among multiple views to cluster samples into distinct groups. However, as contrastive learning continues to evolve within the field of computer vision, self-supervised learning has also made substantial research progress and is progressively becoming dominant in MVC methods. It guides the clustering process by designing proxy tasks to mine the representation of image and video data itself as supervisory information. Despite the rapid development of self-supervised MVC, there has yet to be a comprehensive survey to analyze and summarize the current state of research progress. Therefore, this paper explores the reasons and advantages of the emergence of self-supervised MVC and discusses the internal connections and classifications of common datasets, data issues, representation learning methods, and self-supervised learning methods. This paper does not only introduce the mechanisms for each category of methods but also gives a few examples of how these techniques are used. In the end, some open problems are pointed out for further investigation and development.
FLM-101B: An Open LLM and How to Train It with $100K Budget
Sep 17, 2023Large language models (LLMs) have achieved remarkable success in NLP and multimodal tasks, among others. Despite these successes, two main challenges remain in developing LLMs: (i) high computational cost, and (ii) fair and objective evaluations. In this paper, we report a solution to significantly reduce LLM training cost through a growth strategy. We demonstrate that a 101B-parameter LLM with 0.31T tokens can be trained with a budget of 100K US dollars. Inspired by IQ tests, we also consolidate an additional range of evaluations on top of existing evaluations that focus on knowledge-oriented abilities. These IQ evaluations include symbolic mapping, rule understanding, pattern mining, and anti-interference. Such evaluations minimize the potential impact of memorization. Experimental results show that our model, named FLM-101B, trained with a budget of 100K US dollars, achieves performance comparable to powerful and well-known models, e.g., GPT-3 and GLM-130B, especially on the additional range of IQ evaluations. The checkpoint of FLM-101B is released at https://huggingface.co/CofeAI/FLM-101B.
FreeLM: Fine-Tuning-Free Language Model
May 02, 2023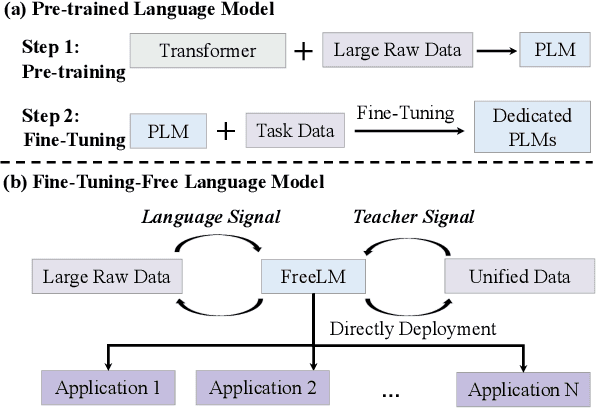
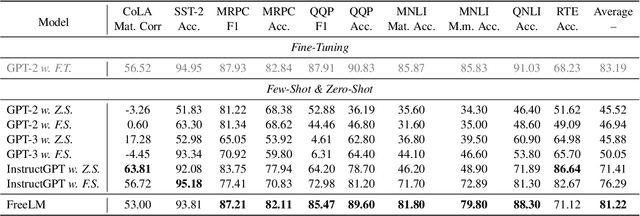
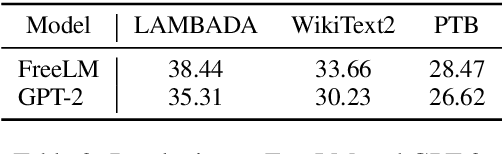
Pre-trained language models (PLMs) have achieved remarkable success in NLP tasks. Despite the great success, mainstream solutions largely follow the pre-training then finetuning paradigm, which brings in both high deployment costs and low training efficiency. Nevertheless, fine-tuning on a specific task is essential because PLMs are only pre-trained with language signal from large raw data. In this paper, we propose a novel fine-tuning-free strategy for language models, to consider both language signal and teacher signal. Teacher signal is an abstraction of a battery of downstream tasks, provided in a unified proposition format. Trained with both language and strong task-aware teacher signals in an interactive manner, our FreeLM model demonstrates strong generalization and robustness. FreeLM outperforms large models e.g., GPT-3 and InstructGPT, on a range of language understanding tasks in experiments. FreeLM is much smaller with 0.3B parameters, compared to 175B in these models.
NetGPT: Generative Pretrained Transformer for Network Traffic
Apr 19, 2023



Pretrained models for network traffic can utilize large-scale raw data to learn the essential characteristics of network traffic, and generate distinguishable results for input traffic without considering specific downstream tasks. Effective pretrained models can significantly optimize the training efficiency and effectiveness of downstream tasks, such as traffic classification, attack detection, resource scheduling, protocol analysis, and traffic generation. Despite the great success of pretraining in natural language processing, there is no work in the network field. Considering the diverse demands and characteristics of network traffic and network tasks, it is non-trivial to build a pretrained model for network traffic and we face various challenges, especially the heterogeneous headers and payloads in the multi-pattern network traffic and the different dependencies for contexts of diverse downstream network tasks. To tackle these challenges, in this paper, we make the first attempt to provide a generative pretrained model for both traffic understanding and generation tasks. We propose the multi-pattern network traffic modeling to construct unified text inputs and support both traffic understanding and generation tasks. We further optimize the adaptation effect of the pretrained model to diversified tasks by shuffling header fields, segmenting packets in flows, and incorporating diverse task labels with prompts. Expensive experiments demonstrate the effectiveness of our NetGPT in a range of traffic understanding and generation tasks, and outperform state-of-the-art baselines by a wide margin.
GCRE-GPT: A Generative Model for Comparative Relation Extraction
Mar 15, 2023Given comparative text, comparative relation extraction aims to extract two targets (\eg two cameras) in comparison and the aspect they are compared for (\eg image quality). The extracted comparative relations form the basis of further opinion analysis.Existing solutions formulate this task as a sequence labeling task, to extract targets and aspects. However, they cannot directly extract comparative relation(s) from text. In this paper, we show that comparative relations can be directly extracted with high accuracy, by generative model. Based on GPT-2, we propose a Generation-based Comparative Relation Extractor (GCRE-GPT). Experiment results show that \modelname achieves state-of-the-art accuracy on two datasets.