 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccommodate Knowledge Conflicts in Retrieval-augmented LLMs: Towards Reliable Response Generation in the Wild
Apr 17, 2025The proliferation of large language models (LLMs) has significantly advanced information retrieval systems, particularly in response generation (RG). Unfortunately, LLMs often face knowledge conflicts between internal memory and retrievaled external information, arising from misinformation, biases, or outdated knowledge. These conflicts undermine response reliability and introduce uncertainty in decision-making. In this work, we analyze how LLMs navigate knowledge conflicts from an information-theoretic perspective and reveal that when conflicting and supplementary information exhibit significant differences, LLMs confidently resolve their preferences. However, when the distinction is ambiguous, LLMs experience heightened uncertainty. Based on this insight, we propose Swin-VIB, a novel framework that integrates a pipeline of variational information bottleneck models into adaptive augmentation of retrieved information and guiding LLM preference in response generation. Extensive experiments on single-choice, open-ended question-answering (QA), and retrieval augmented generation (RAG) validate our theoretical findings and demonstrate the efficacy of Swin-VIB. Notably, our method improves single-choice task accuracy by at least 7.54\% over competitive baselines.
Towards Generalized Multi-stage Clustering: Multi-view Self-distillation
Oct 29, 2023Existing multi-stage clustering methods independently learn the salient features from multiple views and then perform the clustering task. Particularly, multi-view clustering (MVC) has attracted a lot of attention in multi-view or multi-modal scenarios. MVC aims at exploring common semantics and pseudo-labels from multiple views and clustering in a self-supervised manner. However, limited by noisy data and inadequate feature learning, such a clustering paradigm generates overconfident pseudo-labels that mis-guide the model to produce inaccurate predictions. Therefore, it is desirable to have a method that can correct this pseudo-label mistraction in multi-stage clustering to avoid the bias accumulation. To alleviate the effect of overconfident pseudo-labels and improve the generalization ability of the model, this paper proposes a novel multi-stage deep MVC framework where multi-view self-distillation (DistilMVC) is introduced to distill dark knowledge of label distribution. Specifically, in the feature subspace at different hierarchies, we explore the common semantics of multiple views through contrastive learning and obtain pseudo-labels by maximizing the mutual information between views. Additionally, a teacher network is responsible for distilling pseudo-labels into dark knowledge, supervising the student network and improving its predictive capabilities to enhance the robustness. Extensive experiments on real-world multi-view datasets show that our method has better clustering performance than state-of-the-art methods.
Hierarchical Mutual Information Analysis: Towards Multi-view Clustering in The Wild
Oct 28, 2023Multi-view clustering (MVC) can explore common semantics from unsupervised views generated by different sources, and thus has been extensively used in applications of practical computer vision. Due to the spatio-temporal asynchronism, multi-view data often suffer from view missing and are unaligned in real-world applications, which makes it difficult to learn consistent representations. To address the above issues, this work proposes a deep MVC framework where data recovery and alignment are fused in a hierarchically consistent way to maximize the mutual information among different views and ensure the consistency of their latent spaces. More specifically, we first leverage dual prediction to fill in missing views while achieving the instance-level alignment, and then take the contrastive reconstruction to achieve the class-level alignment. To the best of our knowledge, this could be the first successful attempt to handle the missing and unaligned data problem separately with different learning paradigms. Extensive experiments on public datasets demonstrate that our method significantly outperforms state-of-the-art methods on multi-view clustering even in the cases of view missing and unalignment.
Self-supervised Multi-view Clustering in Computer Vision: A Survey
Sep 18, 2023



Multi-view clustering (MVC) has had significant implications in cross-modal representation learning and data-driven decision-making in recent years. It accomplishes this by leveraging the consistency and complementary information among multiple views to cluster samples into distinct groups. However, as contrastive learning continues to evolve within the field of computer vision, self-supervised learning has also made substantial research progress and is progressively becoming dominant in MVC methods. It guides the clustering process by designing proxy tasks to mine the representation of image and video data itself as supervisory information. Despite the rapid development of self-supervised MVC, there has yet to be a comprehensive survey to analyze and summarize the current state of research progress. Therefore, this paper explores the reasons and advantages of the emergence of self-supervised MVC and discusses the internal connections and classifications of common datasets, data issues, representation learning methods, and self-supervised learning methods. This paper does not only introduce the mechanisms for each category of methods but also gives a few examples of how these techniques are used. In the end, some open problems are pointed out for further investigation and development.
Clustering-Induced Generative Incomplete Image-Text Clustering (CIGIT-C)
Sep 28, 2022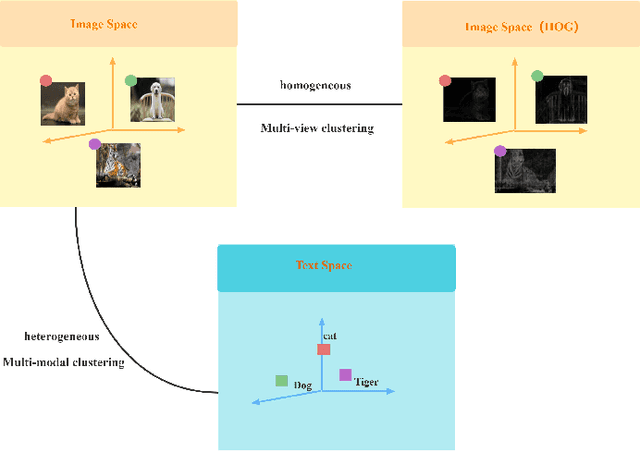

The target of image-text clustering (ITC) is to find correct clusters by integrating complementary and consistent information of multi-modalities for these heterogeneous samples. However, the majority of current studies analyse ITC on the ideal premise that the samples in every modality are complete. This presumption, however, is not always valid in real-world situations. The missing data issue degenerates the image-text feature learning performance and will finally affect the generalization abilities in ITC tasks. Although a series of methods have been proposed to address this incomplete image text clustering issue (IITC), the following problems still exist: 1) most existing methods hardly consider the distinct gap between heterogeneous feature domains. 2) For missing data, the representations generated by existing methods are rarely guaranteed to suit clustering tasks. 3) Existing methods do not tap into the latent connections both inter and intra modalities. In this paper, we propose a Clustering-Induced Generative Incomplete Image-Text Clustering(CIGIT-C) network to address the challenges above. More specifically, we first use modality-specific encoders to map original features to more distinctive subspaces. The latent connections between intra and inter-modalities are thoroughly explored by using the adversarial generating network to produce one modality conditional on the other modality. Finally, we update the corresponding modalityspecific encoders using two KL divergence losses. Experiment results on public image-text datasets demonstrated that the suggested method outperforms and is more effective in the IITC job.
Self-supervised Image Clustering from Multiple Incomplete Views via Constrastive Complementary Generation
Sep 24, 2022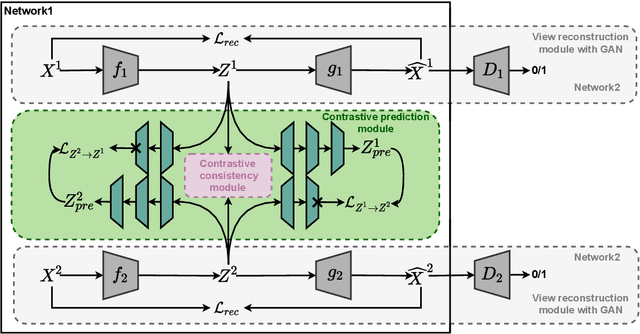
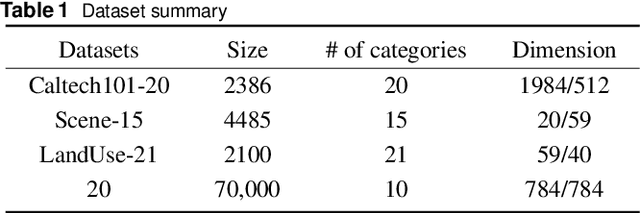
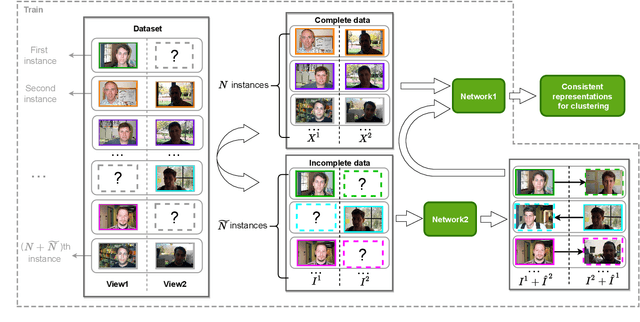
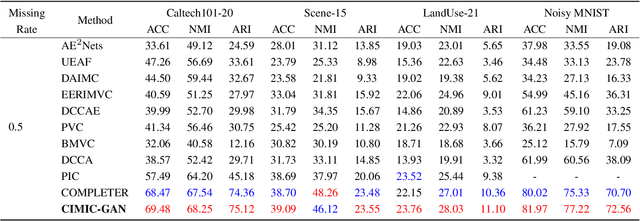
Incomplete Multi-View Clustering aims to enhance clustering performance by using data from multiple modalities. Despite the fact that several approaches for studying this issue have been proposed, the following drawbacks still persist: 1) It's difficult to learn latent representations that account for complementarity yet consistency without using label information; 2) and thus fails to take full advantage of the hidden information in incomplete data results in suboptimal clustering performance when complete data is scarce. In this paper, we propose Contrastive Incomplete Multi-View Image Clustering with Generative Adversarial Networks (CIMIC-GAN), which uses GAN to fill in incomplete data and uses double contrastive learning to learn consistency on complete and incomplete data. More specifically, considering diversity and complementary information among multiple modalities, we incorporate autoencoding representation of complete and incomplete data into double contrastive learning to achieve learning consistency. Integrating GANs into the autoencoding process can not only take full advantage of new features of incomplete data, but also better generalize the model in the presence of high data missing rates. Experiments conducted on \textcolor{black}{four} extensively-used datasets show that CIMIC-GAN outperforms state-of-the-art incomplete multi-View clustering methods.