 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-Search: Empowering LLM Reasoning with Search via Multi-Reward Reinforcement Learning
Jun 04, 2025Large language models (LLMs) have notably progressed in multi-step and long-chain reasoning. However, extending their reasoning capabilities to encompass deep interactions with search remains a non-trivial challenge, as models often fail to identify optimal reasoning-search interaction trajectories, resulting in suboptimal responses. We propose R-Search, a novel reinforcement learning framework for Reasoning-Search integration, designed to enable LLMs to autonomously execute multi-step reasoning with deep search interaction, and learn optimal reasoning search interaction trajectories via multi-reward signals, improving response quality in complex logic- and knowledge-intensive tasks. R-Search guides the LLM to dynamically decide when to retrieve or reason, while globally integrating key evidence to enhance deep knowledge interaction between reasoning and search. During RL training, R-Search provides multi-stage, multi-type rewards to jointly optimize the reasoning-search trajectory. Experiments on seven datasets show that R-Search outperforms advanced RAG baselines by up to 32.2% (in-domain) and 25.1% (out-of-domain). The code and data are available at https://github.com/QingFei1/R-Search.
BEM-Assisted Low-Complexity Channel Estimation for AFDM Systems over Doubly Selective Channels
Apr 26, 2025
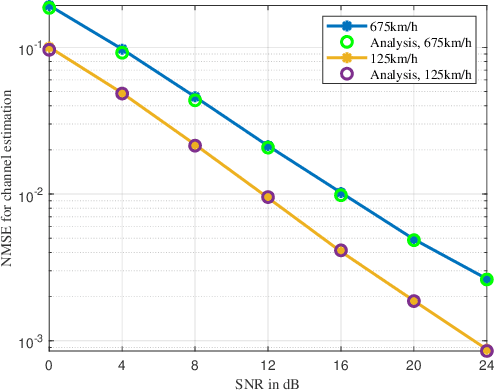
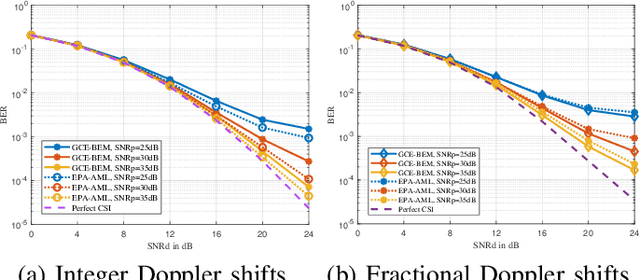
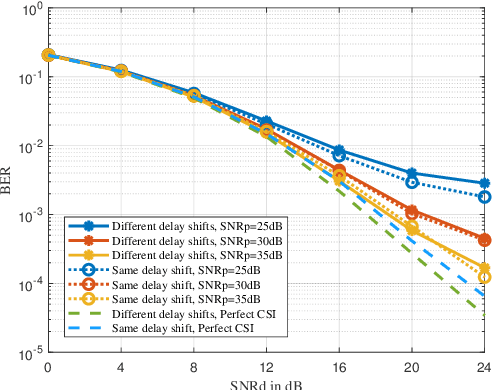
In this paper, we propose a low-complexity channel estimation scheme of affine frequency division multiplexing (AFDM) based on generalized complex exponential basis expansion model (GCE-BEM) over doubly selective channels. The GCE-BEM is used to solve fractional Doppler dispersion while significantly reducing the computational complexity of exhaustive search. Then, the closed-form expression of channel estimation error is derived for the minimum mean square error (MMSE) estimation algorithm. Based on the estimated channel, the MMSE detection is adopt to characterize the impacts of estimated channel on bit error rate (BER) by deriving the theoretical lower bound. Finally, numerical results demonstrate that the proposed scheme effectively mitigates severe inter-Doppler interference (IDoI). Our theoretical performance an alysis can perfectly match the Monte-Carlo results, validating the effectiveness of our proposed channel estimation based on GCE-BEM.
Mask Reference Image Quality Assessment
Mar 19, 2023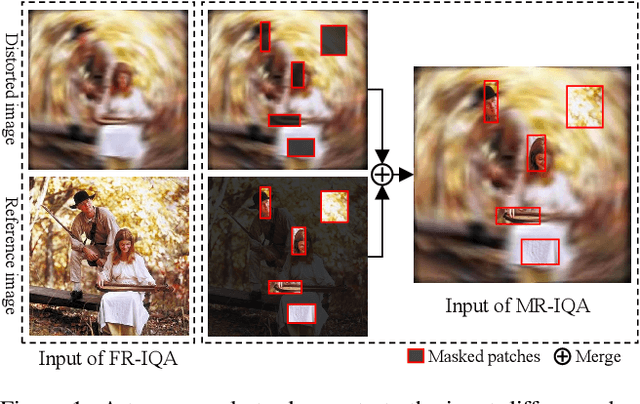
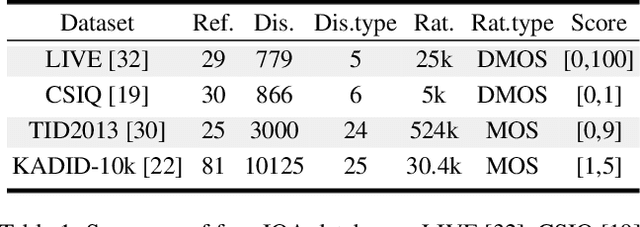
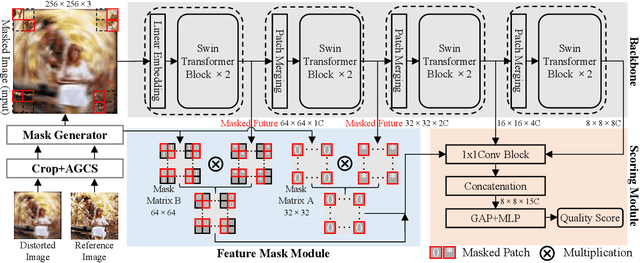
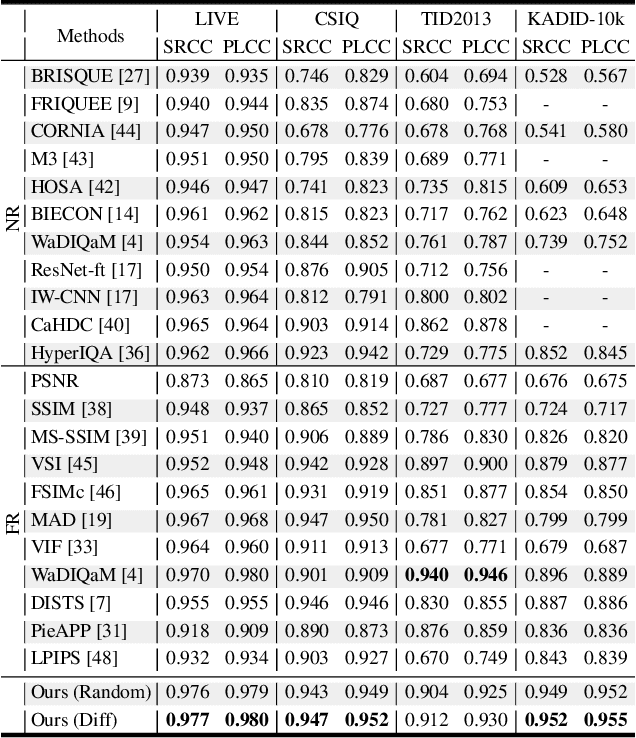
Understanding semantic information is an essential step in knowing what is being learned in both full-reference (FR) and no-reference (NR) image quality assessment (IQA) methods. However, especially for many severely distorted images, even if there is an undistorted image as a reference (FR-IQA), it is difficult to perceive the lost semantic and texture information of distorted images directly. In this paper, we propose a Mask Reference IQA (MR-IQA) method that masks specific patches of a distorted image and supplements missing patches with the reference image patches. In this way, our model only needs to input the reconstructed image for quality assessment. First, we design a mask generator to select the best candidate patches from reference images and supplement the lost semantic information in distorted images, thus providing more reference for quality assessment; in addition, the different masked patches imply different data augmentations, which favors model training and reduces overfitting. Second, we provide a Mask Reference Network (MRNet): the dedicated modules can prevent disturbances due to masked patches and help eliminate the patch discontinuity in the reconstructed image. Our method achieves state-of-the-art performances on the benchmark KADID-10k, LIVE and CSIQ datasets and has better generalization performance across datasets. The code and results are available in the supplementary material.
Clustering-Induced Generative Incomplete Image-Text Clustering (CIGIT-C)
Sep 28, 2022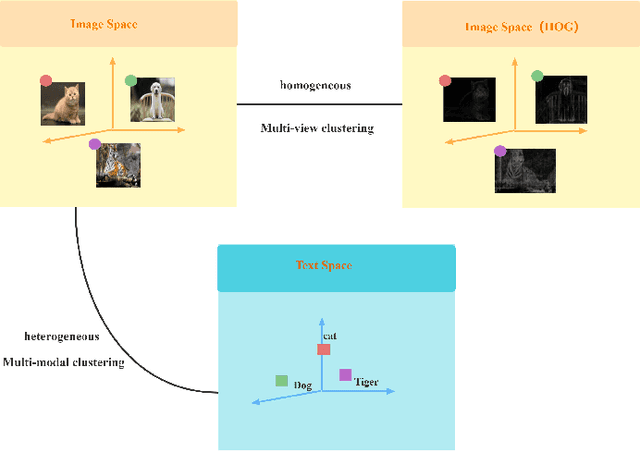
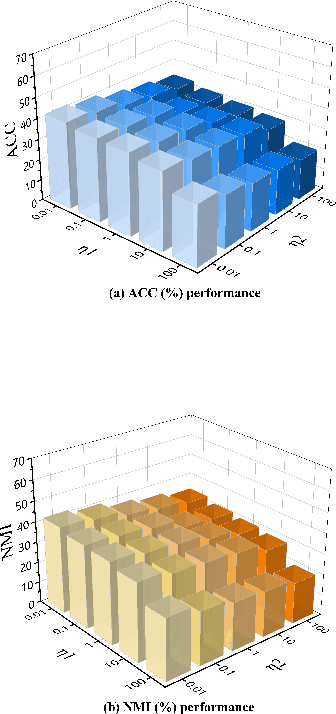
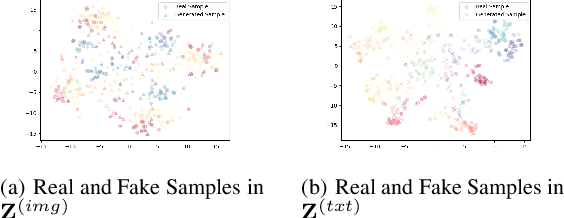

The target of image-text clustering (ITC) is to find correct clusters by integrating complementary and consistent information of multi-modalities for these heterogeneous samples. However, the majority of current studies analyse ITC on the ideal premise that the samples in every modality are complete. This presumption, however, is not always valid in real-world situations. The missing data issue degenerates the image-text feature learning performance and will finally affect the generalization abilities in ITC tasks. Although a series of methods have been proposed to address this incomplete image text clustering issue (IITC), the following problems still exist: 1) most existing methods hardly consider the distinct gap between heterogeneous feature domains. 2) For missing data, the representations generated by existing methods are rarely guaranteed to suit clustering tasks. 3) Existing methods do not tap into the latent connections both inter and intra modalities. In this paper, we propose a Clustering-Induced Generative Incomplete Image-Text Clustering(CIGIT-C) network to address the challenges above. More specifically, we first use modality-specific encoders to map original features to more distinctive subspaces. The latent connections between intra and inter-modalities are thoroughly explored by using the adversarial generating network to produce one modality conditional on the other modality. Finally, we update the corresponding modalityspecific encoders using two KL divergence losses. Experiment results on public image-text datasets demonstrated that the suggested method outperforms and is more effective in the IITC job.
Self-supervised Image Clustering from Multiple Incomplete Views via Constrastive Complementary Generation
Sep 24, 2022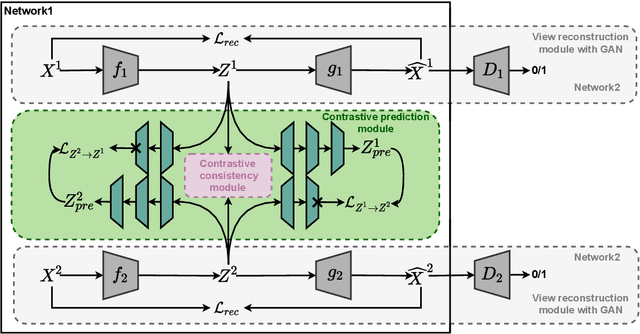
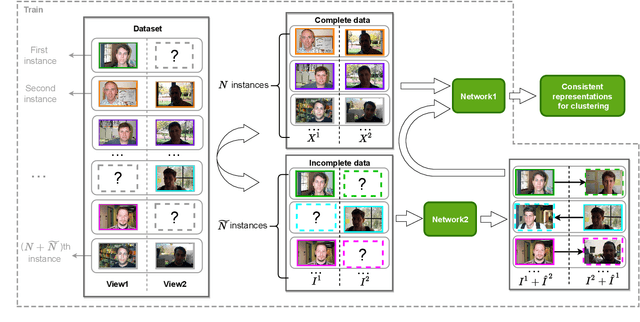
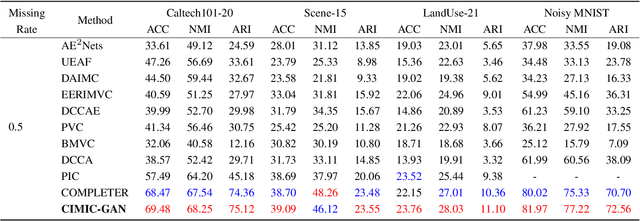
Incomplete Multi-View Clustering aims to enhance clustering performance by using data from multiple modalities. Despite the fact that several approaches for studying this issue have been proposed, the following drawbacks still persist: 1) It's difficult to learn latent representations that account for complementarity yet consistency without using label information; 2) and thus fails to take full advantage of the hidden information in incomplete data results in suboptimal clustering performance when complete data is scarce. In this paper, we propose Contrastive Incomplete Multi-View Image Clustering with Generative Adversarial Networks (CIMIC-GAN), which uses GAN to fill in incomplete data and uses double contrastive learning to learn consistency on complete and incomplete data. More specifically, considering diversity and complementary information among multiple modalities, we incorporate autoencoding representation of complete and incomplete data into double contrastive learning to achieve learning consistency. Integrating GANs into the autoencoding process can not only take full advantage of new features of incomplete data, but also better generalize the model in the presence of high data missing rates. Experiments conducted on \textcolor{black}{four} extensively-used datasets show that CIMIC-GAN outperforms state-of-the-art incomplete multi-View clustering methods.
Estimation & Recognition under Perspective of Random-Fuzzy Dual Interpretation of Unknown Quantity: with Demonstration of IMM Filter
Nov 02, 2021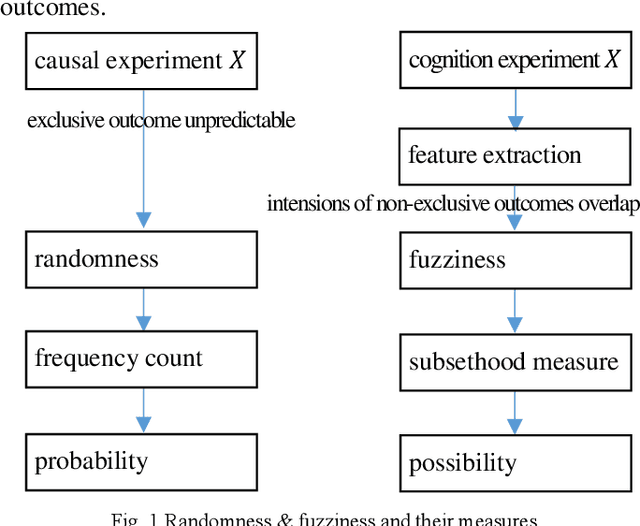
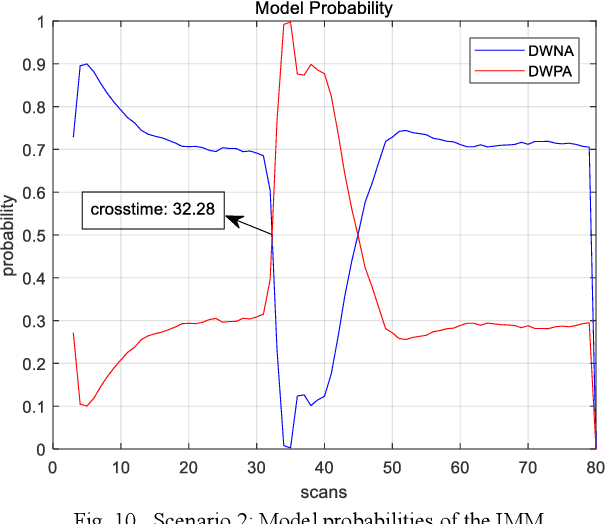
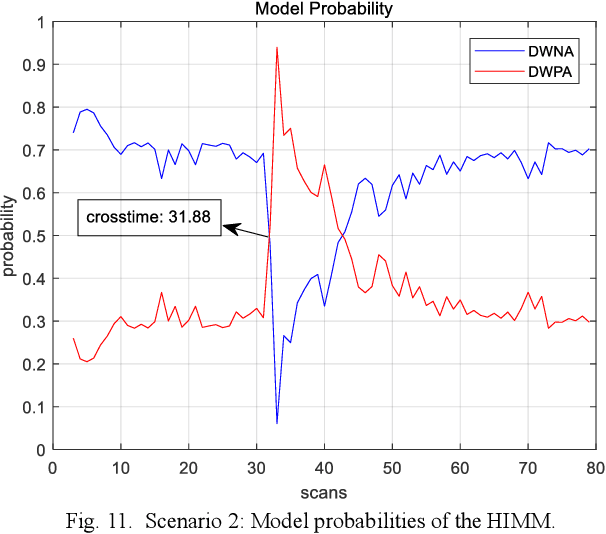
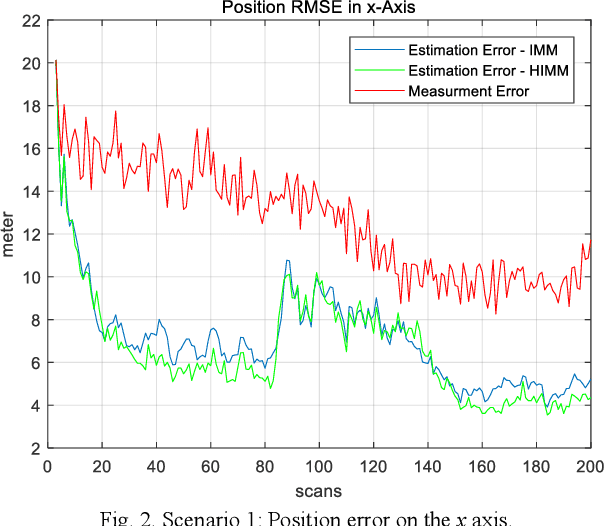
This paper is to consider the problems of estimation and recognition from the perspective of sigma-max inference (probability-possibility inference), with a focus on discovering whether some of the unknown quantities involved could be more faithfully modeled as fuzzy uncertainty. Two related key issues are addressed: 1) the random-fuzzy dual interpretation of unknown quantity being estimated; 2) the principle of selecting sigma-max operator for practical problems, such as estimation and recognition. Our perspective, conceived from definitions of randomness and fuzziness, is that continuous unknown quantity involved in estimation with inaccurate prior should be more appropriately modeled as randomness and handled by sigma inference; whereas discrete unknown quantity involved in recognition with insufficient (and inaccurate) prior could be better modeled as fuzziness and handled by max inference. The philosophy was demonstrated by an updated version of the well-known interacting multiple model (IMM) filter, for which the jump Markovian System is reformulated as a hybrid uncertainty system, with continuous state evolution modeled as usual as model-conditioned stochastic system and discrete mode transitions modeled as fuzzy system by a possibility (instead of probability) transition matrix, and hypotheses mixing is conducted by using the operation of "max" instead of "sigma". For our example of maneuvering target tracking using simulated data from both a short-range fire control radar and a long-range surveillance radar, the updated IMM filter shows significant improvement over the classic IMM filter, due to its peculiarity of hard decision of system model and a faster response to the transition of discrete mode.
The Sigma-Max System Induced from Randomness and Fuzziness
Oct 12, 2021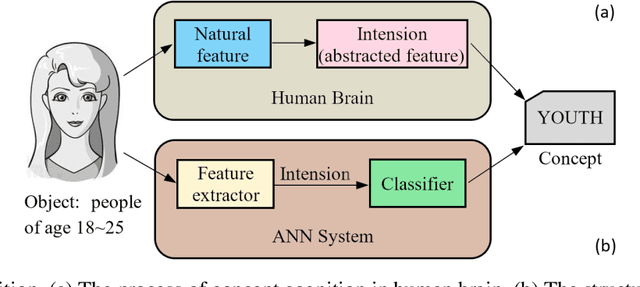
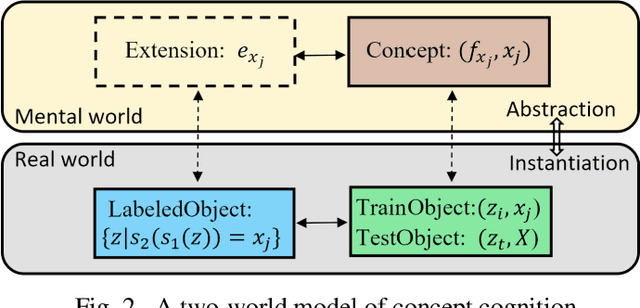
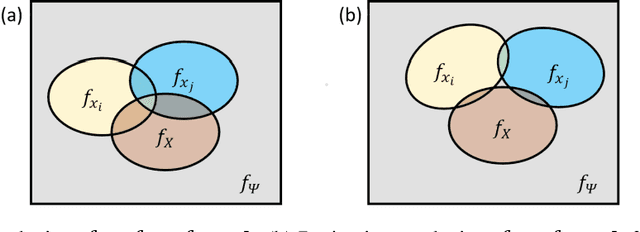
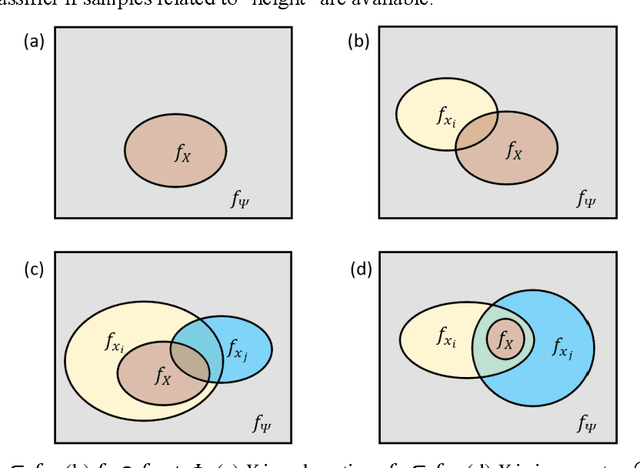
This paper managed to induce probability theory (sigma system) and possibility theory (max system) respectively from randomness and fuzziness, through which the premature theory of possibility is expected to be well founded. Such an objective is achieved by addressing three open key issues: a) the lack of clear mathematical definitions of randomness and fuzziness; b) the lack of intuitive mathematical definition of possibility; c) the lack of abstraction procedure of the axiomatic definitions of probability/possibility from their intuitive definitions. Especially, the last issue involves the question why the key axiom of "maxitivity" is adopted for possibility measure. By taking advantage of properties of the well-defined randomness and fuzziness, we derived the important conclusion that "max" is the only but un-strict disjunctive operator that is applicable across the fuzzy event space, and is an exact operator for fuzzy feature extraction that assures the max inference is an exact mechanism. It is fair to claim that the long-standing problem of lack of consensus to the foundation of possibility theory is well resolved, which would facilitate wider adoption of possibility theory in practice and promote cross prosperity of the two uncertainty theories of probability and possibility.
Towards Accurate Deceptive Opinion Spam Detection based on Word Order-preserving CNN
Mar 19, 2018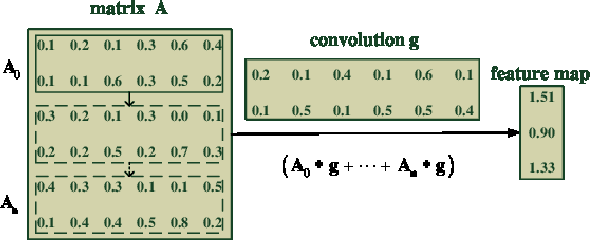

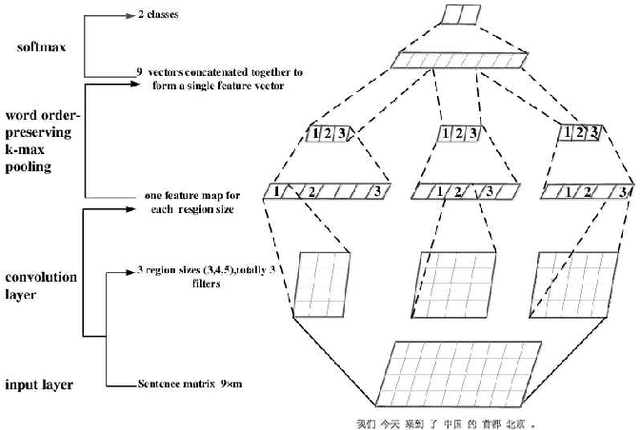

Nowadays, deep learning has been widely used. In natural language learning, the analysis of complex semantics has been achieved because of its high degree of flexibility. The deceptive opinions detection is an important application area in deep learning model, and related mechanisms have been given attention and researched. On-line opinions are quite short, varied types and content. In order to effectively identify deceptive opinions, we need to comprehensively study the characteristics of deceptive opinions, and explore novel characteristics besides the textual semantics and emotional polarity that have been widely used in text analysis. The detection mechanism based on deep learning has better self-adaptability and can effectively identify all kinds of deceptive opinions. In this paper, we optimize the convolution neural network model by embedding the word order characteristics in its convolution layer and pooling layer, which makes convolution neural network more suitable for various text classification and deceptive opinions detection. The TensorFlow-based experiments demonstrate that the detection mechanism proposed in this paper achieve more accurate deceptive opinion detection results.