 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 1st PortraitCraft Challenge: A CVPR 2026 Workshop Competition on Portrait Composition Understanding and Generation
Jun 09, 2026This paper presents an overview of the inaugural PortraitCraft Challenge, held as one of the official competitions at CVPR 2026. The challenge focuses on portrait composition understanding and generation, aiming to advance AI research in portrait aesthetics analysis and controllable image synthesis. Unlike existing datasets and tasks that primarily focus on global aesthetic scoring, PortraitCraft introduces a unified evaluation framework comprising two complementary tracks. Track 1 requires models to perform structured portrait composition understanding, and Track 2 requires models to generate portrait images from structured composition descriptions under explicit compositional constraints. To support the challenge, we constructed and publicly released a large-scale portrait composition dataset consisting of approximately 50,000 curated real portrait images, providing multi-level supervision. This report describes the challenge setup, evaluation protocols, dataset composition, and final results, along with an analysis of the technical characteristics of the submitted solutions. The PortraitCraft Challenge provides a standardized and reproducible platform for research on portrait composition understanding and generation, and is expected to foster further progress in the fields of portrait aesthetics and controllable image generation.
NTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
NTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024



This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.
SM4Depth: Seamless Monocular Metric Depth Estimation across Multiple Cameras and Scenes by One Model
Mar 13, 2024



The generalization of monocular metric depth estimation (MMDE) has been a longstanding challenge. Recent methods made progress by combining relative and metric depth or aligning input image focal length. However, they are still beset by challenges in camera, scene, and data levels: (1) Sensitivity to different cameras; (2) Inconsistent accuracy across scenes; (3) Reliance on massive training data. This paper proposes SM4Depth, a seamless MMDE method, to address all the issues above within a single network. First, we reveal that a consistent field of view (FOV) is the key to resolve ``metric ambiguity'' across cameras, which guides us to propose a more straightforward preprocessing unit. Second, to achieve consistently high accuracy across scenes, we explicitly model the metric scale determination as discretizing the depth interval into bins and propose variation-based unnormalized depth bins. This method bridges the depth gap of diverse scenes by reducing the ambiguity of the conventional metric bin. Third, to reduce the reliance on massive training data, we propose a ``divide and conquer" solution. Instead of estimating directly from the vast solution space, the correct metric bins are estimated from multiple solution sub-spaces for complexity reduction. Finally, with just 150K RGB-D pairs and a consumer-grade GPU for training, SM4Depth achieves state-of-the-art performance on most previously unseen datasets, especially surpassing ZoeDepth and Metric3D on mRI$_\theta$. The code can be found at https://github.com/1hao-Liu/SM4Depth.
An Efficient Learning-based Solver Comparable to Metaheuristics for the Capacitated Arc Routing Problem
Mar 11, 2024

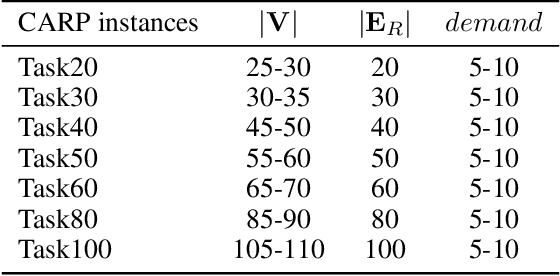

Recently, neural networks (NN) have made great strides in combinatorial optimization. However, they face challenges when solving the capacitated arc routing problem (CARP) which is to find the minimum-cost tour covering all required edges on a graph, while within capacity constraints. In tackling CARP, NN-based approaches tend to lag behind advanced metaheuristics, since they lack directed arc modeling and efficient learning methods tailored for complex CARP. In this paper, we introduce an NN-based solver to significantly narrow the gap with advanced metaheuristics while exhibiting superior efficiency. First, we propose the direction-aware attention model (DaAM) to incorporate directionality into the embedding process, facilitating more effective one-stage decision-making. Second, we design a supervised reinforcement learning scheme that involves supervised pre-training to establish a robust initial policy for subsequent reinforcement fine-tuning. It proves particularly valuable for solving CARP that has a higher complexity than the node routing problems (NRPs). Finally, a path optimization method is proposed to adjust the depot return positions within the path generated by DaAM. Experiments illustrate that our approach surpasses heuristics and achieves decision quality comparable to state-of-the-art metaheuristics for the first time while maintaining superior efficiency.
HDRTransDC: High Dynamic Range Image Reconstruction with Transformer Deformation Convolution
Mar 11, 2024



High Dynamic Range (HDR) imaging aims to generate an artifact-free HDR image with realistic details by fusing multi-exposure Low Dynamic Range (LDR) images. Caused by large motion and severe under-/over-exposure among input LDR images, HDR imaging suffers from ghosting artifacts and fusion distortions. To address these critical issues, we propose an HDR Transformer Deformation Convolution (HDRTransDC) network to generate high-quality HDR images, which consists of the Transformer Deformable Convolution Alignment Module (TDCAM) and the Dynamic Weight Fusion Block (DWFB). To solve the ghosting artifacts, the proposed TDCAM extracts long-distance content similar to the reference feature in the entire non-reference features, which can accurately remove misalignment and fill the content occluded by moving objects. For the purpose of eliminating fusion distortions, we propose DWFB to spatially adaptively select useful information across frames to effectively fuse multi-exposed features. Extensive experiments show that our method quantitatively and qualitatively achieves state-of-the-art performance.
Indoor Obstacle Discovery on Reflective Ground via Monocular Camera
Jan 02, 2024Visual obstacle discovery is a key step towards autonomous navigation of indoor mobile robots. Successful solutions have many applications in multiple scenes. One of the exceptions is the reflective ground. In this case, the reflections on the floor resemble the true world, which confuses the obstacle discovery and leaves navigation unsuccessful. We argue that the key to this problem lies in obtaining discriminative features for reflections and obstacles. Note that obstacle and reflection can be separated by the ground plane in 3D space. With this observation, we firstly introduce a pre-calibration based ground detection scheme that uses robot motion to predict the ground plane. Due to the immunity of robot motion to reflection, this scheme avoids failed ground detection caused by reflection. Given the detected ground, we design a ground-pixel parallax to describe the location of a pixel relative to the ground. Based on this, a unified appearance-geometry feature representation is proposed to describe objects inside rectangular boxes. Eventually, based on segmenting by detection framework, an appearance-geometry fusion regressor is designed to utilize the proposed feature to discover the obstacles. It also prevents our model from concentrating too much on parts of obstacles instead of whole obstacles. For evaluation, we introduce a new dataset for Obstacle on Reflective Ground (ORG), which comprises 15 scenes with various ground reflections, a total of more than 200 image sequences and 3400 RGB images. The pixel-wise annotations of ground and obstacle provide a comparison to our method and other methods. By reducing the misdetection of the reflection, the proposed approach outperforms others. The source code and the dataset will be available at https://github.com/XuefengBUPT/IndoorObstacleDiscovery-RG.
Unknown Sniffer for Object Detection: Don't Turn a Blind Eye to Unknown Objects
Mar 24, 2023The recently proposed open-world object and open-set detection achieve a breakthrough in finding never-seen-before objects and distinguishing them from class-known ones. However, their studies on knowledge transfer from known classes to unknown ones need to be deeper, leading to the scanty capability for detecting unknowns hidden in the background. In this paper, we propose the unknown sniffer (UnSniffer) to find both unknown and known objects. Firstly, the generalized object confidence (GOC) score is introduced, which only uses class-known samples for supervision and avoids improper suppression of unknowns in the background. Significantly, such confidence score learned from class-known objects can be generalized to unknown ones. Additionally, we propose a negative energy suppression loss to further limit the non-object samples in the background. Next, the best box of each unknown is hard to obtain during inference due to lacking their semantic information in training. To solve this issue, we introduce a graph-based determination scheme to replace hand-designed non-maximum suppression (NMS) post-processing. Finally, we present the Unknown Object Detection Benchmark, the first publicly benchmark that encompasses precision evaluation for unknown object detection to our knowledge. Experiments show that our method is far better than the existing state-of-the-art methods. Code is available at: https://github.com/Went-Liang/UnSniffer.
Mask Reference Image Quality Assessment
Mar 19, 2023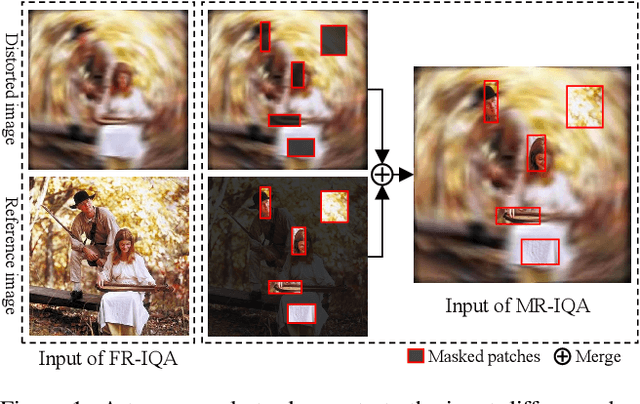
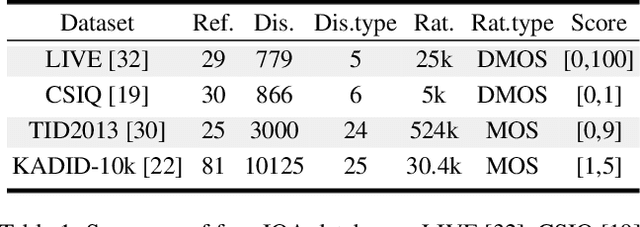
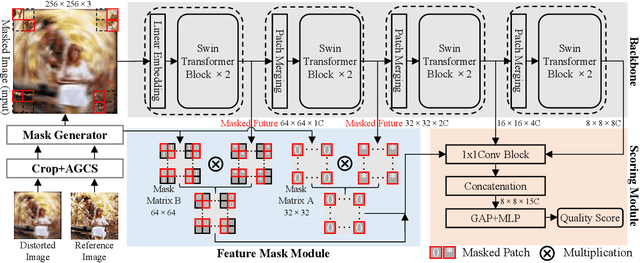
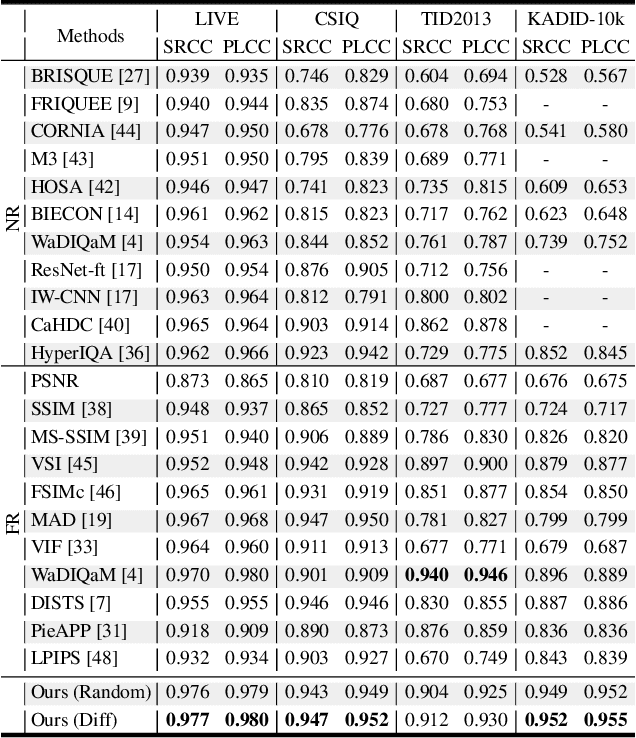
Understanding semantic information is an essential step in knowing what is being learned in both full-reference (FR) and no-reference (NR) image quality assessment (IQA) methods. However, especially for many severely distorted images, even if there is an undistorted image as a reference (FR-IQA), it is difficult to perceive the lost semantic and texture information of distorted images directly. In this paper, we propose a Mask Reference IQA (MR-IQA) method that masks specific patches of a distorted image and supplements missing patches with the reference image patches. In this way, our model only needs to input the reconstructed image for quality assessment. First, we design a mask generator to select the best candidate patches from reference images and supplement the lost semantic information in distorted images, thus providing more reference for quality assessment; in addition, the different masked patches imply different data augmentations, which favors model training and reduces overfitting. Second, we provide a Mask Reference Network (MRNet): the dedicated modules can prevent disturbances due to masked patches and help eliminate the patch discontinuity in the reconstructed image. Our method achieves state-of-the-art performances on the benchmark KADID-10k, LIVE and CSIQ datasets and has better generalization performance across datasets. The code and results are available in the supplementary material.