 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiM3D: Single-instance Multiview Multimodal and Multisetup 3D Anomaly Detection Benchmark
Jun 26, 2025We propose SiM3D, the first benchmark considering the integration of multiview and multimodal information for comprehensive 3D anomaly detection and segmentation (ADS), where the task is to produce a voxel-based Anomaly Volume. Moreover, SiM3D focuses on a scenario of high interest in manufacturing: single-instance anomaly detection, where only one object, either real or synthetic, is available for training. In this respect, SiM3D stands out as the first ADS benchmark that addresses the challenge of generalising from synthetic training data to real test data. SiM3D includes a novel multimodal multiview dataset acquired using top-tier industrial sensors and robots. The dataset features multiview high-resolution images (12 Mpx) and point clouds (7M points) for 333 instances of eight types of objects, alongside a CAD model for each type. We also provide manually annotated 3D segmentation GTs for anomalous test samples. To establish reference baselines for the proposed multiview 3D ADS task, we adapt prominent singleview methods and assess their performance using novel metrics that operate on Anomaly Volumes.
NTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
Towards Reliable Identification of Diffusion-based Image Manipulations
Jun 05, 2025Changing facial expressions, gestures, or background details may dramatically alter the meaning conveyed by an image. Notably, recent advances in diffusion models greatly improve the quality of image manipulation while also opening the door to misuse. Identifying changes made to authentic images, thus, becomes an important task, constantly challenged by new diffusion-based editing tools. To this end, we propose a novel approach for ReliAble iDentification of inpainted AReas (RADAR). RADAR builds on existing foundation models and combines features from different image modalities. It also incorporates an auxiliary contrastive loss that helps to isolate manipulated image patches. We demonstrate these techniques to significantly improve both the accuracy of our method and its generalisation to a large number of diffusion models. To support realistic evaluation, we further introduce BBC-PAIR, a new comprehensive benchmark, with images tampered by 28 diffusion models. Our experiments show that RADAR achieves excellent results, outperforming the state-of-the-art in detecting and localising image edits made by both seen and unseen diffusion models. Our code, data and models will be publicly available at alex-costanzino.github.io/radar.
Looking for Tiny Defects via Forward-Backward Feature Transfer
Jul 04, 2024Motivated by efficiency requirements, most anomaly detection and segmentation (AD&S) methods focus on processing low-resolution images, e.g., $224\times 224$ pixels, obtained by downsampling the original input images. In this setting, downsampling is typically applied also to the provided ground-truth defect masks. Yet, as numerous industrial applications demand identification of both large and tiny defects, the above-described protocol may fall short in providing a realistic picture of the actual performance attainable by current methods. Hence, in this work, we introduce a novel benchmark that evaluates methods on the original, high-resolution image and ground-truth masks, focusing on segmentation performance as a function of the size of anomalies. Our benchmark includes a metric that captures robustness with respect to defect size, i.e., the ability of a method to preserve good localization from large anomalies to tiny ones. Furthermore, we introduce an AD&S approach based on a novel Teacher-Student paradigm which relies on two shallow MLPs (the Students) that learn to transfer patch features across the layers of a frozen vision transformer (the Teacher). By means of our benchmark, we evaluate our proposal and other recent AD&S methods on high-resolution inputs containing large and tiny defects. Our proposal features the highest robustness to defect size, runs at the fastest speed, yields state-of-the-art performance on the MVTec AD dataset and state-of-the-art segmentation performance on the VisA dataset.
Test Time Training for Industrial Anomaly Segmentation
Apr 04, 2024Anomaly Detection and Segmentation (AD&S) is crucial for industrial quality control. While existing methods excel in generating anomaly scores for each pixel, practical applications require producing a binary segmentation to identify anomalies. Due to the absence of labeled anomalies in many real scenarios, standard practices binarize these maps based on some statistics derived from a validation set containing only nominal samples, resulting in poor segmentation performance. This paper addresses this problem by proposing a test time training strategy to improve the segmentation performance. Indeed, at test time, we can extract rich features directly from anomalous samples to train a classifier that can discriminate defects effectively. Our general approach can work downstream to any AD&S method that provides an anomaly score map as output, even in multimodal settings. We demonstrate the effectiveness of our approach over baselines through extensive experimentation and evaluation on MVTec AD and MVTec 3D-AD.
Multimodal Industrial Anomaly Detection by Crossmodal Feature Mapping
Dec 07, 2023The paper explores the industrial multimodal Anomaly Detection (AD) task, which exploits point clouds and RGB images to localize anomalies. We introduce a novel light and fast framework that learns to map features from one modality to the other on nominal samples. At test time, anomalies are detected by pinpointing inconsistencies between observed and mapped features. Extensive experiments show that our approach achieves state-of-the-art detection and segmentation performance in both the standard and few-shot settings on the MVTec 3D-AD dataset while achieving faster inference and occupying less memory than previous multimodal AD methods. Moreover, we propose a layer-pruning technique to improve memory and time efficiency with a marginal sacrifice in performance.
Learning Depth Estimation for Transparent and Mirror Surfaces
Jul 27, 2023
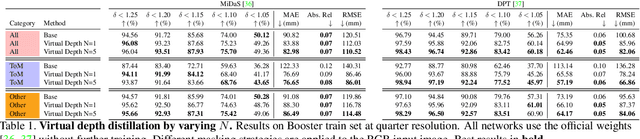


Inferring the depth of transparent or mirror (ToM) surfaces represents a hard challenge for either sensors, algorithms, or deep networks. We propose a simple pipeline for learning to estimate depth properly for such surfaces with neural networks, without requiring any ground-truth annotation. We unveil how to obtain reliable pseudo labels by in-painting ToM objects in images and processing them with a monocular depth estimation model. These labels can be used to fine-tune existing monocular or stereo networks, to let them learn how to deal with ToM surfaces. Experimental results on the Booster dataset show the dramatic improvements enabled by our remarkably simple proposal.
Booster: a Benchmark for Depth from Images of Specular and Transparent Surfaces
Jan 19, 2023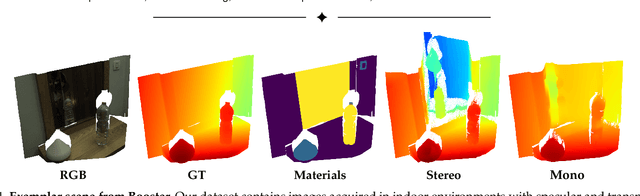



Estimating depth from images nowadays yields outstanding results, both in terms of in-domain accuracy and generalization. However, we identify two main challenges that remain open in this field: dealing with non-Lambertian materials and effectively processing high-resolution images. Purposely, we propose a novel dataset that includes accurate and dense ground-truth labels at high resolution, featuring scenes containing several specular and transparent surfaces. Our acquisition pipeline leverages a novel deep space-time stereo framework, enabling easy and accurate labeling with sub-pixel precision. The dataset is composed of 606 samples collected in 85 different scenes, each sample includes both a high-resolution pair (12 Mpx) as well as an unbalanced stereo pair (Left: 12 Mpx, Right: 1.1 Mpx). Additionally, we provide manually annotated material segmentation masks and 15K unlabeled samples. We divide the dataset into a training set, and two testing sets, the latter devoted to the evaluation of stereo and monocular depth estimation networks respectively to highlight the open challenges and future research directions in this field.