 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Cross-Modal Prompting for Event-Frame Asymmetric Stereo
Apr 16, 2026Conventional frame-based cameras capture rich contextual information but suffer from limited temporal resolution and motion blur in dynamic scenes. Event cameras offer an alternative visual representation with higher dynamic range free from such limitations. The complementary characteristics of the two modalities make event-frame asymmetric stereo promising for reliable 3D perception under fast motion and challenging illumination. However, the modality gap often leads to marginalization of domain-specific cues essential for cross-modal stereo matching. In this paper, we introduce Bi-CMPStereo, a novel bidirectional cross-modal prompting framework that fully exploits semantic and structural features from both domains for robust matching. Our approach learns finely aligned stereo representations within a target canonical space and integrates complementary representations by projecting each modality into both event and frame domains. Extensive experiments demonstrate that our approach significantly outperforms state-of-the-art methods in accuracy and generalization.
EventHub: Data Factory for Generalizable Event-Based Stereo Networks without Active Sensors
Apr 02, 2026We propose EventHub, a novel framework for training deep-event stereo networks without ground truth annotations from costly active sensors, relying instead on standard color images. From these images, we derive either proxy annotations and proxy events through state-of-the-art novel view synthesis techniques, or simply proxy annotations when images are already paired with event data. Using the training set generated by our data factory, we repurpose state-of-the-art stereo models from RGB literature to process event data, obtaining new event stereo models with unprecedented generalization capabilities. Experiments on widely used event stereo datasets support the effectiveness of EventHub and show how the same data distillation mechanism can improve the accuracy of RGB stereo foundation models in challenging conditions such as nighttime scenes.
Depth AnyEvent: A Cross-Modal Distillation Paradigm for Event-Based Monocular Depth Estimation
Sep 18, 2025Event cameras capture sparse, high-temporal-resolution visual information, making them particularly suitable for challenging environments with high-speed motion and strongly varying lighting conditions. However, the lack of large datasets with dense ground-truth depth annotations hinders learning-based monocular depth estimation from event data. To address this limitation, we propose a cross-modal distillation paradigm to generate dense proxy labels leveraging a Vision Foundation Model (VFM). Our strategy requires an event stream spatially aligned with RGB frames, a simple setup even available off-the-shelf, and exploits the robustness of large-scale VFMs. Additionally, we propose to adapt VFMs, either a vanilla one like Depth Anything v2 (DAv2), or deriving from it a novel recurrent architecture to infer depth from monocular event cameras. We evaluate our approach with synthetic and real-world datasets, demonstrating that i) our cross-modal paradigm achieves competitive performance compared to fully supervised methods without requiring expensive depth annotations, and ii) our VFM-based models achieve state-of-the-art performance.
Stereo 3D Gaussian Splatting SLAM for Outdoor Urban Scenes
Jul 31, 20253D Gaussian Splatting (3DGS) has recently gained popularity in SLAM applications due to its fast rendering and high-fidelity representation. However, existing 3DGS-SLAM systems have predominantly focused on indoor environments and relied on active depth sensors, leaving a gap for large-scale outdoor applications. We present BGS-SLAM, the first binocular 3D Gaussian Splatting SLAM system designed for outdoor scenarios. Our approach uses only RGB stereo pairs without requiring LiDAR or active sensors. BGS-SLAM leverages depth estimates from pre-trained deep stereo networks to guide 3D Gaussian optimization with a multi-loss strategy enhancing both geometric consistency and visual quality. Experiments on multiple datasets demonstrate that BGS-SLAM achieves superior tracking accuracy and mapping performance compared to other 3DGS-based solutions in complex outdoor environments.
Ov3R: Open-Vocabulary Semantic 3D Reconstruction from RGB Videos
Jul 29, 2025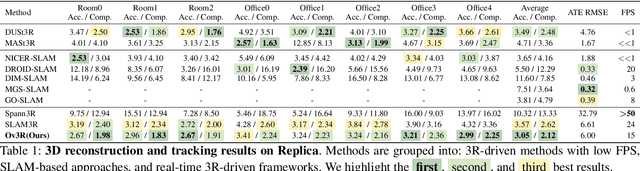
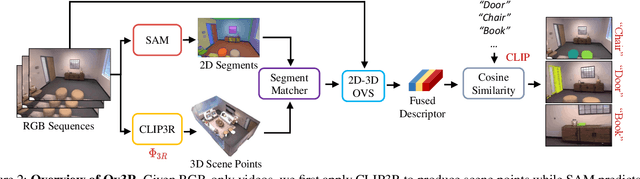

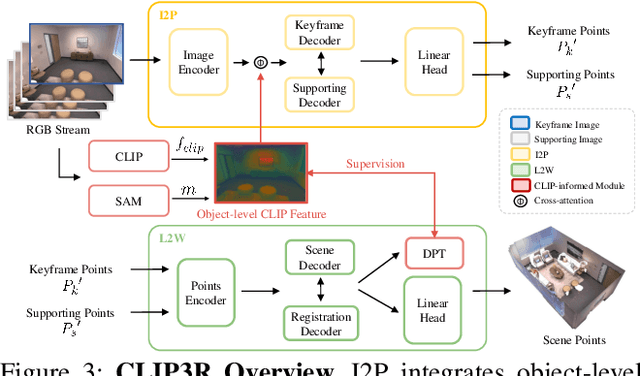
We present Ov3R, a novel framework for open-vocabulary semantic 3D reconstruction from RGB video streams, designed to advance Spatial AI. The system features two key components: CLIP3R, a CLIP-informed 3D reconstruction module that predicts dense point maps from overlapping clips while embedding object-level semantics; and 2D-3D OVS, a 2D-3D open-vocabulary semantic module that lifts 2D features into 3D by learning fused descriptors integrating spatial, geometric, and semantic cues. Unlike prior methods, Ov3R incorporates CLIP semantics directly into the reconstruction process, enabling globally consistent geometry and fine-grained semantic alignment. Our framework achieves state-of-the-art performance in both dense 3D reconstruction and open-vocabulary 3D segmentation, marking a step forward toward real-time, semantics-aware Spatial AI.
NTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
ToF-Splatting: Dense SLAM using Sparse Time-of-Flight Depth and Multi-Frame Integration
Apr 23, 2025Time-of-Flight (ToF) sensors provide efficient active depth sensing at relatively low power budgets; among such designs, only very sparse measurements from low-resolution sensors are considered to meet the increasingly limited power constraints of mobile and AR/VR devices. However, such extreme sparsity levels limit the seamless usage of ToF depth in SLAM. In this work, we propose ToF-Splatting, the first 3D Gaussian Splatting-based SLAM pipeline tailored for using effectively very sparse ToF input data. Our approach improves upon the state of the art by introducing a multi-frame integration module, which produces dense depth maps by merging cues from extremely sparse ToF depth, monocular color, and multi-view geometry. Extensive experiments on both synthetic and real sparse ToF datasets demonstrate the viability of our approach, as it achieves state-of-the-art tracking and mapping performances on reference datasets.
HS-SLAM: Hybrid Representation with Structural Supervision for Improved Dense SLAM
Mar 27, 2025NeRF-based SLAM has recently achieved promising results in tracking and reconstruction. However, existing methods face challenges in providing sufficient scene representation, capturing structural information, and maintaining global consistency in scenes emerging significant movement or being forgotten. To this end, we present HS-SLAM to tackle these problems. To enhance scene representation capacity, we propose a hybrid encoding network that combines the complementary strengths of hash-grid, tri-planes, and one-blob, improving the completeness and smoothness of reconstruction. Additionally, we introduce structural supervision by sampling patches of non-local pixels rather than individual rays to better capture the scene structure. To ensure global consistency, we implement an active global bundle adjustment (BA) to eliminate camera drifts and mitigate accumulative errors. Experimental results demonstrate that HS-SLAM outperforms the baselines in tracking and reconstruction accuracy while maintaining the efficiency required for robotics.
Stereo Anywhere: Robust Zero-Shot Deep Stereo Matching Even Where Either Stereo or Mono Fail
Dec 05, 2024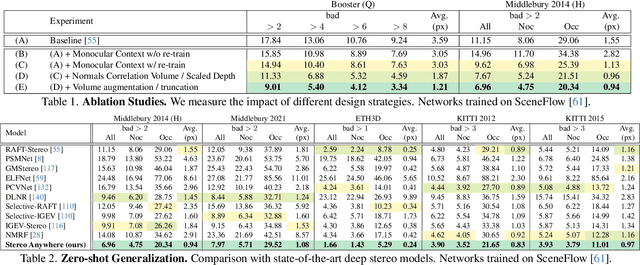
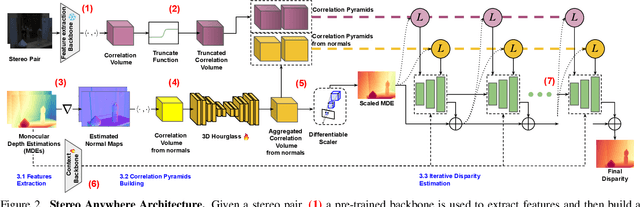

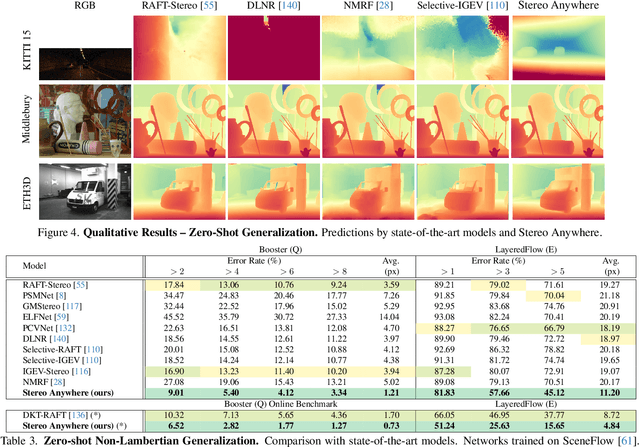
We introduce Stereo Anywhere, a novel stereo-matching framework that combines geometric constraints with robust priors from monocular depth Vision Foundation Models (VFMs). By elegantly coupling these complementary worlds through a dual-branch architecture, we seamlessly integrate stereo matching with learned contextual cues. Following this design, our framework introduces novel cost volume fusion mechanisms that effectively handle critical challenges such as textureless regions, occlusions, and non-Lambertian surfaces. Through our novel optical illusion dataset, MonoTrap, and extensive evaluation across multiple benchmarks, we demonstrate that our synthetic-only trained model achieves state-of-the-art results in zero-shot generalization, significantly outperforming existing solutions while showing remarkable robustness to challenging cases such as mirrors and transparencies.
Depth on Demand: Streaming Dense Depth from a Low Frame Rate Active Sensor
Sep 12, 2024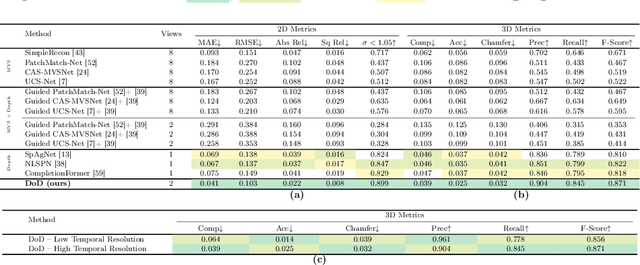

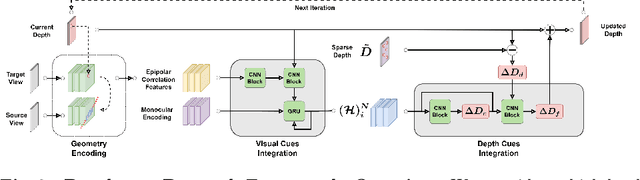

High frame rate and accurate depth estimation plays an important role in several tasks crucial to robotics and automotive perception. To date, this can be achieved through ToF and LiDAR devices for indoor and outdoor applications, respectively. However, their applicability is limited by low frame rate, energy consumption, and spatial sparsity. Depth on Demand (DoD) allows for accurate temporal and spatial depth densification achieved by exploiting a high frame rate RGB sensor coupled with a potentially lower frame rate and sparse active depth sensor. Our proposal jointly enables lower energy consumption and denser shape reconstruction, by significantly reducing the streaming requirements on the depth sensor thanks to its three core stages: i) multi-modal encoding, ii) iterative multi-modal integration, and iii) depth decoding. We present extended evidence assessing the effectiveness of DoD on indoor and outdoor video datasets, covering both environment scanning and automotive perception use cases.