 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Semantic and Pixel Representations for Ultra-Low Bitrate Image Compression
Jun 01, 2026Most existing extreme compression methods fail to achieve an optimal rate-distortion-perception trade-off, as they typically prioritize perceptual fidelity and visual realism over pixel-level accuracy. Consequently, the resulting reconstructions often deviate noticeably from the originals. Ultra-low bitrate image compression is therefore crucial-not only for producing extremely compact representations but also for ensuring that reconstructed images remain semantically coherent and faithful to the source at the pixel level. To this end, we propose SPRDiff, a diffusion-based compression method that fully leverages both semantic and pixel representations, thereby enhancing reconstruction fidelity under ultra-low bitrate constraints. Specifically, we develop a triple-encoder architecture that utilizes high-fidelity features from the pretrained distortion-oriented and semantic-oriented encoders to compensate for the limited representations extracted by the frozen VAE encoder, thereby improving latent compression and entropy modeling. To further enhance the reconstruction fidelity of diffusion models, we introduce a distortion-aware reconstruction module with dual feature extraction. This module not only generates a coarse reconstruction that preserves the main structures, but also provides practical and accurate semantic- and pixel-level conditional signals to guide the diffusion model. Extensive experiments on benchmark datasets demonstrate that our method outperforms state-of-the-art approaches in the rate-distortion-perception tradeoff at extremely low bitrates (below 0.03 bpp), effectively preserving both perceptual quality and pixel-wise fidelity in the reconstructed images. We will release the source code and trained models at https://github.com/cshw2021/SPRDiff.
SAMIC: A Lightweight Semantic-Aware Mamba for Efficient Perceptual Image Compression
May 06, 2026Perceptual image compression focuses on preserving high visual quality under low-bitrate constraints. Most existing approaches to perceptual compression leverage the strong generative capabilities of generative adversarial networks or diffusion models, at the cost of substantial model complexity. To this end, we present an efficient perceptual image compression method that exploits the long-range modeling capability and linear computational complexity of state space models, with a particular focus on Mamba. Unlike existing methods that rely on an inherently fixed scanning order and consequently impair semantic continuity and spatial correlation, we develop a semantic-aware Mamba block (SAMB) to enable scanning guided by dynamically clustered semantic features, thereby alleviating the strict causality constraints and long-range information decay inherent to Mamba. Inspired by singular value decomposition, we design an SVD-inspired redundancy reduction module (SVD-RRM) that performs a low-rank approximation on the latent features by introducing a learnable soft threshold, leading to channel-wise redundancy information reduction. The proposed SAMB is integrated into both the encoder and decoder of the compression framework, whereas the SVD-RRM is incorporated only in the encoder. Extensive experiments demonstrate that our method performs favorably against state-of-the-art approaches in terms of rate-distortion-perception tradeoff and model complexity. The source code and pretrained models will be available at https://github.com/Jasmine-aiq/SAMIC.
Geometric Transformation-Embedded Mamba for Learned Video Compression
Mar 09, 2026Although learned video compression methods have exhibited outstanding performance, most of them typically follow a hybrid coding paradigm that requires explicit motion estimation and compensation, resulting in a complex solution for video compression. In contrast, we introduce a streamlined yet effective video compression framework founded on a direct transform strategy, i.e., nonlinear transform, quantization, and entropy coding. We first develop a cascaded Mamba module (CMM) with different embedded geometric transformations to effectively explore both long-range spatial and temporal dependencies. To improve local spatial representation, we introduce a locality refinement feed-forward network (LRFFN) that incorporates a hybrid convolution block based on difference convolutions. We integrate the proposed CMM and LRFFN into the encoder and decoder of our compression framework. Moreover, we present a conditional channel-wise entropy model that effectively utilizes conditional temporal priors to accurately estimate the probability distributions of current latent features. Extensive experiments demonstrate that our method outperforms state-of-the-art video compression approaches in terms of perceptual quality and temporal consistency under low-bitrate constraints. Our source codes and models will be available at https://github.com/cshw2021/GTEM-LVC.
One-Step Diffusion for Perceptual Image Compression
Feb 02, 2026Diffusion-based image compression methods have achieved notable progress, delivering high perceptual quality at low bitrates. However, their practical deployment is hindered by significant inference latency and heavy computational overhead, primarily due to the large number of denoising steps required during decoding. To address this problem, we propose a diffusion-based image compression method that requires only a single-step diffusion process, significantly improving inference speed. To enhance the perceptual quality of reconstructed images, we introduce a discriminator that operates on compact feature representations instead of raw pixels, leveraging the fact that features better capture high-level texture and structural details. Experimental results show that our method delivers comparable compression performance while offering a 46$\times$ faster inference speed compared to recent diffusion-based approaches. The source code and models are available at https://github.com/cheesejiang/OSDiff.
A Lightweight Model for Perceptual Image Compression via Implicit Priors
Feb 19, 2025Perceptual image compression has shown strong potential for producing visually appealing results at low bitrates, surpassing classical standards and pixel-wise distortion-oriented neural methods. However, existing methods typically improve compression performance by incorporating explicit semantic priors, such as segmentation maps and textual features, into the encoder or decoder, which increases model complexity by adding parameters and floating-point operations. This limits the model's practicality, as image compression often occurs on resource-limited mobile devices. To alleviate this problem, we propose a lightweight perceptual Image Compression method using Implicit Semantic Priors (ICISP). We first develop an enhanced visual state space block that exploits local and global spatial dependencies to reduce redundancy. Since different frequency information contributes unequally to compression, we develop a frequency decomposition modulation block to adaptively preserve or reduce the low-frequency and high-frequency information. We establish the above blocks as the main modules of the encoder-decoder, and to further improve the perceptual quality of the reconstructed images, we develop a semantic-informed discriminator that uses implicit semantic priors from a pretrained DINOv2 encoder. Experiments on popular benchmarks show that our method achieves competitive compression performance and has significantly fewer network parameters and floating point operations than the existing state-of-the-art.
Diffusion-based Extreme Image Compression with Compressed Feature Initialization
Oct 03, 2024Diffusion-based extreme image compression methods have achieved impressive performance at extremely low bitrates. However, constrained by the iterative denoising process that starts from pure noise, these methods are limited in both fidelity and efficiency. To address these two issues, we present Relay Residual Diffusion Extreme Image Compression (RDEIC), which leverages compressed feature initialization and residual diffusion. Specifically, we first use the compressed latent features of the image with added noise, instead of pure noise, as the starting point to eliminate the unnecessary initial stages of the denoising process. Second, we design a novel relay residual diffusion that reconstructs the raw image by iteratively removing the added noise and the residual between the compressed and target latent features. Notably, our relay residual diffusion network seamlessly integrates pre-trained stable diffusion to leverage its robust generative capability for high-quality reconstruction. Third, we propose a fixed-step fine-tuning strategy to eliminate the discrepancy between the training and inference phases, further improving the reconstruction quality. Extensive experiments demonstrate that the proposed RDEIC achieves state-of-the-art visual quality and outperforms existing diffusion-based extreme image compression methods in both fidelity and efficiency. The source code will be provided in https://github.com/huai-chang/RDEIC.
RGB Guided ToF Imaging System: A Survey of Deep Learning-based Methods
May 16, 2024Integrating an RGB camera into a ToF imaging system has become a significant technique for perceiving the real world. The RGB guided ToF imaging system is crucial to several applications, including face anti-spoofing, saliency detection, and trajectory prediction. Depending on the distance of the working range, the implementation schemes of the RGB guided ToF imaging systems are different. Specifically, ToF sensors with a uniform field of illumination, which can output dense depth but have low resolution, are typically used for close-range measurements. In contrast, LiDARs, which emit laser pulses and can only capture sparse depth, are usually employed for long-range detection. In the two cases, depth quality improvement for RGB guided ToF imaging corresponds to two sub-tasks: guided depth super-resolution and guided depth completion. In light of the recent significant boost to the field provided by deep learning, this paper comprehensively reviews the works related to RGB guided ToF imaging, including network structures, learning strategies, evaluation metrics, benchmark datasets, and objective functions. Besides, we present quantitative comparisons of state-of-the-art methods on widely used benchmark datasets. Finally, we discuss future trends and the challenges in real applications for further research.
Towards Extreme Image Compression with Latent Feature Guidance and Diffusion Prior
Apr 29, 2024Compressing images at extremely low bitrates (below 0.1 bits per pixel (bpp)) is a significant challenge due to substantial information loss. Existing extreme image compression methods generally suffer from heavy compression artifacts or low-fidelity reconstructions. To address this problem, we propose a novel extreme image compression framework that combines compressive VAEs and pre-trained text-to-image diffusion models in an end-to-end manner. Specifically, we introduce a latent feature-guided compression module based on compressive VAEs. This module compresses images and initially decodes the compressed information into content variables. To enhance the alignment between content variables and the diffusion space, we introduce external guidance to modulate intermediate feature maps. Subsequently, we develop a conditional diffusion decoding module that leverages pre-trained diffusion models to further decode these content variables. To preserve the generative capability of pre-trained diffusion models, we keep their parameters fixed and use a control module to inject content information. We also design a space alignment loss to provide sufficient constraints for the latent feature-guided compression module. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches in terms of both visual performance and image fidelity at extremely low bitrates.
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024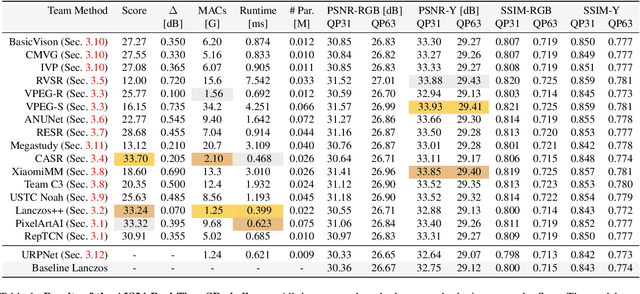
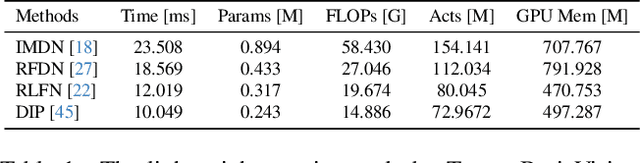
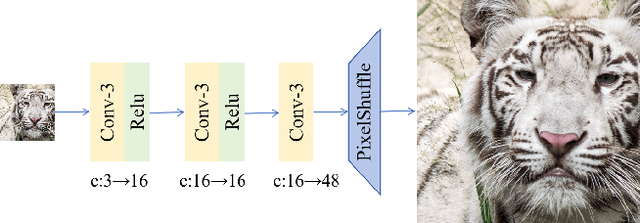
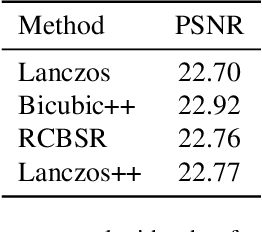
This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
Traditional Transformation Theory Guided Model for Learned Image Compression
Feb 24, 2024



Recently, many deep image compression methods have been proposed and achieved remarkable performance. However, these methods are dedicated to optimizing the compression performance and speed at medium and high bitrates, while research on ultra low bitrates is limited. In this work, we propose a ultra low bitrates enhanced invertible encoding network guided by traditional transformation theory, experiments show that our codec outperforms existing methods in both compression and reconstruction performance. Specifically, we introduce the Block Discrete Cosine Transformation to model the sparsity of features and employ traditional Haar transformation to improve the reconstruction performance of the model without increasing the bitstream cost.