 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS-YOLO: A Multi-Scale Model for Accurate and Efficient Blood Cell Detection
Jun 04, 2025Complete blood cell detection holds significant value in clinical diagnostics. Conventional manual microscopy methods suffer from time inefficiency and diagnostic inaccuracies. Existing automated detection approaches remain constrained by high deployment costs and suboptimal accuracy. While deep learning has introduced powerful paradigms to this field, persistent challenges in detecting overlapping cells and multi-scale objects hinder practical deployment. This study proposes the multi-scale YOLO (MS-YOLO), a blood cell detection model based on the YOLOv11 framework, incorporating three key architectural innovations to enhance detection performance. Specifically, the multi-scale dilated residual module (MS-DRM) replaces the original C3K2 modules to improve multi-scale discriminability; the dynamic cross-path feature enhancement module (DCFEM) enables the fusion of hierarchical features from the backbone with aggregated features from the neck to enhance feature representations; and the light adaptive-weight downsampling module (LADS) improves feature downsampling through adaptive spatial weighting while reducing computational complexity. Experimental results on the CBC benchmark demonstrate that MS-YOLO achieves precise detection of overlapping cells and multi-scale objects, particularly small targets such as platelets, achieving an mAP@50 of 97.4% that outperforms existing models. Further validation on the supplementary WBCDD dataset confirms its robust generalization capability. Additionally, with a lightweight architecture and real-time inference efficiency, MS-YOLO meets clinical deployment requirements, providing reliable technical support for standardized blood pathology assessment.
Diff9D: Diffusion-Based Domain-Generalized Category-Level 9-DoF Object Pose Estimation
Feb 04, 2025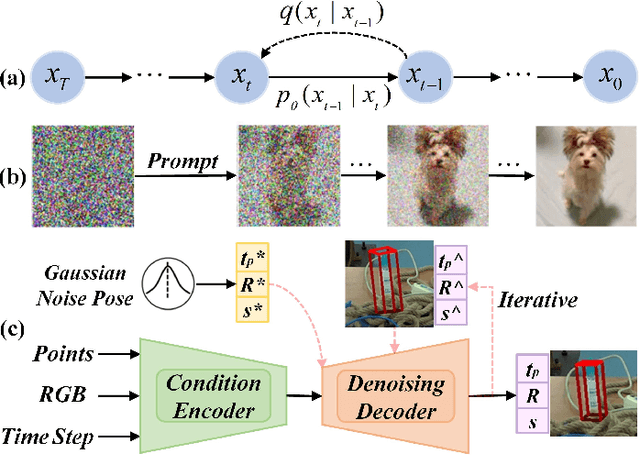
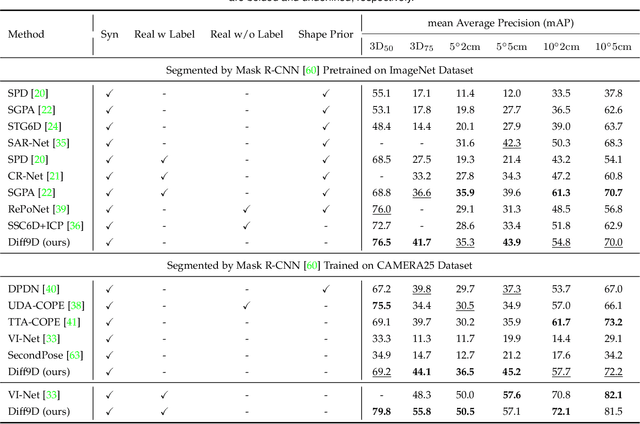

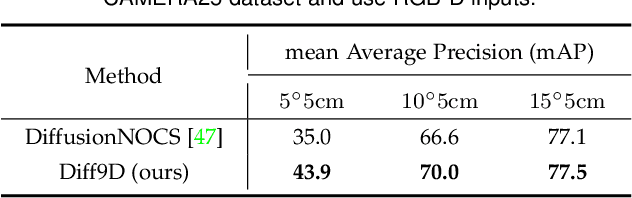
Nine-degrees-of-freedom (9-DoF) object pose and size estimation is crucial for enabling augmented reality and robotic manipulation. Category-level methods have received extensive research attention due to their potential for generalization to intra-class unknown objects. However, these methods require manual collection and labeling of large-scale real-world training data. To address this problem, we introduce a diffusion-based paradigm for domain-generalized category-level 9-DoF object pose estimation. Our motivation is to leverage the latent generalization ability of the diffusion model to address the domain generalization challenge in object pose estimation. This entails training the model exclusively on rendered synthetic data to achieve generalization to real-world scenes. We propose an effective diffusion model to redefine 9-DoF object pose estimation from a generative perspective. Our model does not require any 3D shape priors during training or inference. By employing the Denoising Diffusion Implicit Model, we demonstrate that the reverse diffusion process can be executed in as few as 3 steps, achieving near real-time performance. Finally, we design a robotic grasping system comprising both hardware and software components. Through comprehensive experiments on two benchmark datasets and the real-world robotic system, we show that our method achieves state-of-the-art domain generalization performance. Our code will be made public at https://github.com/CNJianLiu/Diff9D.
RGB Guided ToF Imaging System: A Survey of Deep Learning-based Methods
May 16, 2024Integrating an RGB camera into a ToF imaging system has become a significant technique for perceiving the real world. The RGB guided ToF imaging system is crucial to several applications, including face anti-spoofing, saliency detection, and trajectory prediction. Depending on the distance of the working range, the implementation schemes of the RGB guided ToF imaging systems are different. Specifically, ToF sensors with a uniform field of illumination, which can output dense depth but have low resolution, are typically used for close-range measurements. In contrast, LiDARs, which emit laser pulses and can only capture sparse depth, are usually employed for long-range detection. In the two cases, depth quality improvement for RGB guided ToF imaging corresponds to two sub-tasks: guided depth super-resolution and guided depth completion. In light of the recent significant boost to the field provided by deep learning, this paper comprehensively reviews the works related to RGB guided ToF imaging, including network structures, learning strategies, evaluation metrics, benchmark datasets, and objective functions. Besides, we present quantitative comparisons of state-of-the-art methods on widely used benchmark datasets. Finally, we discuss future trends and the challenges in real applications for further research.
Rethinking Blur Synthesis for Deep Real-World Image Deblurring
Sep 28, 2022
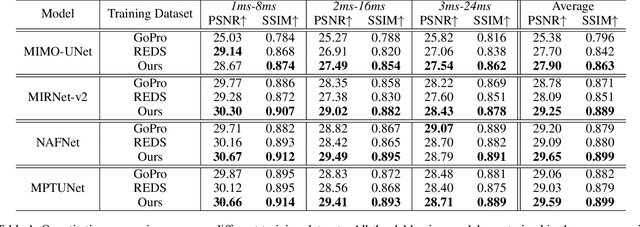

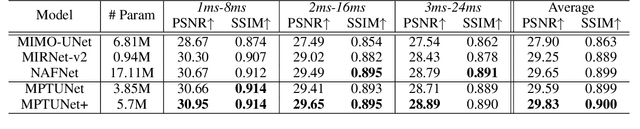
In this paper, we examine the problem of real-world image deblurring and take into account two key factors for improving the performance of the deep image deblurring model, namely, training data synthesis and network architecture design. Deblurring models trained on existing synthetic datasets perform poorly on real blurry images due to domain shift. To reduce the domain gap between synthetic and real domains, we propose a novel realistic blur synthesis pipeline to simulate the camera imaging process. As a result of our proposed synthesis method, existing deblurring models could be made more robust to handle real-world blur. Furthermore, we develop an effective deblurring model that captures non-local dependencies and local context in the feature domain simultaneously. Specifically, we introduce the multi-path transformer module to UNet architecture for enriched multi-scale features learning. A comprehensive experiment on three real-world datasets shows that the proposed deblurring model performs better than state-of-the-art methods.