 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSM-GS: Geometry-Constrained Single and Multi-view Gaussian Splatting for Surface Reconstruction
Feb 13, 2026Recently, 3D Gaussian Splatting has emerged as a prominent research direction owing to its ultrarapid training speed and high-fidelity rendering capabilities. However, the unstructured and irregular nature of Gaussian point clouds poses challenges to reconstruction accuracy. This limitation frequently causes high-frequency detail loss in complex surface microstructures when relying solely on routine strategies. To address this limitation, we propose GSM-GS: a synergistic optimization framework integrating single-view adaptive sub-region weighting constraints and multi-view spatial structure refinement. For single-view optimization, we leverage image gradient features to partition scenes into texture-rich and texture-less sub-regions. The reconstruction quality is enhanced through adaptive filtering mechanisms guided by depth discrepancy features. This preserves high-weight regions while implementing a dual-branch constraint strategy tailored to regional texture variations, thereby improving geometric detail characterization. For multi-view optimization, we introduce a geometry-guided cross-view point cloud association method combined with a dynamic weight sampling strategy. This constructs 3D structural normal constraints across adjacent point cloud frames, effectively reinforcing multi-view consistency and reconstruction fidelity. Extensive experiments on public datasets demonstrate that our method achieves both competitive rendering quality and geometric reconstruction. See our interactive project page
FSD-CAP: Fractional Subgraph Diffusion with Class-Aware Propagation for Graph Feature Imputation
Jan 26, 2026Imputing missing node features in graphs is challenging, particularly under high missing rates. Existing methods based on latent representations or global diffusion often fail to produce reliable estimates, and may propagate errors across the graph. We propose FSD-CAP, a two-stage framework designed to improve imputation quality under extreme sparsity. In the first stage, a graph-distance-guided subgraph expansion localizes the diffusion process. A fractional diffusion operator adjusts propagation sharpness based on local structure. In the second stage, imputed features are refined using class-aware propagation, which incorporates pseudo-labels and neighborhood entropy to promote consistency. We evaluated FSD-CAP on multiple datasets. With $99.5\%$ of features missing across five benchmark datasets, FSD-CAP achieves average accuracies of $80.06\%$ (structural) and $81.01\%$ (uniform) in node classification, close to the $81.31\%$ achieved by a standard GCN with full features. For link prediction under the same setting, it reaches AUC scores of $91.65\%$ (structural) and $92.41\%$ (uniform), compared to $95.06\%$ for the fully observed case. Furthermore, FSD-CAP demonstrates superior performance on both large-scale and heterophily datasets when compared to other models.
CometNet: Contextual Motif-guided Long-term Time Series Forecasting
Nov 11, 2025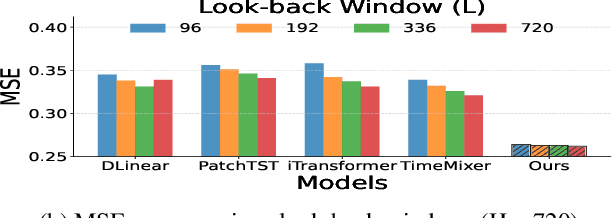
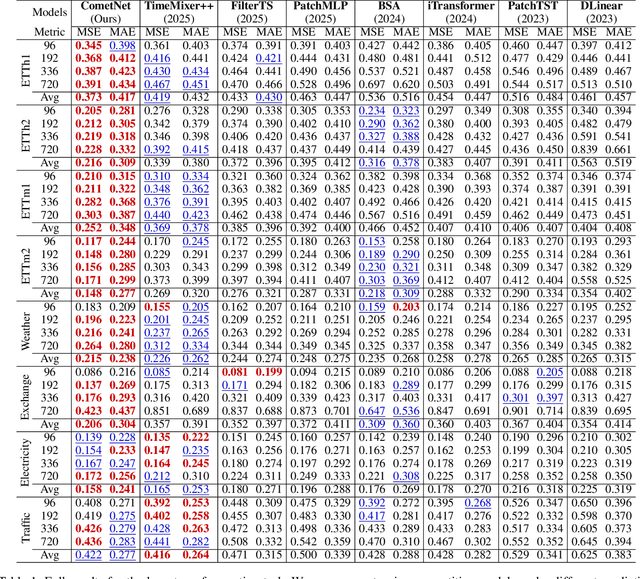
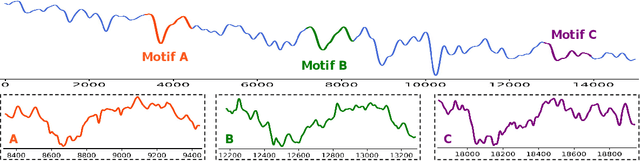
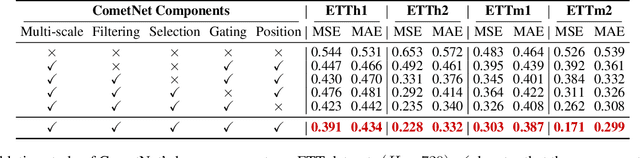
Long-term Time Series Forecasting is crucial across numerous critical domains, yet its accuracy remains fundamentally constrained by the receptive field bottleneck in existing models. Mainstream Transformer- and Multi-layer Perceptron (MLP)-based methods mainly rely on finite look-back windows, limiting their ability to model long-term dependencies and hurting forecasting performance. Naively extending the look-back window proves ineffective, as it not only introduces prohibitive computational complexity, but also drowns vital long-term dependencies in historical noise. To address these challenges, we propose CometNet, a novel Contextual Motif-guided Long-term Time Series Forecasting framework. CometNet first introduces a Contextual Motif Extraction module that identifies recurrent, dominant contextual motifs from complex historical sequences, providing extensive temporal dependencies far exceeding limited look-back windows; Subsequently, a Motif-guided Forecasting module is proposed, which integrates the extracted dominant motifs into forecasting. By dynamically mapping the look-back window to its relevant motifs, CometNet effectively harnesses their contextual information to strengthen long-term forecasting capability. Extensive experimental results on eight real-world datasets have demonstrated that CometNet significantly outperforms current state-of-the-art (SOTA) methods, particularly on extended forecast horizons.
RGB Guided ToF Imaging System: A Survey of Deep Learning-based Methods
May 16, 2024Integrating an RGB camera into a ToF imaging system has become a significant technique for perceiving the real world. The RGB guided ToF imaging system is crucial to several applications, including face anti-spoofing, saliency detection, and trajectory prediction. Depending on the distance of the working range, the implementation schemes of the RGB guided ToF imaging systems are different. Specifically, ToF sensors with a uniform field of illumination, which can output dense depth but have low resolution, are typically used for close-range measurements. In contrast, LiDARs, which emit laser pulses and can only capture sparse depth, are usually employed for long-range detection. In the two cases, depth quality improvement for RGB guided ToF imaging corresponds to two sub-tasks: guided depth super-resolution and guided depth completion. In light of the recent significant boost to the field provided by deep learning, this paper comprehensively reviews the works related to RGB guided ToF imaging, including network structures, learning strategies, evaluation metrics, benchmark datasets, and objective functions. Besides, we present quantitative comparisons of state-of-the-art methods on widely used benchmark datasets. Finally, we discuss future trends and the challenges in real applications for further research.
Depth Super-Resolution from Explicit and Implicit High-Frequency Features
Mar 16, 2023



We propose a novel multi-stage depth super-resolution network, which progressively reconstructs high-resolution depth maps from explicit and implicit high-frequency features. The former are extracted by an efficient transformer processing both local and global contexts, while the latter are obtained by projecting color images into the frequency domain. Both are combined together with depth features by means of a fusion strategy within a multi-stage and multi-scale framework. Experiments on the main benchmarks, such as NYUv2, Middlebury, DIML and RGBDD, show that our approach outperforms existing methods by a large margin (~20% on NYUv2 and DIML against the contemporary work DADA, with 16x upsampling), establishing a new state-of-the-art in the guided depth super-resolution task.
Rethinking Blur Synthesis for Deep Real-World Image Deblurring
Sep 28, 2022
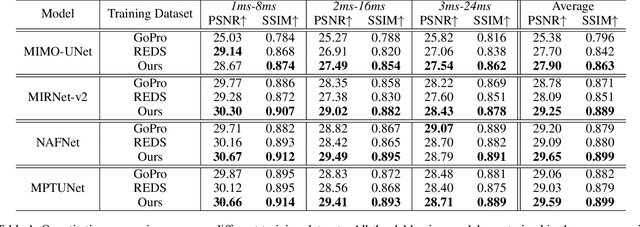

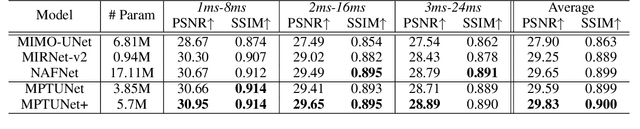
In this paper, we examine the problem of real-world image deblurring and take into account two key factors for improving the performance of the deep image deblurring model, namely, training data synthesis and network architecture design. Deblurring models trained on existing synthetic datasets perform poorly on real blurry images due to domain shift. To reduce the domain gap between synthetic and real domains, we propose a novel realistic blur synthesis pipeline to simulate the camera imaging process. As a result of our proposed synthesis method, existing deblurring models could be made more robust to handle real-world blur. Furthermore, we develop an effective deblurring model that captures non-local dependencies and local context in the feature domain simultaneously. Specifically, we introduce the multi-path transformer module to UNet architecture for enriched multi-scale features learning. A comprehensive experiment on three real-world datasets shows that the proposed deblurring model performs better than state-of-the-art methods.
Flexible Image Denoising with Multi-layer Conditional Feature Modulation
Jun 24, 2020
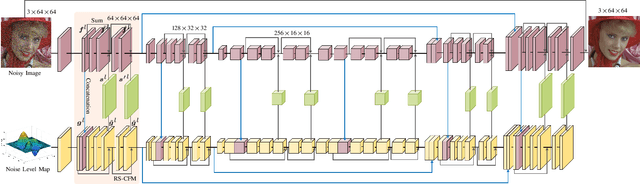


For flexible non-blind image denoising, existing deep networks usually take both noisy image and noise level map as the input to handle various noise levels with a single model. However, in this kind of solution, the noise variance (i.e., noise level) is only deployed to modulate the first layer of convolution feature with channel-wise shifting, which is limited in balancing noise removal and detail preservation. In this paper, we present a novel flexible image enoising network (CFMNet) by equipping an U-Net backbone with multi-layer conditional feature modulation (CFM) modules. In comparison to channel-wise shifting only in the first layer, CFMNet can make better use of noise level information by deploying multiple layers of CFM. Moreover, each CFM module takes onvolutional features from both noisy image and noise level map as input for better trade-off between noise removal and detail preservation. Experimental results show that our CFMNet is effective in exploiting noise level information for flexible non-blind denoising, and performs favorably against the existing deep image denoising methods in terms of both quantitative metrics and visual quality.