 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoCarla: A High-Fidelity Driving Dataset for Generalizable Stereo
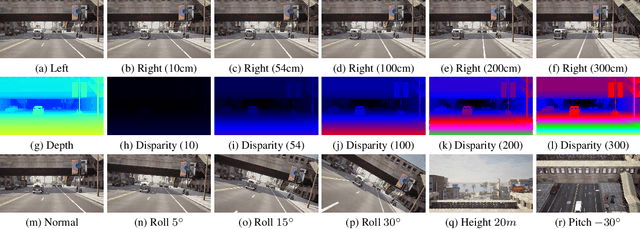
Sep 16, 2025Stereo matching plays a crucial role in enabling depth perception for autonomous driving and robotics. While recent years have witnessed remarkable progress in stereo matching algorithms, largely driven by learning-based methods and synthetic datasets, the generalization performance of these models remains constrained by the limited diversity of existing training data. To address these challenges, we present StereoCarla, a high-fidelity synthetic stereo dataset specifically designed for autonomous driving scenarios. Built on the CARLA simulator, StereoCarla incorporates a wide range of camera configurations, including diverse baselines, viewpoints, and sensor placements as well as varied environmental conditions such as lighting changes, weather effects, and road geometries. We conduct comprehensive cross-domain experiments across four standard evaluation datasets (KITTI2012, KITTI2015, Middlebury, ETH3D) and demonstrate that models trained on StereoCarla outperform those trained on 11 existing stereo datasets in terms of generalization accuracy across multiple benchmarks. Furthermore, when integrated into multi-dataset training, StereoCarla contributes substantial improvements to generalization accuracy, highlighting its compatibility and scalability. This dataset provides a valuable benchmark for developing and evaluating stereo algorithms under realistic, diverse, and controllable settings, facilitating more robust depth perception systems for autonomous vehicles. Code can be available at https://github.com/XiandaGuo/OpenStereo, and data can be available at https://xiandaguo.net/StereoCarla.
Adaptive Fault-tolerant Control of Underwater Vehicles with Thruster Failures
Apr 22, 2025
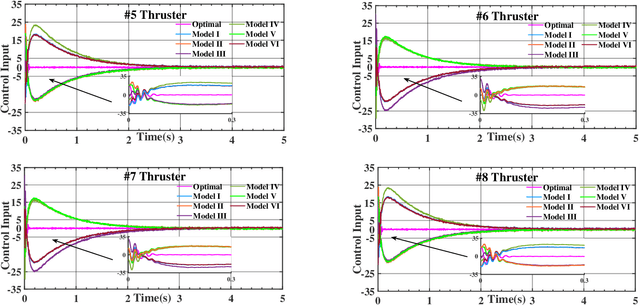
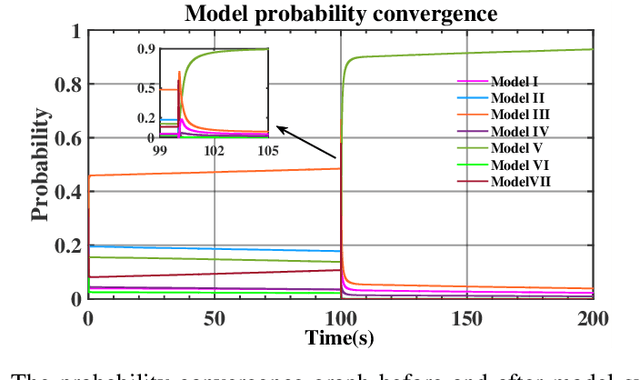
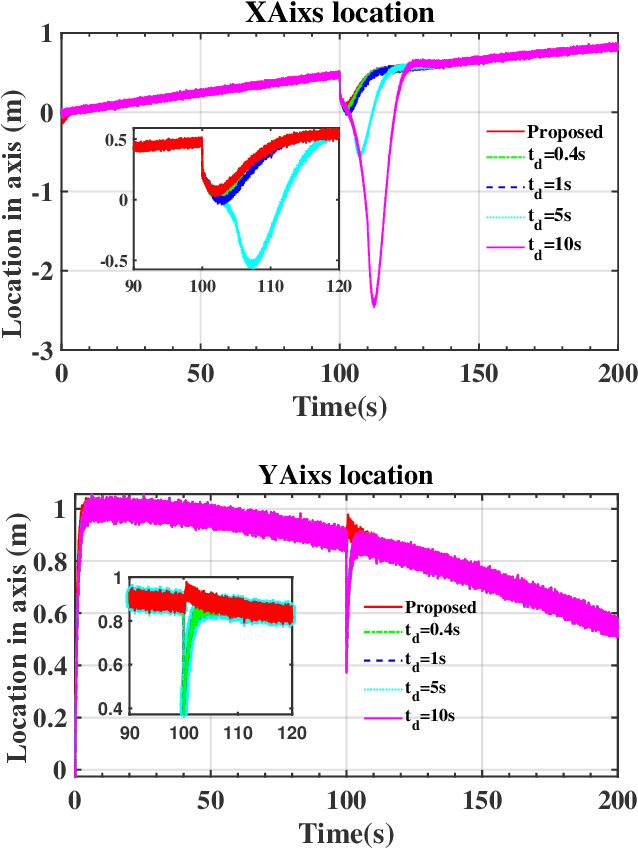
This paper presents a fault-tolerant control for the trajectory tracking of autonomous underwater vehicles (AUVs) against thruster failures. We formulate faults in AUV thrusters as discrete switching events during a UAV mission, and develop a soft-switching approach in facilitating shift of control strategies across fault scenarios. We mathematically define AUV thruster fault scenarios, and develop the fault-tolerant control that captures the fault scenario via Bayesian approach. Particularly, when the AUV fault type switches from one to another, the developed control captures the fault states and maintains the control by a linear quadratic tracking controller. With the captured fault states by Bayesian approach, we derive the control law by aggregating the control outputs for individual fault scenarios weighted by their Bayesian posterior probability. The developed fault-tolerant control works in an adaptive way and guarantees soft-switching across fault scenarios, and requires no complicated fault detection dedicated to different type of faults. The entailed soft-switching ensures stable AUV trajectory tracking when fault type shifts, which otherwise leads to reduced control under hard-switching control strategies. We conduct numerical simulations with diverse AUV thruster fault settings. The results demonstrate that the proposed control can provide smooth transition across thruster failures, and effectively sustain AUV trajectory tracking control in case of thruster failures and failure shifts.
HS-SLAM: Hybrid Representation with Structural Supervision for Improved Dense SLAM
Mar 27, 2025NeRF-based SLAM has recently achieved promising results in tracking and reconstruction. However, existing methods face challenges in providing sufficient scene representation, capturing structural information, and maintaining global consistency in scenes emerging significant movement or being forgotten. To this end, we present HS-SLAM to tackle these problems. To enhance scene representation capacity, we propose a hybrid encoding network that combines the complementary strengths of hash-grid, tri-planes, and one-blob, improving the completeness and smoothness of reconstruction. Additionally, we introduce structural supervision by sampling patches of non-local pixels rather than individual rays to better capture the scene structure. To ensure global consistency, we implement an active global bundle adjustment (BA) to eliminate camera drifts and mitigate accumulative errors. Experimental results demonstrate that HS-SLAM outperforms the baselines in tracking and reconstruction accuracy while maintaining the efficiency required for robotics.
A Text-Based Knowledge-Embedded Soft Sensing Modeling Approach for General Industrial Process Tasks Based on Large Language Model
Jan 09, 2025Data-driven soft sensors (DDSS) have become mainstream methods for predicting key performance indicators in process industries. However, DDSS development requires complex and costly customized designs tailored to various tasks during the modeling process. Moreover, DDSS are constrained to a single structured data modality, limiting their ability to incorporate additional contextual knowledge. Furthermore, DDSSs' limited representation learning leads to weak predictive performance with scarce data. To address these challenges, we propose a general framework named LLM-TKESS (large language model for text-based knowledge-embedded soft sensing), harnessing the powerful general problem-solving capabilities, cross-modal knowledge transfer abilities, and few-shot capabilities of LLM for enhanced soft sensing modeling. Specifically, an auxiliary variable series encoder (AVS Encoder) is proposed to unleash LLM's potential for capturing temporal relationships within series and spatial semantic relationships among auxiliary variables. Then, we propose a two-stage fine-tuning alignment strategy: in the first stage, employing parameter-efficient fine-tuning through autoregressive training adjusts LLM to rapidly accommodate process variable data, resulting in a soft sensing foundation model (SSFM). Subsequently, by training adapters, we adapt the SSFM to various downstream tasks without modifying its architecture. Then, we propose two text-based knowledge-embedded soft sensors, integrating new natural language modalities to overcome the limitations of pure structured data models. Furthermore, benefiting from LLM's pre-existing world knowledge, our model demonstrates outstanding predictive capabilities in small sample conditions. Using the thermal deformation of air preheater rotor as a case study, we validate through extensive experiments that LLM-TKESS exhibits outstanding performance.
A Soft Sensor Method with Uncertainty-Awareness and Self-Explanation Based on Large Language Models Enhanced by Domain Knowledge Retrieval
Jan 08, 2025



Data-driven soft sensors are crucial in predicting key performance indicators in industrial systems. However, current methods predominantly rely on the supervised learning paradigms of parameter updating, which inherently faces challenges such as high development costs, poor robustness, training instability, and lack of interpretability. Recently, large language models (LLMs) have demonstrated significant potential across various domains, notably through In-Context Learning (ICL), which enables high-performance task execution with minimal input-label demonstrations and no prior training. This paper aims to replace supervised learning with the emerging ICL paradigm for soft sensor modeling to address existing challenges and explore new avenues for advancement. To achieve this, we propose a novel framework called the Few-shot Uncertainty-aware and self-Explaining Soft Sensor (LLM-FUESS), which includes the Zero-shot Auxiliary Variable Selector (LLM-ZAVS) and the Uncertainty-aware Few-shot Soft Sensor (LLM-UFSS). The LLM-ZAVS retrieves from the Industrial Knowledge Vector Storage to enhance LLMs' domain-specific knowledge, enabling zero-shot auxiliary variable selection. In the LLM-UFSS, we utilize text-based context demonstrations of structured data to prompt LLMs to execute ICL for predicting and propose a context sample retrieval augmentation strategy to improve performance. Additionally, we explored LLMs' AIGC and probabilistic characteristics to propose self-explanation and uncertainty quantification methods for constructing a trustworthy soft sensor. Extensive experiments demonstrate that our method achieved state-of-the-art predictive performance, strong robustness, and flexibility, effectively mitigates training instability found in traditional methods. To the best of our knowledge, this is the first work to establish soft sensor utilizing LLMs.
Stereo Anything: Unifying Stereo Matching with Large-Scale Mixed Data
Nov 21, 2024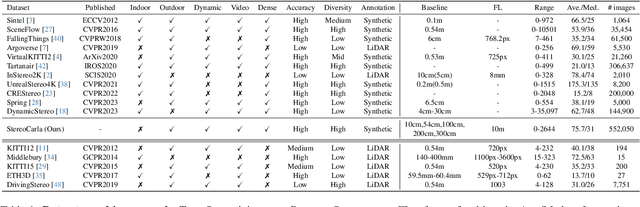

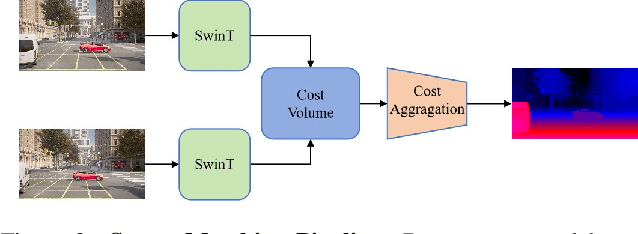
Stereo matching has been a pivotal component in 3D vision, aiming to find corresponding points between pairs of stereo images to recover depth information. In this work, we introduce StereoAnything, a highly practical solution for robust stereo matching. Rather than focusing on a specialized model, our goal is to develop a versatile foundational model capable of handling stereo images across diverse environments. To this end, we scale up the dataset by collecting labeled stereo images and generating synthetic stereo pairs from unlabeled monocular images. To further enrich the model's ability to generalize across different conditions, we introduce a novel synthetic dataset that complements existing data by adding variability in baselines, camera angles, and scene types. We extensively evaluate the zero-shot capabilities of our model on five public datasets, showcasing its impressive ability to generalize to new, unseen data. Code will be available at \url{https://github.com/XiandaGuo/OpenStereo}.
LightStereo: Channel Boost Is All Your Need for Efficient 2D Cost Aggregation
Jun 28, 2024We present LightStereo, a cutting-edge stereo-matching network crafted to accelerate the matching process. Departing from conventional methodologies that rely on aggregating computationally intensive 4D costs, LightStereo adopts the 3D cost volume as a lightweight alternative. While similar approaches have been explored previously, our breakthrough lies in enhancing performance through a dedicated focus on the channel dimension of the 3D cost volume, where the distribution of matching costs is encapsulated. Our exhaustive exploration has yielded plenty of strategies to amplify the capacity of the pivotal dimension, ensuring both precision and efficiency. We compare the proposed LightStereo with existing state-of-the-art methods across various benchmarks, which demonstrate its superior performance in speed, accuracy, and resource utilization. LightStereo achieves a competitive EPE metric in the SceneFlow datasets while demanding a minimum of only 22 GFLOPs, with an inference time of just 17 ms. Our comprehensive analysis reveals the effect of 2D cost aggregation for stereo matching, paving the way for real-world applications of efficient stereo systems. Code will be available at \url{https://github.com/XiandaGuo/OpenStereo}.
Learning Temporally Consistent Video Depth from Video Diffusion Priors
Jun 04, 2024This work addresses the challenge of video depth estimation, which expects not only per-frame accuracy but, more importantly, cross-frame consistency. Instead of directly developing a depth estimator from scratch, we reformulate the prediction task into a conditional generation problem. This allows us to leverage the prior knowledge embedded in existing video generation models, thereby reducing learning difficulty and enhancing generalizability. Concretely, we study how to tame the public Stable Video Diffusion (SVD) to predict reliable depth from input videos using a mixture of image depth and video depth datasets. We empirically confirm that a procedural training strategy -- first optimizing the spatial layers of SVD and then optimizing the temporal layers while keeping the spatial layers frozen -- yields the best results in terms of both spatial accuracy and temporal consistency. We further examine the sliding window strategy for inference on arbitrarily long videos. Our observations indicate a trade-off between efficiency and performance, with a one-frame overlap already producing favorable results. Extensive experimental results demonstrate the superiority of our approach, termed ChronoDepth, over existing alternatives, particularly in terms of the temporal consistency of the estimated depth. Additionally, we highlight the benefits of more consistent video depth in two practical applications: depth-conditioned video generation and novel view synthesis. Our project page is available at https://jhaoshao.github.io/ChronoDepth/.
A Tutorial on Gaussian Process Learning-based Model Predictive Control
Apr 02, 2024



This tutorial provides a systematic introduction to Gaussian process learning-based model predictive control (GP-MPC), an advanced approach integrating Gaussian process (GP) with model predictive control (MPC) for enhanced control in complex systems. It begins with GP regression fundamentals, illustrating how it enriches MPC with enhanced predictive accuracy and robust handling of uncertainties. A central contribution of this tutorial is the first detailed, systematic mathematical formulation of GP-MPC in literature, focusing on deriving the approximation of means and variances propagation for GP multi-step predictions. Practical applications in robotics control, such as path-following for mobile robots in challenging terrains and mixed-vehicle platooning, are discussed to demonstrate the real-world effectiveness and adaptability of GP-MPC. This tutorial aims to make GP-MPC accessible to researchers and practitioners, enriching the learning-based control field with in-depth theoretical and practical insights and fostering further innovations in complex system control.
GlORIE-SLAM: Globally Optimized RGB-only Implicit Encoding Point Cloud SLAM
Mar 30, 2024



Recent advancements in RGB-only dense Simultaneous Localization and Mapping (SLAM) have predominantly utilized grid-based neural implicit encodings and/or struggle to efficiently realize global map and pose consistency. To this end, we propose an efficient RGB-only dense SLAM system using a flexible neural point cloud scene representation that adapts to keyframe poses and depth updates, without needing costly backpropagation. Another critical challenge of RGB-only SLAM is the lack of geometric priors. To alleviate this issue, with the aid of a monocular depth estimator, we introduce a novel DSPO layer for bundle adjustment which optimizes the pose and depth of keyframes along with the scale of the monocular depth. Finally, our system benefits from loop closure and online global bundle adjustment and performs either better or competitive to existing dense neural RGB SLAM methods in tracking, mapping and rendering accuracy on the Replica, TUM-RGBD and ScanNet datasets. The source code will be made available.