 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWMNav: Integrating Vision-Language Models into World Models for Object Goal Navigation
Mar 04, 2025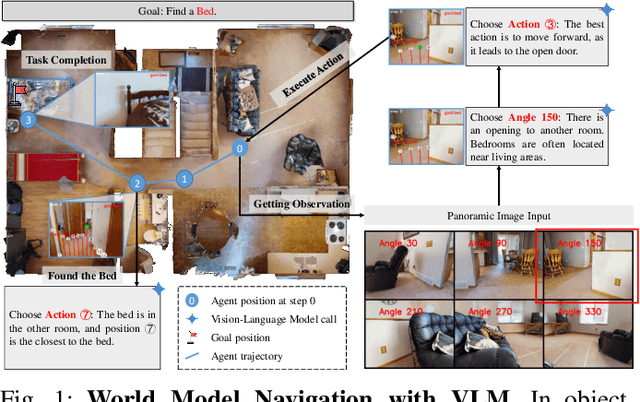
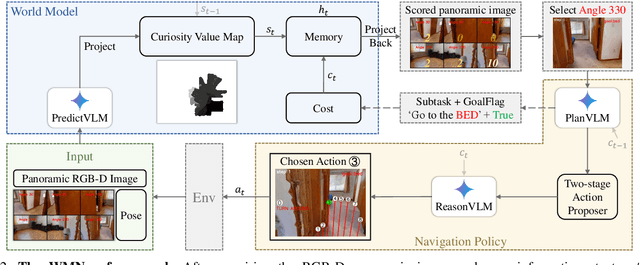
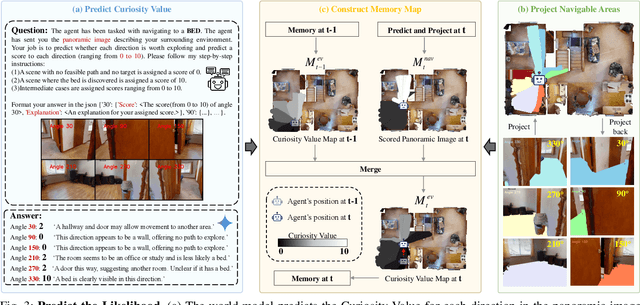

Object Goal Navigation-requiring an agent to locate a specific object in an unseen environment-remains a core challenge in embodied AI. Although recent progress in Vision-Language Model (VLM)-based agents has demonstrated promising perception and decision-making abilities through prompting, none has yet established a fully modular world model design that reduces risky and costly interactions with the environment by predicting the future state of the world. We introduce WMNav, a novel World Model-based Navigation framework powered by Vision-Language Models (VLMs). It predicts possible outcomes of decisions and builds memories to provide feedback to the policy module. To retain the predicted state of the environment, WMNav proposes the online maintained Curiosity Value Map as part of the world model memory to provide dynamic configuration for navigation policy. By decomposing according to a human-like thinking process, WMNav effectively alleviates the impact of model hallucination by making decisions based on the feedback difference between the world model plan and observation. To further boost efficiency, we implement a two-stage action proposer strategy: broad exploration followed by precise localization. Extensive evaluation on HM3D and MP3D validates WMNav surpasses existing zero-shot benchmarks in both success rate and exploration efficiency (absolute improvement: +3.2% SR and +3.2% SPL on HM3D, +13.5% SR and +1.1% SPL on MP3D). Project page: https://b0b8k1ng.github.io/WMNav/.
Stereo Anything: Unifying Stereo Matching with Large-Scale Mixed Data
Nov 21, 2024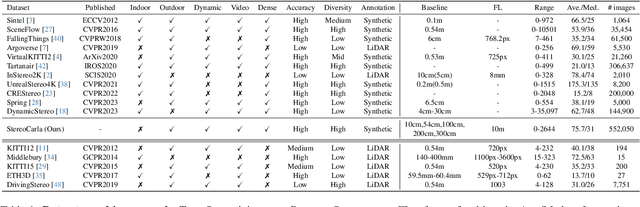
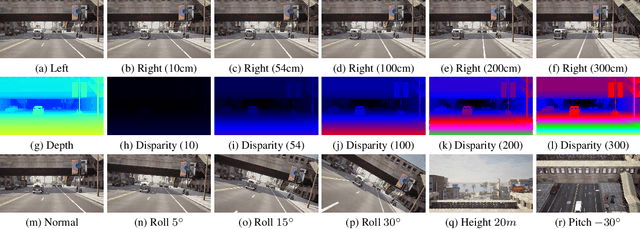

Stereo matching has been a pivotal component in 3D vision, aiming to find corresponding points between pairs of stereo images to recover depth information. In this work, we introduce StereoAnything, a highly practical solution for robust stereo matching. Rather than focusing on a specialized model, our goal is to develop a versatile foundational model capable of handling stereo images across diverse environments. To this end, we scale up the dataset by collecting labeled stereo images and generating synthetic stereo pairs from unlabeled monocular images. To further enrich the model's ability to generalize across different conditions, we introduce a novel synthetic dataset that complements existing data by adding variability in baselines, camera angles, and scene types. We extensively evaluate the zero-shot capabilities of our model on five public datasets, showcasing its impressive ability to generalize to new, unseen data. Code will be available at \url{https://github.com/XiandaGuo/OpenStereo}.
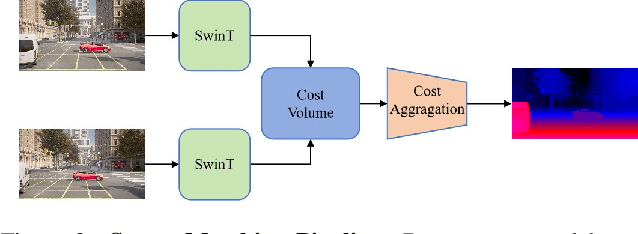
LightStereo: Channel Boost Is All Your Need for Efficient 2D Cost Aggregation
Jun 28, 2024We present LightStereo, a cutting-edge stereo-matching network crafted to accelerate the matching process. Departing from conventional methodologies that rely on aggregating computationally intensive 4D costs, LightStereo adopts the 3D cost volume as a lightweight alternative. While similar approaches have been explored previously, our breakthrough lies in enhancing performance through a dedicated focus on the channel dimension of the 3D cost volume, where the distribution of matching costs is encapsulated. Our exhaustive exploration has yielded plenty of strategies to amplify the capacity of the pivotal dimension, ensuring both precision and efficiency. We compare the proposed LightStereo with existing state-of-the-art methods across various benchmarks, which demonstrate its superior performance in speed, accuracy, and resource utilization. LightStereo achieves a competitive EPE metric in the SceneFlow datasets while demanding a minimum of only 22 GFLOPs, with an inference time of just 17 ms. Our comprehensive analysis reveals the effect of 2D cost aggregation for stereo matching, paving the way for real-world applications of efficient stereo systems. Code will be available at \url{https://github.com/XiandaGuo/OpenStereo}.