 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatch-Any-Events: Zero-Shot Motion-Robust Feature Matching Across Wide Baselines for Event Cameras
Apr 20, 2026Event cameras have recently shown promising capabilities in instantaneous motion estimation due to their robustness to low light and fast motions. However, computing wide-baseline correspondence between two arbitrary views remains a significant challenge, since event appearance changes substantially with motion, and learning-based approaches are constrained by both scalability and limited wide-baseline supervision. We therefore introduce the first event matching model that achieves cross-dataset wide-baseline correspondence in a zero-shot manner: a single model trained once is deployed on unseen datasets without any target-domain fine-tuning or adaptation. To enable this capability, we introduce a motion-robust and computationally efficient attention backbone that learns multi-timescale features from event streams, augmented with sparsity-aware event token selection, making large-scale training on diverse wide-baseline supervision computationally feasible. To provide the supervision needed for wide-baseline generalization, we develop a robust event motion synthesis framework to generate large-scale event-matching datasets with augmented viewpoints, modalities, and motions. Extensive experiments across multiple benchmarks show that our framework achieves a 37.7% improvement over the previous best event feature matching methods. Code and data are available at: https://github.com/spikelab-jhu/Match-Any-Events.
A Multi-Robot Platform for Robotic Triage Combining Onboard Sensing and Foundation Models
Dec 09, 2025
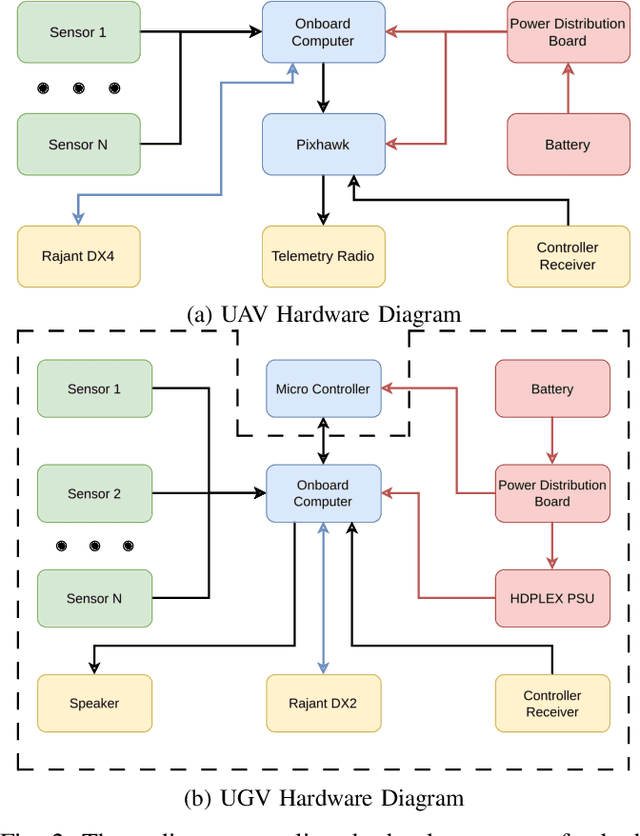
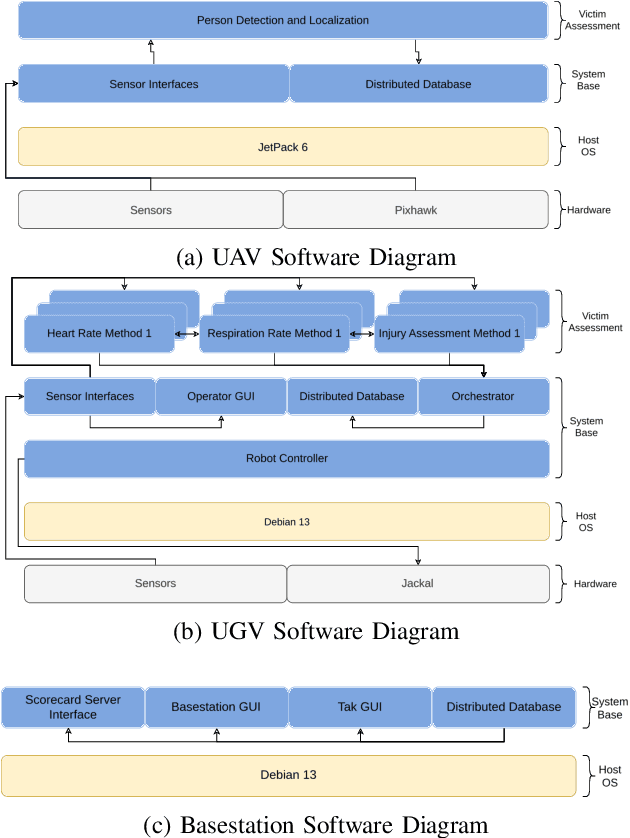
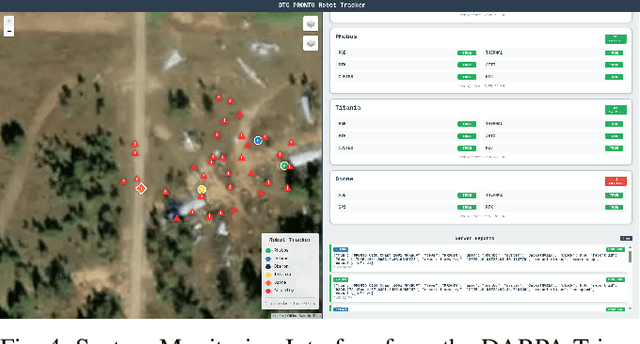
This report presents a heterogeneous robotic system designed for remote primary triage in mass-casualty incidents (MCIs). The system employs a coordinated air-ground team of unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs) to locate victims, assess their injuries, and prioritize medical assistance without risking the lives of first responders. The UAV identify and provide overhead views of casualties, while UGVs equipped with specialized sensors measure vital signs and detect and localize physical injuries. Unlike previous work that focused on exploration or limited medical evaluation, this system addresses the complete triage process: victim localization, vital sign measurement, injury severity classification, mental status assessment, and data consolidation for first responders. Developed as part of the DARPA Triage Challenge, this approach demonstrates how multi-robot systems can augment human capabilities in disaster response scenarios to maximize lives saved.
WMNav: Integrating Vision-Language Models into World Models for Object Goal Navigation
Mar 04, 2025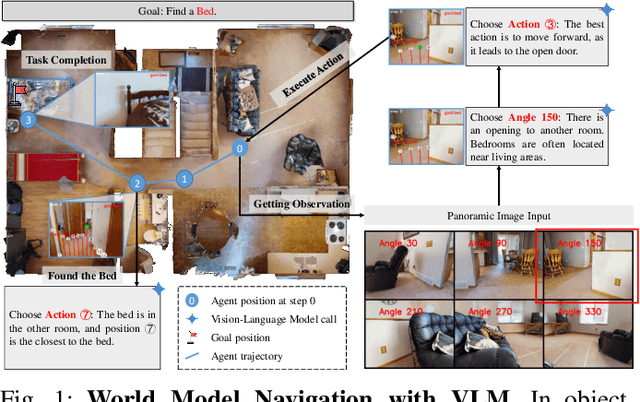
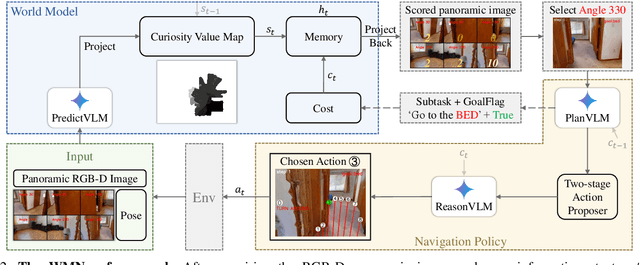
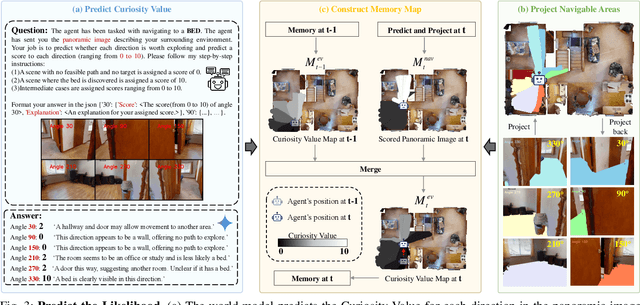

Object Goal Navigation-requiring an agent to locate a specific object in an unseen environment-remains a core challenge in embodied AI. Although recent progress in Vision-Language Model (VLM)-based agents has demonstrated promising perception and decision-making abilities through prompting, none has yet established a fully modular world model design that reduces risky and costly interactions with the environment by predicting the future state of the world. We introduce WMNav, a novel World Model-based Navigation framework powered by Vision-Language Models (VLMs). It predicts possible outcomes of decisions and builds memories to provide feedback to the policy module. To retain the predicted state of the environment, WMNav proposes the online maintained Curiosity Value Map as part of the world model memory to provide dynamic configuration for navigation policy. By decomposing according to a human-like thinking process, WMNav effectively alleviates the impact of model hallucination by making decisions based on the feedback difference between the world model plan and observation. To further boost efficiency, we implement a two-stage action proposer strategy: broad exploration followed by precise localization. Extensive evaluation on HM3D and MP3D validates WMNav surpasses existing zero-shot benchmarks in both success rate and exploration efficiency (absolute improvement: +3.2% SR and +3.2% SPL on HM3D, +13.5% SR and +1.1% SPL on MP3D). Project page: https://b0b8k1ng.github.io/WMNav/.
Continuous-Time Human Motion Field from Events
Dec 02, 2024This paper addresses the challenges of estimating a continuous-time human motion field from a stream of events. Existing Human Mesh Recovery (HMR) methods rely predominantly on frame-based approaches, which are prone to aliasing and inaccuracies due to limited temporal resolution and motion blur. In this work, we predict a continuous-time human motion field directly from events by leveraging a recurrent feed-forward neural network to predict human motion in the latent space of possible human motions. Prior state-of-the-art event-based methods rely on computationally intensive optimization across a fixed number of poses at high frame rates, which becomes prohibitively expensive as we increase the temporal resolution. In comparison, we present the first work that replaces traditional discrete-time predictions with a continuous human motion field represented as a time-implicit function, enabling parallel pose queries at arbitrary temporal resolutions. Despite the promises of event cameras, few benchmarks have tested the limit of high-speed human motion estimation. We introduce Beam-splitter Event Agile Human Motion Dataset-a hardware-synchronized high-speed human dataset to fill this gap. On this new data, our method improves joint errors by 23.8% compared to previous event human methods while reducing the computational time by 69%.
DriveMLLM: A Benchmark for Spatial Understanding with Multimodal Large Language Models in Autonomous Driving
Nov 20, 2024Autonomous driving requires a comprehensive understanding of 3D environments to facilitate high-level tasks such as motion prediction, planning, and mapping. In this paper, we introduce DriveMLLM, a benchmark specifically designed to evaluate the spatial understanding capabilities of multimodal large language models (MLLMs) in autonomous driving. DriveMLLM includes 2,734 front-facing camera images and introduces both absolute and relative spatial reasoning tasks, accompanied by linguistically diverse natural language questions. To measure MLLMs' performance, we propose novel evaluation metrics focusing on spatial understanding. We evaluate several state-of-the-art MLLMs on DriveMLLM, and our results reveal the limitations of current models in understanding complex spatial relationships in driving contexts. We believe these findings underscore the need for more advanced MLLM-based spatial reasoning methods and highlight the potential for DriveMLLM to drive further research in autonomous driving. Code will be available at \url{https://github.com/XiandaGuo/Drive-MLLM}.
Instruct Large Language Models to Drive like Humans
Jun 11, 2024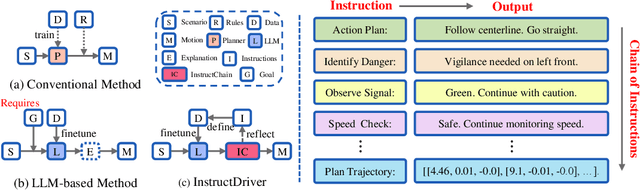
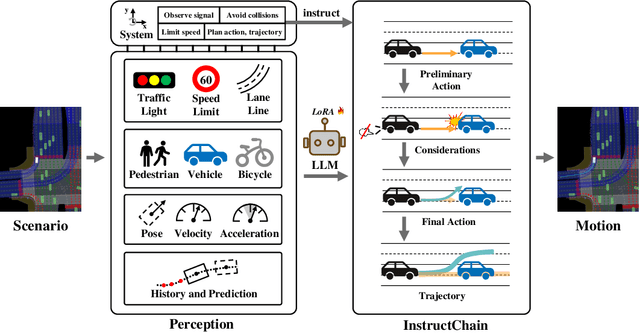

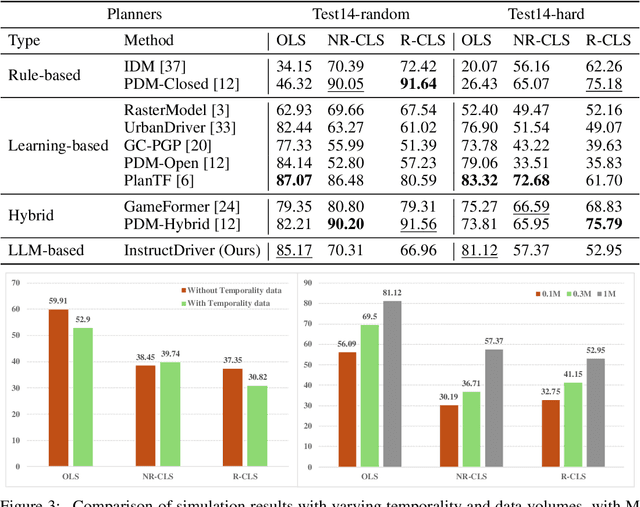
Motion planning in complex scenarios is the core challenge in autonomous driving. Conventional methods apply predefined rules or learn from driving data to plan the future trajectory. Recent methods seek the knowledge preserved in large language models (LLMs) and apply them in the driving scenarios. Despite the promising results, it is still unclear whether the LLM learns the underlying human logic to drive. In this paper, we propose an InstructDriver method to transform LLM into a motion planner with explicit instruction tuning to align its behavior with humans. We derive driving instruction data based on human logic (e.g., do not cause collisions) and traffic rules (e.g., proceed only when green lights). We then employ an interpretable InstructChain module to further reason the final planning reflecting the instructions. Our InstructDriver allows the injection of human rules and learning from driving data, enabling both interpretability and data scalability. Different from existing methods that experimented on closed-loop or simulated settings, we adopt the real-world closed-loop motion planning nuPlan benchmark for better evaluation. InstructDriver demonstrates the effectiveness of the LLM planner in a real-world closed-loop setting. Our code is publicly available at https://github.com/bonbon-rj/InstructDriver.