 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous-Time Human Motion Field from Events
Dec 02, 2024This paper addresses the challenges of estimating a continuous-time human motion field from a stream of events. Existing Human Mesh Recovery (HMR) methods rely predominantly on frame-based approaches, which are prone to aliasing and inaccuracies due to limited temporal resolution and motion blur. In this work, we predict a continuous-time human motion field directly from events by leveraging a recurrent feed-forward neural network to predict human motion in the latent space of possible human motions. Prior state-of-the-art event-based methods rely on computationally intensive optimization across a fixed number of poses at high frame rates, which becomes prohibitively expensive as we increase the temporal resolution. In comparison, we present the first work that replaces traditional discrete-time predictions with a continuous human motion field represented as a time-implicit function, enabling parallel pose queries at arbitrary temporal resolutions. Despite the promises of event cameras, few benchmarks have tested the limit of high-speed human motion estimation. We introduce Beam-splitter Event Agile Human Motion Dataset-a hardware-synchronized high-speed human dataset to fill this gap. On this new data, our method improves joint errors by 23.8% compared to previous event human methods while reducing the computational time by 69%.
EqNIO: Subequivariant Neural Inertial Odometry
Aug 12, 2024


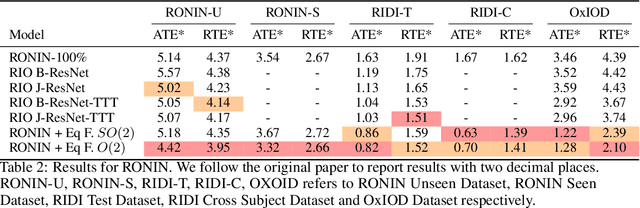
Presently, neural networks are widely employed to accurately estimate 2D displacements and associated uncertainties from Inertial Measurement Unit (IMU) data that can be integrated into stochastic filter networks like the Extended Kalman Filter (EKF) as measurements and uncertainties for the update step in the filter. However, such neural approaches overlook symmetry which is a crucial inductive bias for model generalization. This oversight is notable because (i) physical laws adhere to symmetry principles when considering the gravity axis, meaning there exists the same transformation for both the physical entity and the resulting trajectory, and (ii) displacements should remain equivariant to frame transformations when the inertial frame changes. To address this, we propose a subequivariant framework by: (i) deriving fundamental layers such as linear and nonlinear layers for a subequivariant network, designed to handle sequences of vectors and scalars, (ii) employing the subequivariant network to predict an equivariant frame for the sequence of inertial measurements. This predicted frame can then be utilized for extracting invariant features through projection, which are integrated with arbitrary network architectures, (iii) transforming the invariant output by frame transformation to obtain equivariant displacements and covariances. We demonstrate the effectiveness and generalization of our Equivariant Framework on a filter-based approach with TLIO architecture for TLIO and Aria datasets, and an end-to-end deep learning approach with RONIN architecture for RONIN, RIDI and OxIOD datasets.
Motion-prior Contrast Maximization for Dense Continuous-Time Motion Estimation
Jul 15, 2024Current optical flow and point-tracking methods rely heavily on synthetic datasets. Event cameras are novel vision sensors with advantages in challenging visual conditions, but state-of-the-art frame-based methods cannot be easily adapted to event data due to the limitations of current event simulators. We introduce a novel self-supervised loss combining the Contrast Maximization framework with a non-linear motion prior in the form of pixel-level trajectories and propose an efficient solution to solve the high-dimensional assignment problem between non-linear trajectories and events. Their effectiveness is demonstrated in two scenarios: In dense continuous-time motion estimation, our method improves the zero-shot performance of a synthetically trained model on the real-world dataset EVIMO2 by 29%. In optical flow estimation, our method elevates a simple UNet to achieve state-of-the-art performance among self-supervised methods on the DSEC optical flow benchmark. Our code is available at https://github.com/tub-rip/MotionPriorCMax.
* 24 pages, 8 figures, 8 tables, Project Page: https://github.com/tub-rip/MotionPriorCMax
Track Everything Everywhere Fast and Robustly
Mar 26, 2024



We propose a novel test-time optimization approach for efficiently and robustly tracking any pixel at any time in a video. The latest state-of-the-art optimization-based tracking technique, OmniMotion, requires a prohibitively long optimization time, rendering it impractical for downstream applications. OmniMotion is sensitive to the choice of random seeds, leading to unstable convergence. To improve efficiency and robustness, we introduce a novel invertible deformation network, CaDeX++, which factorizes the function representation into a local spatial-temporal feature grid and enhances the expressivity of the coupling blocks with non-linear functions. While CaDeX++ incorporates a stronger geometric bias within its architectural design, it also takes advantage of the inductive bias provided by the vision foundation models. Our system utilizes monocular depth estimation to represent scene geometry and enhances the objective by incorporating DINOv2 long-term semantics to regulate the optimization process. Our experiments demonstrate a substantial improvement in training speed (more than \textbf{10 times} faster), robustness, and accuracy in tracking over the SoTA optimization-based method OmniMotion.
TRAM: Global Trajectory and Motion of 3D Humans from in-the-wild Videos
Mar 26, 2024



We propose TRAM, a two-stage method to reconstruct a human's global trajectory and motion from in-the-wild videos. TRAM robustifies SLAM to recover the camera motion in the presence of dynamic humans and uses the scene background to derive the motion scale. Using the recovered camera as a metric-scale reference frame, we introduce a video transformer model (VIMO) to regress the kinematic body motion of a human. By composing the two motions, we achieve accurate recovery of 3D humans in the world space, reducing global motion errors by 60% from prior work. https://yufu-wang.github.io/tram4d/
Event-based Continuous Color Video Decompression from Single Frames
Nov 30, 2023



We present ContinuityCam, a novel approach to generate a continuous video from a single static RGB image, using an event camera. Conventional cameras struggle with high-speed motion capture due to bandwidth and dynamic range limitations. Event cameras are ideal sensors to solve this problem because they encode compressed change information at high temporal resolution. In this work, we propose a novel task called event-based continuous color video decompression, pairing single static color frames and events to reconstruct temporally continuous videos. Our approach combines continuous long-range motion modeling with a feature-plane-based synthesis neural integration model, enabling frame prediction at arbitrary times within the events. Our method does not rely on additional frames except for the initial image, increasing, thus, the robustness to sudden light changes, minimizing the prediction latency, and decreasing the bandwidth requirement. We introduce a novel single objective beamsplitter setup that acquires aligned images and events and a novel and challenging Event Extreme Decompression Dataset (E2D2) that tests the method in various lighting and motion profiles. We thoroughly evaluate our method through benchmarking reconstruction as well as various downstream tasks. Our approach significantly outperforms the event- and image- based baselines in the proposed task.
Un-EvMoSeg: Unsupervised Event-based Independent Motion Segmentation
Nov 30, 2023



Event cameras are a novel type of biologically inspired vision sensor known for their high temporal resolution, high dynamic range, and low power consumption. Because of these properties, they are well-suited for processing fast motions that require rapid reactions. Although event cameras have recently shown competitive performance in unsupervised optical flow estimation, performance in detecting independently moving objects (IMOs) is lacking behind, although event-based methods would be suited for this task based on their low latency and HDR properties. Previous approaches to event-based IMO segmentation have been heavily dependent on labeled data. However, biological vision systems have developed the ability to avoid moving objects through daily tasks without being given explicit labels. In this work, we propose the first event framework that generates IMO pseudo-labels using geometric constraints. Due to its unsupervised nature, our method can handle an arbitrary number of not predetermined objects and is easily scalable to datasets where expensive IMO labels are not readily available. We evaluate our approach on the EVIMO dataset and show that it performs competitively with supervised methods, both quantitatively and qualitatively.
EV-Catcher: High-Speed Object Catching Using Low-latency Event-based Neural Networks
Apr 14, 2023



Event-based sensors have recently drawn increasing interest in robotic perception due to their lower latency, higher dynamic range, and lower bandwidth requirements compared to standard CMOS-based imagers. These properties make them ideal tools for real-time perception tasks in highly dynamic environments. In this work, we demonstrate an application where event cameras excel: accurately estimating the impact location of fast-moving objects. We introduce a lightweight event representation called Binary Event History Image (BEHI) to encode event data at low latency, as well as a learning-based approach that allows real-time inference of a confidence-enabled control signal to the robot. To validate our approach, we present an experimental catching system in which we catch fast-flying ping-pong balls. We show that the system is capable of achieving a success rate of 81% in catching balls targeted at different locations, with a velocity of up to 13 m/s even on compute-constrained embedded platforms such as the Nvidia Jetson NX.
EvAC3D: From Event-based Apparent Contours to 3D Models via Continuous Visual Hulls
Apr 11, 20233D reconstruction from multiple views is a successful computer vision field with multiple deployments in applications. State of the art is based on traditional RGB frames that enable optimization of photo-consistency cross views. In this paper, we study the problem of 3D reconstruction from event-cameras, motivated by the advantages of event-based cameras in terms of low power and latency as well as by the biological evidence that eyes in nature capture the same data and still perceive well 3D shape. The foundation of our hypothesis that 3D reconstruction is feasible using events lies in the information contained in the occluding contours and in the continuous scene acquisition with events. We propose Apparent Contour Events (ACE), a novel event-based representation that defines the geometry of the apparent contour of an object. We represent ACE by a spatially and temporally continuous implicit function defined in the event x-y-t space. Furthermore, we design a novel continuous Voxel Carving algorithm enabled by the high temporal resolution of the Apparent Contour Events. To evaluate the performance of the method, we collect MOEC-3D, a 3D event dataset of a set of common real-world objects. We demonstrate the ability of EvAC3D to reconstruct high-fidelity mesh surfaces from real event sequences while allowing the refinement of the 3D reconstruction for each individual event.
Improving Load Forecast in Energy Markets During COVID-19
Oct 01, 2021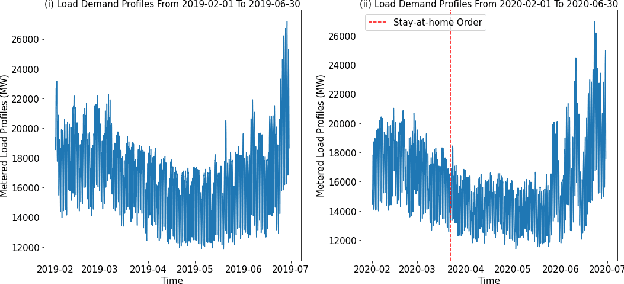


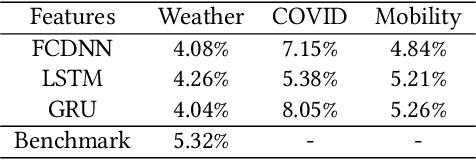
The abrupt outbreak of the COVID-19 pandemic was the most significant event in 2020, which had profound and lasting impacts across the world. Studies on energy markets observed a decline in energy demand and changes in energy consumption behaviors during COVID-19. However, as an essential part of system operation, how the load forecasting performs amid COVID-19 is not well understood. This paper aims to bridge the research gap by systematically evaluating models and features that can be used to improve the load forecasting performance amid COVID-19. Using real-world data from the New York Independent System Operator, our analysis employs three deep learning models and adopts both novel COVID-related features as well as classical weather-related features. We also propose simulating the stay-at-home situation with pre-stay-at-home weekend data and demonstrate its effectiveness in improving load forecasting accuracy during COVID-19.