 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventHub: Data Factory for Generalizable Event-Based Stereo Networks without Active Sensors
Apr 02, 2026We propose EventHub, a novel framework for training deep-event stereo networks without ground truth annotations from costly active sensors, relying instead on standard color images. From these images, we derive either proxy annotations and proxy events through state-of-the-art novel view synthesis techniques, or simply proxy annotations when images are already paired with event data. Using the training set generated by our data factory, we repurpose state-of-the-art stereo models from RGB literature to process event data, obtaining new event stereo models with unprecedented generalization capabilities. Experiments on widely used event stereo datasets support the effectiveness of EventHub and show how the same data distillation mechanism can improve the accuracy of RGB stereo foundation models in challenging conditions such as nighttime scenes.
Interp3R: Continuous-time 3D Geometry Estimation with Frames and Events
Mar 15, 2026In recent years, 3D visual foundation models pioneered by pointmap-based approaches such as DUSt3R have attracted a lot of interest, achieving impressive accuracy and strong generalization across diverse scenes. However, these methods are inherently limited to recovering scene geometry only at the discrete time instants when images are captured, leaving the scene evolution during the blind time between consecutive frames largely unexplored. We introduce Interp3R, to the best of our knowledge the first method that enhances pointmap-based models to estimate depth and camera poses at arbitrary time instants. Interp3R leverages asynchronous event data to interpolate pointmaps produced by frame-based models, enabling temporally continuous geometric representations. Depth and camera poses are then jointly recovered by aligning the interpolated pointmaps together with those predicted by the underlying frame-based models into a consistent spatial framework. We train Interp3R exclusively on a synthetic dataset, yet demonstrate strong generalization across a wide range of synthetic and real-world benchmarks. Extensive experiments show that Interp3R outperforms by a considerable margin state-of-the-art baselines that follow a two-stage pipeline of 2D video frame interpolation followed by 3D geometry estimation.
Geometric-Photometric Event-based 3D Gaussian Ray Tracing
Dec 21, 2025Event cameras offer a high temporal resolution over traditional frame-based cameras, which makes them suitable for motion and structure estimation. However, it has been unclear how event-based 3D Gaussian Splatting (3DGS) approaches could leverage fine-grained temporal information of sparse events. This work proposes a framework to address the trade-off between accuracy and temporal resolution in event-based 3DGS. Our key idea is to decouple the rendering into two branches: event-by-event geometry (depth) rendering and snapshot-based radiance (intensity) rendering, by using ray-tracing and the image of warped events. The extensive evaluation shows that our method achieves state-of-the-art performance on the real-world datasets and competitive performance on the synthetic dataset. Also, the proposed method works without prior information (e.g., pretrained image reconstruction models) or COLMAP-based initialization, is more flexible in the event selection number, and achieves sharp reconstruction on scene edges with fast training time. We hope that this work deepens our understanding of the sparse nature of events for 3D reconstruction. The code will be released.
Iterative Event-based Motion Segmentation by Variational Contrast Maximization
Apr 25, 2025Event cameras provide rich signals that are suitable for motion estimation since they respond to changes in the scene. As any visual changes in the scene produce event data, it is paramount to classify the data into different motions (i.e., motion segmentation), which is useful for various tasks such as object detection and visual servoing. We propose an iterative motion segmentation method, by classifying events into background (e.g., dominant motion hypothesis) and foreground (independent motion residuals), thus extending the Contrast Maximization framework. Experimental results demonstrate that the proposed method successfully classifies event clusters both for public and self-recorded datasets, producing sharp, motion-compensated edge-like images. The proposed method achieves state-of-the-art accuracy on moving object detection benchmarks with an improvement of over 30%, and demonstrates its possibility of applying to more complex and noisy real-world scenes. We hope this work broadens the sensitivity of Contrast Maximization with respect to both motion parameters and input events, thus contributing to theoretical advancements in event-based motion segmentation estimation. https://github.com/aoki-media-lab/event_based_segmentation_vcmax
DERD-Net: Learning Depth from Event-based Ray Densities
Apr 22, 2025



Event cameras offer a promising avenue for multi-view stereo depth estimation and Simultaneous Localization And Mapping (SLAM) due to their ability to detect blur-free 3D edges at high-speed and over broad illumination conditions. However, traditional deep learning frameworks designed for conventional cameras struggle with the asynchronous, stream-like nature of event data, as their architectures are optimized for discrete, image-like inputs. We propose a scalable, flexible and adaptable framework for pixel-wise depth estimation with event cameras in both monocular and stereo setups. The 3D scene structure is encoded into disparity space images (DSIs), representing spatial densities of rays obtained by back-projecting events into space via known camera poses. Our neural network processes local subregions of the DSIs combining 3D convolutions and a recurrent structure to recognize valuable patterns for depth prediction. Local processing enables fast inference with full parallelization and ensures constant ultra-low model complexity and memory costs, regardless of camera resolution. Experiments on standard benchmarks (MVSEC and DSEC datasets) demonstrate unprecedented effectiveness: (i) using purely monocular data, our method achieves comparable results to existing stereo methods; (ii) when applied to stereo data, it strongly outperforms all state-of-the-art (SOTA) approaches, reducing the mean absolute error by at least 42%; (iii) our method also allows for increases in depth completeness by more than 3-fold while still yielding a reduction in median absolute error of at least 30%. Given its remarkable performance and effective processing of event-data, our framework holds strong potential to become a standard approach for using deep learning for event-based depth estimation and SLAM. Project page: https://github.com/tub-rip/DERD-Net
Simultaneous Motion And Noise Estimation with Event Cameras
Apr 05, 2025



Event cameras are emerging vision sensors, whose noise is challenging to characterize. Existing denoising methods for event cameras consider other tasks such as motion estimation separately (i.e., sequentially after denoising). However, motion is an intrinsic part of event data, since scene edges cannot be sensed without motion. This work proposes, to the best of our knowledge, the first method that simultaneously estimates motion in its various forms (e.g., ego-motion, optical flow) and noise. The method is flexible, as it allows replacing the 1-step motion estimation of the widely-used Contrast Maximization framework with any other motion estimator, such as deep neural networks. The experiments show that the proposed method achieves state-of-the-art results on the E-MLB denoising benchmark and competitive results on the DND21 benchmark, while showing its efficacy on motion estimation and intensity reconstruction tasks. We believe that the proposed approach contributes to strengthening the theory of event-data denoising, as well as impacting practical denoising use-cases, as we release the code upon acceptance. Project page: https://github.com/tub-rip/ESMD
Unsupervised Joint Learning of Optical Flow and Intensity with Event Cameras
Mar 21, 2025Event cameras rely on motion to obtain information about scene appearance. In other words, for event cameras, motion and appearance are seen both or neither, which are encoded in the output event stream. Previous works consider recovering these two visual quantities as separate tasks, which does not fit with the nature of event cameras and neglects the inherent relations between both tasks. In this paper, we propose an unsupervised learning framework that jointly estimates optical flow (motion) and image intensity (appearance), with a single network. Starting from the event generation model, we newly derive the event-based photometric error as a function of optical flow and image intensity, which is further combined with the contrast maximization framework, yielding a comprehensive loss function that provides proper constraints for both flow and intensity estimation. Exhaustive experiments show that our model achieves state-of-the-art performance for both optical flow (achieves 20% and 25% improvement in EPE and AE respectively in the unsupervised learning category) and intensity estimation (produces competitive results with other baselines, particularly in high dynamic range scenarios). Last but not least, our model achieves shorter inference time than all the other optical flow models and many of the image reconstruction models, while they output only one quantity. Project page: https://github.com/tub-rip/e2fai
Combined Physics and Event Camera Simulator for Slip Detection
Mar 05, 2025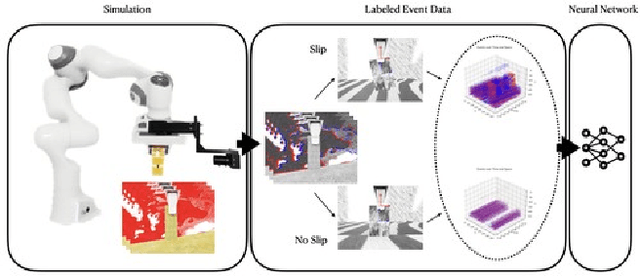
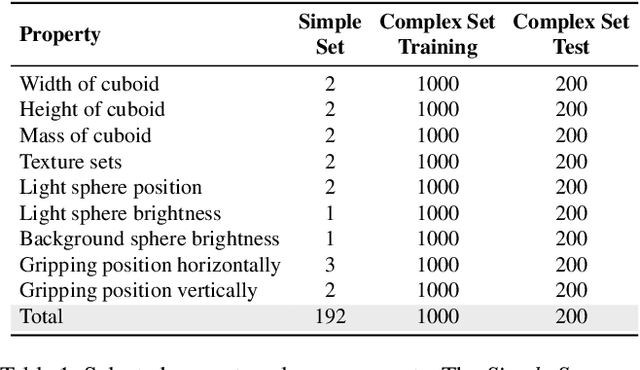
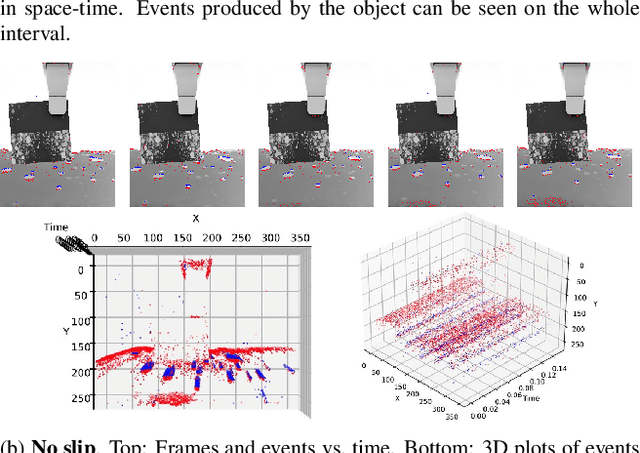
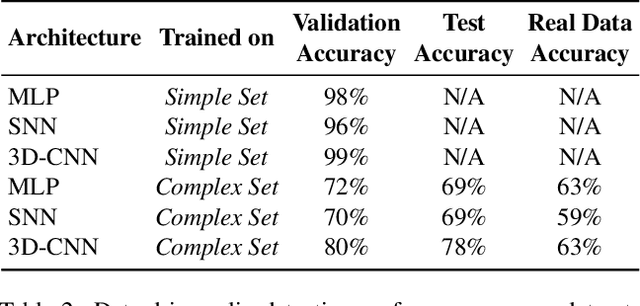
Robot manipulation is a common task in fields like industrial manufacturing. Detecting when objects slip from a robot's grasp is crucial for safe and reliable operation. Event cameras, which register pixel-level brightness changes at high temporal resolution (called ``events''), offer an elegant feature when mounted on a robot's end effector: since they only detect motion relative to their viewpoint, a properly grasped object produces no events, while a slipping object immediately triggers them. To research this feature, representative datasets are essential, both for analytic approaches and for training machine learning models. The majority of current research on slip detection with event-based data is done on real-world scenarios and manual data collection, as well as additional setups for data labeling. This can result in a significant increase in the time required for data collection, a lack of flexibility in scene setups, and a high level of complexity in the repetition of experiments. This paper presents a simulation pipeline for generating slip data using the described camera-gripper configuration in a robot arm, and demonstrates its effectiveness through initial data-driven experiments. The use of a simulator, once it is set up, has the potential to reduce the time spent on data collection, provide the ability to alter the setup at any time, simplify the process of repetition and the generation of arbitrarily large data sets. Two distinct datasets were created and validated through visual inspection and artificial neural networks (ANNs). Visual inspection confirmed photorealistic frame generation and accurate slip modeling, while three ANNs trained on this data achieved high validation accuracy and demonstrated good generalization capabilities on a separate test set, along with initial applicability to real-world data. Project page: https://github.com/tub-rip/event_slip
* 9 pages, 8 figures, 2 tables, https://github.com/tub-rip/event_slip
Event-based Photometric Bundle Adjustment
Dec 18, 2024



We tackle the problem of bundle adjustment (i.e., simultaneous refinement of camera poses and scene map) for a purely rotating event camera. Starting from first principles, we formulate the problem as a classical non-linear least squares optimization. The photometric error is defined using the event generation model directly in the camera rotations and the semi-dense scene brightness that triggers the events. We leverage the sparsity of event data to design a tractable Levenberg-Marquardt solver that handles the very large number of variables involved. To the best of our knowledge, our method, which we call Event-based Photometric Bundle Adjustment (EPBA), is the first event-only photometric bundle adjustment method that works on the brightness map directly and exploits the space-time characteristics of event data, without having to convert events into image-like representations. Comprehensive experiments on both synthetic and real-world datasets demonstrate EPBA's effectiveness in decreasing the photometric error (by up to 90%), yielding results of unparalleled quality. The refined maps reveal details that were hidden using prior state-of-the-art rotation-only estimation methods. The experiments on modern high-resolution event cameras show the applicability of EPBA to panoramic imaging in various scenarios (without map initialization, at multiple resolutions, and in combination with other methods, such as IMU dead reckoning or previous event-based rotation estimation methods). We make the source code publicly available. https://github.com/tub-rip/epba
Data Pruning Can Do More: A Comprehensive Data Pruning Approach for Object Re-identification
Dec 13, 2024



Previous studies have demonstrated that not each sample in a dataset is of equal importance during training. Data pruning aims to remove less important or informative samples while still achieving comparable results as training on the original (untruncated) dataset, thereby reducing storage and training costs. However, the majority of data pruning methods are applied to image classification tasks. To our knowledge, this work is the first to explore the feasibility of these pruning methods applied to object re-identification (ReID) tasks, while also presenting a more comprehensive data pruning approach. By fully leveraging the logit history during training, our approach offers a more accurate and comprehensive metric for quantifying sample importance, as well as correcting mislabeled samples and recognizing outliers. Furthermore, our approach is highly efficient, reducing the cost of importance score estimation by 10 times compared to existing methods. Our approach is a plug-and-play, architecture-agnostic framework that can eliminate/reduce 35%, 30%, and 5% of samples/training time on the VeRi, MSMT17 and Market1501 datasets, respectively, with negligible loss in accuracy (< 0.1%). The lists of important, mislabeled, and outlier samples from these ReID datasets are available at https://github.com/Zi-Y/data-pruning-reid.