 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Agentic Framework for Interpretable and Clinically Translatable Computational Pathology Biomarker Discovery
Feb 01, 2026Despite significant progress in computational pathology, many AI models remain black-box and difficult to interpret, posing a major barrier to clinical adoption due to limited transparency and explainability. This has motivated continued interest in engineered image-based biomarkers, which offer greater interpretability but are often proposed based on anecdotal evidence or fragmented prior literature rather than systematic biological validation. We introduce SAGE (Structured Agentic system for hypothesis Generation and Evaluation), an agentic AI system designed to identify interpretable, engineered pathology biomarkers by grounding them in biological evidence. SAGE integrates literature-anchored reasoning with multimodal data analysis to correlate image-derived features with molecular biomarkers, such as gene expression, and clinically relevant outcomes. By coordinating specialized agents for biological contextualization and empirical hypothesis validation, SAGE prioritizes transparent, biologically supported biomarkers and advances the clinical translation of computational pathology.
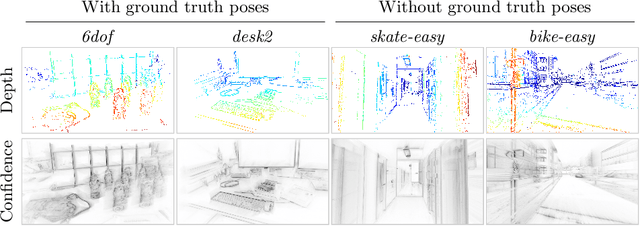
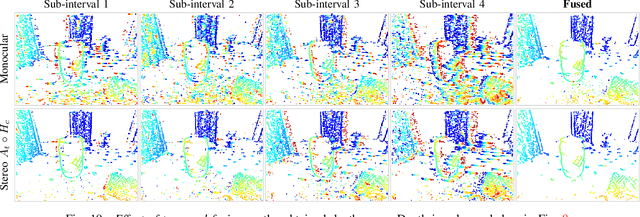
DERD-Net: Learning Depth from Event-based Ray Densities
Apr 22, 2025



Event cameras offer a promising avenue for multi-view stereo depth estimation and Simultaneous Localization And Mapping (SLAM) due to their ability to detect blur-free 3D edges at high-speed and over broad illumination conditions. However, traditional deep learning frameworks designed for conventional cameras struggle with the asynchronous, stream-like nature of event data, as their architectures are optimized for discrete, image-like inputs. We propose a scalable, flexible and adaptable framework for pixel-wise depth estimation with event cameras in both monocular and stereo setups. The 3D scene structure is encoded into disparity space images (DSIs), representing spatial densities of rays obtained by back-projecting events into space via known camera poses. Our neural network processes local subregions of the DSIs combining 3D convolutions and a recurrent structure to recognize valuable patterns for depth prediction. Local processing enables fast inference with full parallelization and ensures constant ultra-low model complexity and memory costs, regardless of camera resolution. Experiments on standard benchmarks (MVSEC and DSEC datasets) demonstrate unprecedented effectiveness: (i) using purely monocular data, our method achieves comparable results to existing stereo methods; (ii) when applied to stereo data, it strongly outperforms all state-of-the-art (SOTA) approaches, reducing the mean absolute error by at least 42%; (iii) our method also allows for increases in depth completeness by more than 3-fold while still yielding a reduction in median absolute error of at least 30%. Given its remarkable performance and effective processing of event-data, our framework holds strong potential to become a standard approach for using deep learning for event-based depth estimation and SLAM. Project page: https://github.com/tub-rip/DERD-Net
Combined Physics and Event Camera Simulator for Slip Detection
Mar 05, 2025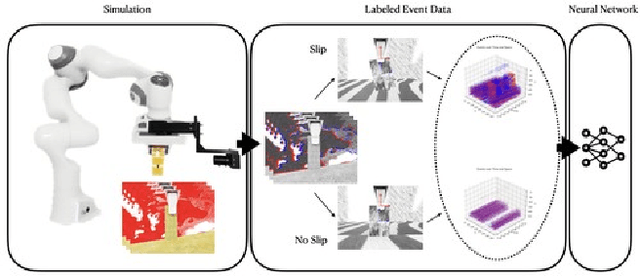
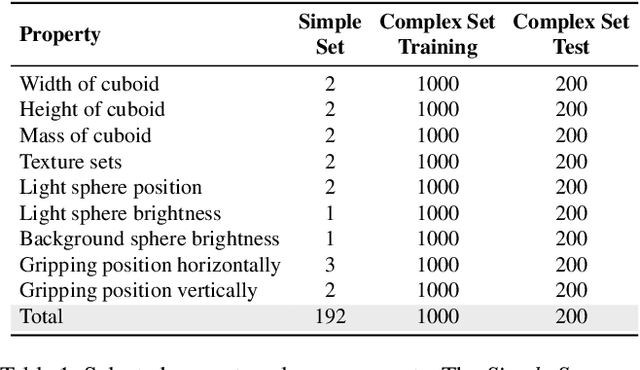
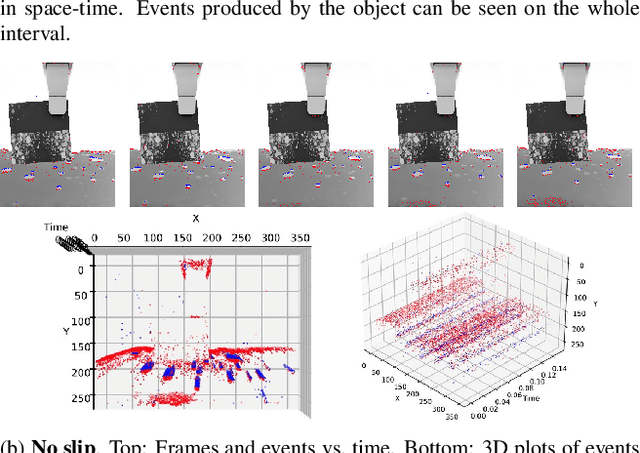
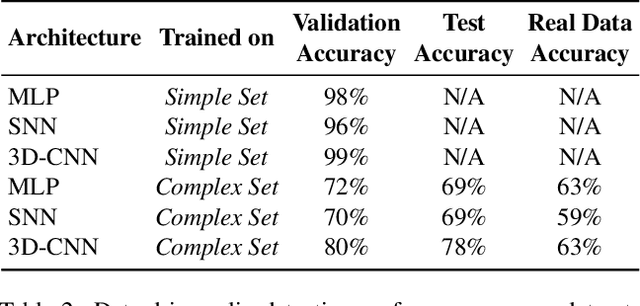
Robot manipulation is a common task in fields like industrial manufacturing. Detecting when objects slip from a robot's grasp is crucial for safe and reliable operation. Event cameras, which register pixel-level brightness changes at high temporal resolution (called ``events''), offer an elegant feature when mounted on a robot's end effector: since they only detect motion relative to their viewpoint, a properly grasped object produces no events, while a slipping object immediately triggers them. To research this feature, representative datasets are essential, both for analytic approaches and for training machine learning models. The majority of current research on slip detection with event-based data is done on real-world scenarios and manual data collection, as well as additional setups for data labeling. This can result in a significant increase in the time required for data collection, a lack of flexibility in scene setups, and a high level of complexity in the repetition of experiments. This paper presents a simulation pipeline for generating slip data using the described camera-gripper configuration in a robot arm, and demonstrates its effectiveness through initial data-driven experiments. The use of a simulator, once it is set up, has the potential to reduce the time spent on data collection, provide the ability to alter the setup at any time, simplify the process of repetition and the generation of arbitrarily large data sets. Two distinct datasets were created and validated through visual inspection and artificial neural networks (ANNs). Visual inspection confirmed photorealistic frame generation and accurate slip modeling, while three ANNs trained on this data achieved high validation accuracy and demonstrated good generalization capabilities on a separate test set, along with initial applicability to real-world data. Project page: https://github.com/tub-rip/event_slip
* 9 pages, 8 figures, 2 tables, https://github.com/tub-rip/event_slip
Fourier-based Action Recognition for Wildlife Behavior Quantification with Event Cameras
Oct 09, 2024Event cameras are novel bio-inspired vision sensors that measure pixel-wise brightness changes asynchronously instead of images at a given frame rate. They offer promising advantages, namely a high dynamic range, low latency, and minimal motion blur. Modern computer vision algorithms often rely on artificial neural network approaches, which require image-like representations of the data and cannot fully exploit the characteristics of event data. We propose approaches to action recognition based on the Fourier Transform. The approaches are intended to recognize oscillating motion patterns commonly present in nature. In particular, we apply our approaches to a recent dataset of breeding penguins annotated for "ecstatic display", a behavior where the observed penguins flap their wings at a certain frequency. We find that our approaches are both simple and effective, producing slightly lower results than a deep neural network (DNN) while relying just on a tiny fraction of the parameters compared to the DNN (five orders of magnitude fewer parameters). They work well despite the uncontrolled, diverse data present in the dataset. We hope this work opens a new perspective on event-based processing and action recognition.
Event-based Stereo Depth Estimation: A Survey
Sep 26, 2024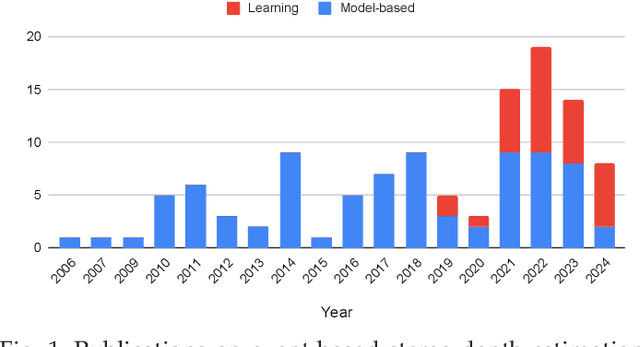

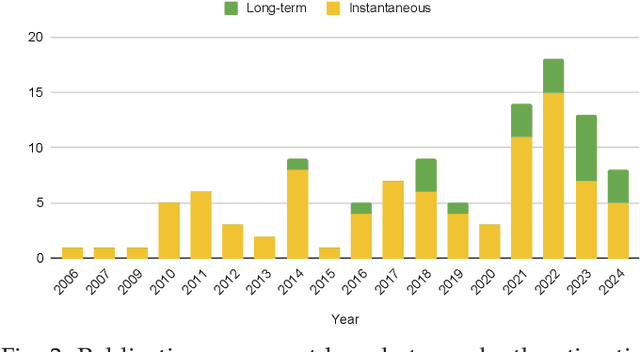

Stereopsis has widespread appeal in robotics as it is the predominant way by which living beings perceive depth to navigate our 3D world. Event cameras are novel bio-inspired sensors that detect per-pixel brightness changes asynchronously, with very high temporal resolution and high dynamic range, enabling machine perception in high-speed motion and broad illumination conditions. The high temporal precision also benefits stereo matching, making disparity (depth) estimation a popular research area for event cameras ever since its inception. Over the last 30 years, the field has evolved rapidly, from low-latency, low-power circuit design to current deep learning (DL) approaches driven by the computer vision community. The bibliography is vast and difficult to navigate for non-experts due its highly interdisciplinary nature. Past surveys have addressed distinct aspects of this topic, in the context of applications, or focusing only on a specific class of techniques, but have overlooked stereo datasets. This survey provides a comprehensive overview, covering both instantaneous stereo and long-term methods suitable for simultaneous localization and mapping (SLAM), along with theoretical and empirical comparisons. It is the first to extensively review DL methods as well as stereo datasets, even providing practical suggestions for creating new benchmarks to advance the field. The main advantages and challenges faced by event-based stereo depth estimation are also discussed. Despite significant progress, challenges remain in achieving optimal performance in not only accuracy but also efficiency, a cornerstone of event-based computing. We identify several gaps and propose future research directions. We hope this survey inspires future research in this area, by serving as an accessible entry point for newcomers, as well as a practical guide for seasoned researchers in the community.
ES-PTAM: Event-based Stereo Parallel Tracking and Mapping
Aug 28, 2024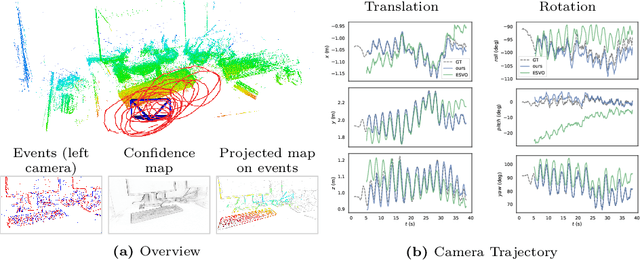



Visual Odometry (VO) and SLAM are fundamental components for spatial perception in mobile robots. Despite enormous progress in the field, current VO/SLAM systems are limited by their sensors' capability. Event cameras are novel visual sensors that offer advantages to overcome the limitations of standard cameras, enabling robots to expand their operating range to challenging scenarios, such as high-speed motion and high dynamic range illumination. We propose a novel event-based stereo VO system by combining two ideas: a correspondence-free mapping module that estimates depth by maximizing ray density fusion and a tracking module that estimates camera poses by maximizing edge-map alignment. We evaluate the system comprehensively on five real-world datasets, spanning a variety of camera types (manufacturers and spatial resolutions) and scenarios (driving, flying drone, hand-held, egocentric, etc). The quantitative and qualitative results demonstrate that our method outperforms the state of the art in majority of the test sequences by a margin, e.g., trajectory error reduction of 45% on RPG dataset, 61% on DSEC dataset, and 21% on TUM-VIE dataset. To benefit the community and foster research on event-based perception systems, we release the source code and results: https://github.com/tub-rip/ES-PTAM
* 17 pages, 7 figures, 4 tables, https://github.com/tub-rip/ES-PTAM
Low-power, Continuous Remote Behavioral Localization with Event Cameras
Dec 06, 2023
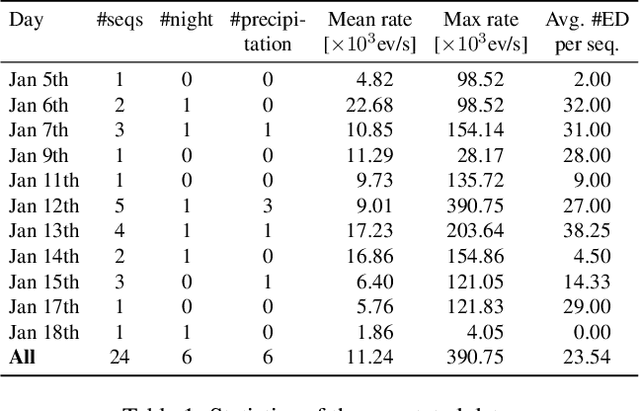


Researchers in natural science need reliable methods for quantifying animal behavior. Recently, numerous computer vision methods emerged to automate the process. However, observing wild species at remote locations remains a challenging task due to difficult lighting conditions and constraints on power supply and data storage. Event cameras offer unique advantages for battery-dependent remote monitoring due to their low power consumption and high dynamic range capabilities. We use this novel sensor to quantify a behavior in Chinstrap penguins called ecstatic display. We formulate the problem as a temporal action detection task, determining the start and end times of the behavior. For this purpose, we recorded a colony of breeding penguins in Antarctica during several weeks and labeled event data on 16 nests. The developed method consists of a generator of candidate time intervals (proposals) and a classifier of the actions within them. The experiments show that the event cameras' natural response to motion is effective for continuous behavior monitoring and detection, reaching a mean average precision (mAP) of 58% (which increases to 63% in good weather conditions). The results also demonstrate the robustness against various lighting conditions contained in the challenging dataset. The low-power capabilities of the event camera allows to record three times longer than with a conventional camera. This work pioneers the use of event cameras for remote wildlife observation, opening new interdisciplinary opportunities. https://tub-rip.github.io/eventpenguins/
Event-based Stereo Depth Estimation from Ego-motion using Ray Density Fusion
Oct 17, 2022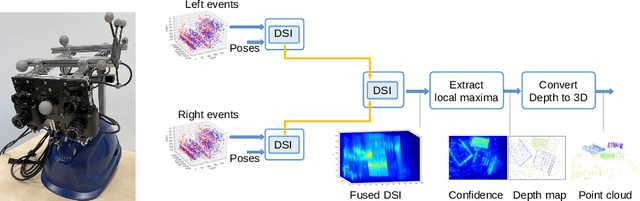

Event cameras are bio-inspired sensors that mimic the human retina by responding to brightness changes in the scene. They generate asynchronous spike-based outputs at microsecond resolution, providing advantages over traditional cameras like high dynamic range, low motion blur and power efficiency. Most event-based stereo methods attempt to exploit the high temporal resolution of the camera and the simultaneity of events across cameras to establish matches and estimate depth. By contrast, this work investigates how to estimate depth from stereo event cameras without explicit data association by fusing back-projected ray densities, and demonstrates its effectiveness on head-mounted camera data, which is recorded in an egocentric fashion. Code and video are available at https://github.com/tub-rip/dvs_mcemvs
* 6 pages, 3 figures, project page: https://github.com/tub-rip/dvs_mcemvs
Multi-Event-Camera Depth Estimation and Outlier Rejection by Refocused Events Fusion
Jul 21, 2022


Event cameras are bio-inspired sensors that offer advantages over traditional cameras. They work asynchronously, sampling the scene with microsecond resolution and producing a stream of brightness changes. This unconventional output has sparked novel computer vision methods to unlock the camera's potential. We tackle the problem of event-based stereo 3D reconstruction for SLAM. Most event-based stereo methods try to exploit the camera's high temporal resolution and event simultaneity across cameras to establish matches and estimate depth. By contrast, we investigate how to estimate depth without explicit data association by fusing Disparity Space Images (DSIs) originated in efficient monocular methods. We develop fusion theory and apply it to design multi-camera 3D reconstruction algorithms that produce state-of-the-art results, as we confirm by comparing against four baseline methods and testing on a variety of available datasets.
Versailles-FP dataset: Wall Detection in Ancient
Mar 14, 2021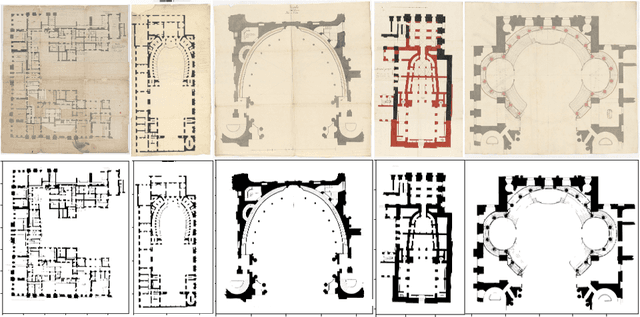

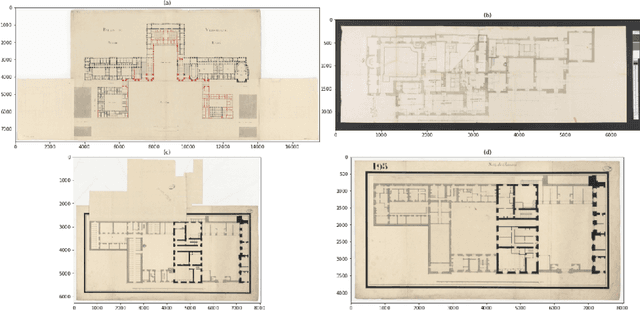

Access to historical monuments' floor plans over a time period is necessary to understand the architectural evolution and history. Such knowledge bases also helps to rebuild the history by establishing connection between different event, person and facts which are once part of the buildings. Since the two-dimensional plans do not capture the entire space, 3D modeling sheds new light on the reading of these unique archives and thus opens up great perspectives for understanding the ancient states of the monument. Since the first step in the building's or monument's 3D model is the wall detection in the floor plan, we introduce in this paper the new and unique Versailles FP dataset of wall groundtruthed images of the Versailles Palace dated between 17th and 18th century. The dataset's wall masks are generated using an automatic approach based on multi directional steerable filters. The generated wall masks are then validated and corrected manually. We validate our approach of wall mask generation in state-of-the-art modern datasets. Finally we propose a U net based convolutional framework for wall detection. Our method achieves state of the art result surpassing fully connected network based approach.