 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Pruning Can Do More: A Comprehensive Data Pruning Approach for Object Re-identification
Dec 13, 2024



Previous studies have demonstrated that not each sample in a dataset is of equal importance during training. Data pruning aims to remove less important or informative samples while still achieving comparable results as training on the original (untruncated) dataset, thereby reducing storage and training costs. However, the majority of data pruning methods are applied to image classification tasks. To our knowledge, this work is the first to explore the feasibility of these pruning methods applied to object re-identification (ReID) tasks, while also presenting a more comprehensive data pruning approach. By fully leveraging the logit history during training, our approach offers a more accurate and comprehensive metric for quantifying sample importance, as well as correcting mislabeled samples and recognizing outliers. Furthermore, our approach is highly efficient, reducing the cost of importance score estimation by 10 times compared to existing methods. Our approach is a plug-and-play, architecture-agnostic framework that can eliminate/reduce 35%, 30%, and 5% of samples/training time on the VeRi, MSMT17 and Market1501 datasets, respectively, with negligible loss in accuracy (< 0.1%). The lists of important, mislabeled, and outlier samples from these ReID datasets are available at https://github.com/Zi-Y/data-pruning-reid.
Increasing Model Capacity for Free: A Simple Strategy for Parameter Efficient Fine-tuning
Jul 01, 2024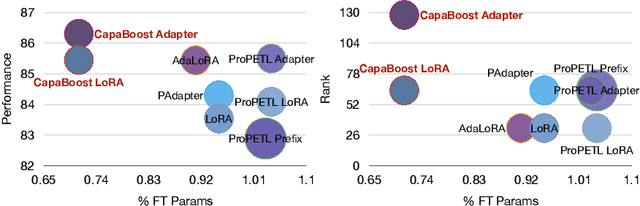
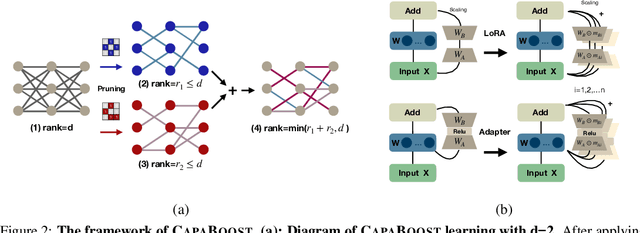
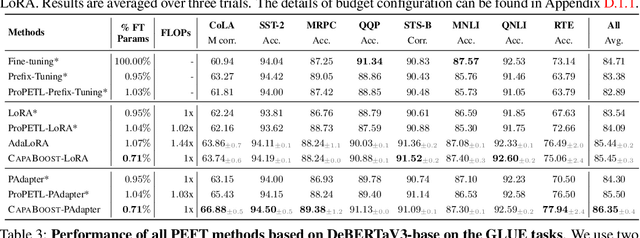
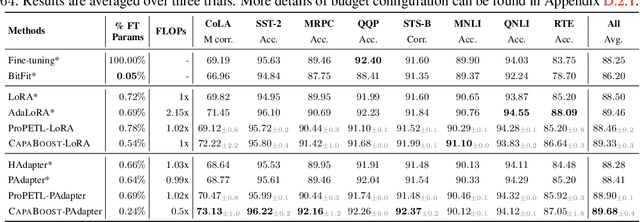
Fine-tuning large pre-trained foundation models, such as the 175B GPT-3, has attracted more attention for downstream tasks recently. While parameter-efficient fine-tuning methods have been proposed and proven effective without retraining all model parameters, their performance is limited by the capacity of incremental modules, especially under constrained parameter budgets. \\ To overcome this challenge, we propose CapaBoost, a simple yet effective strategy that enhances model capacity by leveraging low-rank updates through parallel weight modules in target layers. By applying static random masks to the shared weight matrix, CapaBoost constructs a diverse set of weight matrices, effectively increasing the rank of incremental weights without adding parameters. Notably, our approach can be seamlessly integrated into various existing parameter-efficient fine-tuning methods. We extensively validate the efficacy of CapaBoost through experiments on diverse downstream tasks, including natural language understanding, question answering, and image classification. Our results demonstrate significant improvements over baselines, without incurring additional computation or storage costs. Our code is available at \url{https://github.com/LINs-lab/CapaBoost}.
Revisiting Implicit Models: Sparsity Trade-offs Capability in Weight-tied Model for Vision Tasks
Jul 16, 2023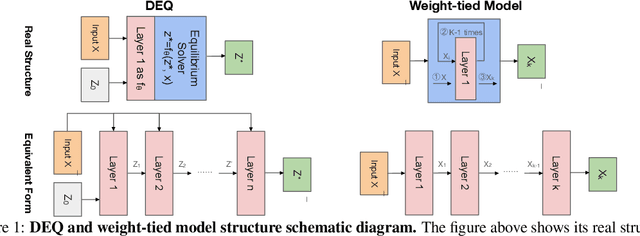
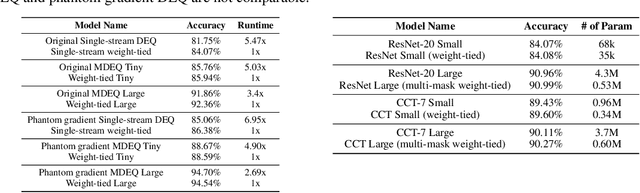
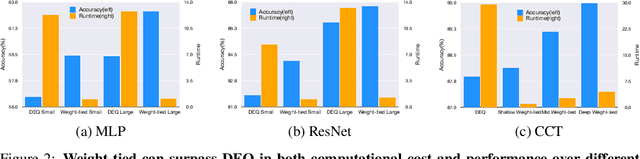

Implicit models such as Deep Equilibrium Models (DEQs) have garnered significant attention in the community for their ability to train infinite layer models with elegant solution-finding procedures and constant memory footprint. However, despite several attempts, these methods are heavily constrained by model inefficiency and optimization instability. Furthermore, fair benchmarking across relevant methods for vision tasks is missing. In this work, we revisit the line of implicit models and trace them back to the original weight-tied models. Surprisingly, we observe that weight-tied models are more effective, stable, as well as efficient on vision tasks, compared to the DEQ variants. Through the lens of these simple-yet-clean weight-tied models, we further study the fundamental limits in the model capacity of such models and propose the use of distinct sparse masks to improve the model capacity. Finally, for practitioners, we offer design guidelines regarding the depth, width, and sparsity selection for weight-tied models, and demonstrate the generalizability of our insights to other learning paradigms.
Multi-Stage Fusion for One-Click Segmentation
Oct 20, 2020
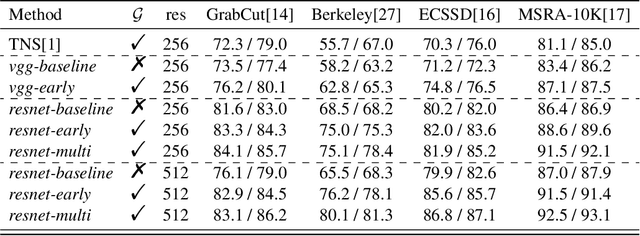
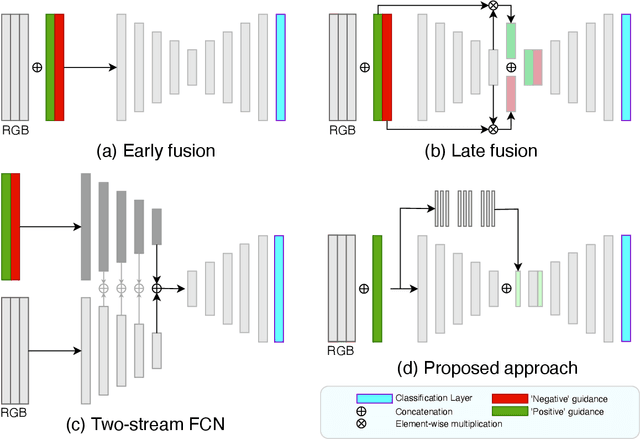
Segmenting objects of interest in an image is an essential building block of applications such as photo-editing and image analysis. Under interactive settings, one should achieve good segmentations while minimizing user input. Current deep learning-based interactive segmentation approaches use early fusion and incorporate user cues at the image input layer. Since segmentation CNNs have many layers, early fusion may weaken the influence of user interactions on the final prediction results. As such, we propose a new multi-stage guidance framework for interactive segmentation. By incorporating user cues at different stages of the network, we allow user interactions to impact the final segmentation output in a more direct way. Our proposed framework has a negligible increase in parameter count compared to early-fusion frameworks. We perform extensive experimentation on the standard interactive instance segmentation and one-click segmentation benchmarks and report state-of-the-art performance.
Localized Interactive Instance Segmentation
Oct 20, 2020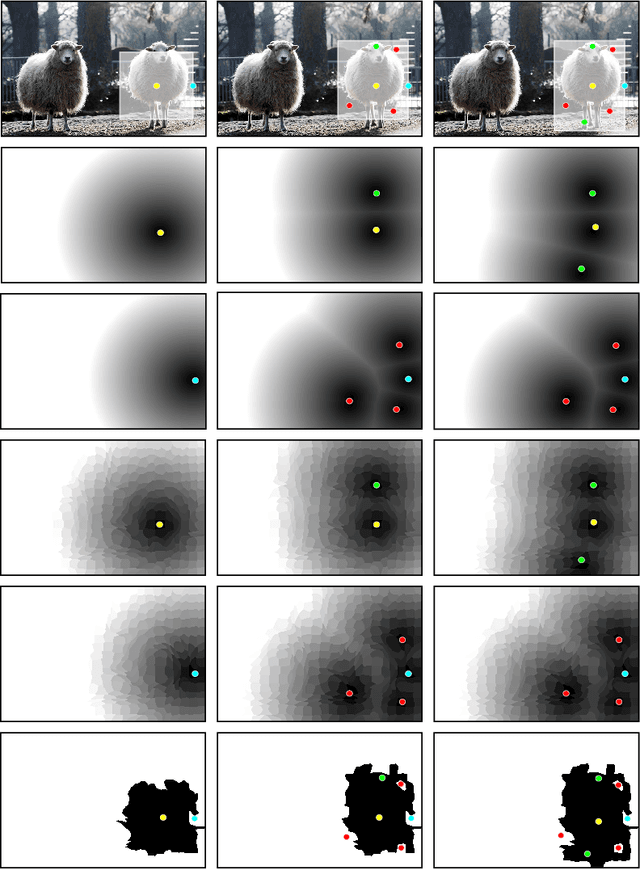
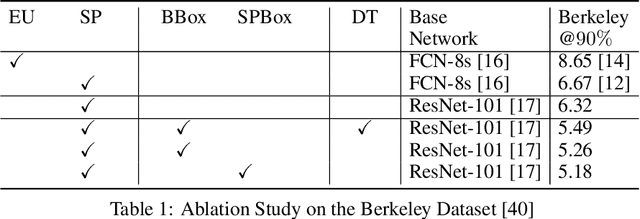

In current interactive instance segmentation works, the user is granted a free hand when providing clicks to segment an object; clicks are allowed on background pixels and other object instances far from the target object. This form of interaction is highly inconsistent with the end goal of efficiently isolating objects of interest. In our work, we propose a clicking scheme wherein user interactions are restricted to the proximity of the object. In addition, we propose a novel transformation of the user-provided clicks to generate a weak localization prior on the object which is consistent with image structures such as edges, textures etc. We demonstrate the effectiveness of our proposed clicking scheme and localization strategy through detailed experimentation in which we raise state-of-the-art on several standard interactive segmentation benchmarks.
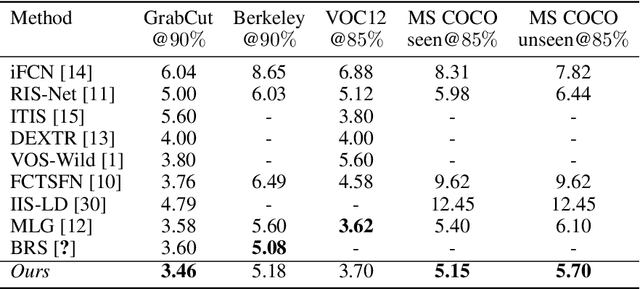
Scale-aware multi-level guidance for interactive instance segmentation
Dec 07, 2018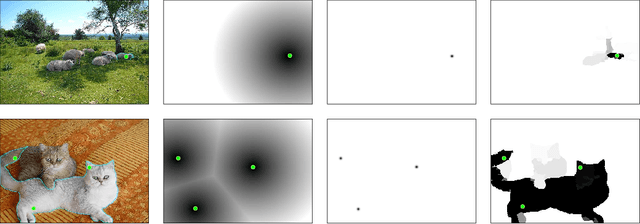
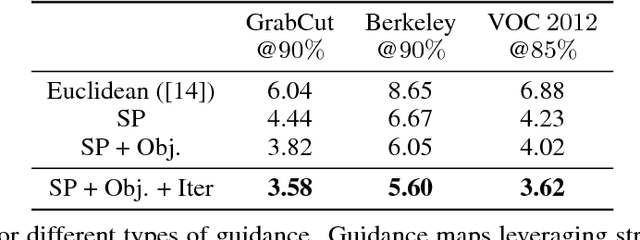
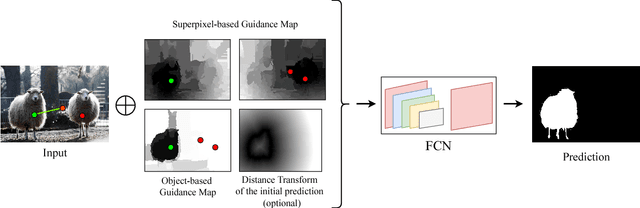
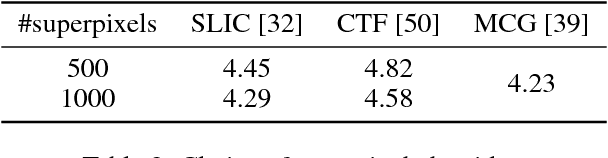
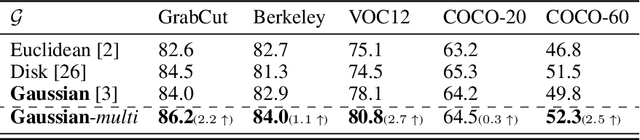
In interactive instance segmentation, users give feedback to iteratively refine segmentation masks. The user-provided clicks are transformed into guidance maps which provide the network with necessary cues on the whereabouts of the object of interest. Guidance maps used in current systems are purely distance-based and are either too localized or non-informative. We propose a novel transformation of user clicks to generate scale-aware guidance maps that leverage the hierarchical structural information present in an image. Using our guidance maps, even the most basic FCNs are able to outperform existing approaches that require state-of-the-art segmentation networks pre-trained on large scale segmentation datasets. We demonstrate the effectiveness of our proposed transformation strategy through comprehensive experimentation in which we significantly raise state-of-the-art on four standard interactive segmentation benchmarks.