 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScioMind: Cognitively Grounded Multi-Agent Social Simulation with Anchoring-Based Belief Dynamics and Dynamic Profiles
May 13, 2026Large language model (LLM)-based multi-agent simulation offers a powerful testbed for studying social opinion dynamics. Yet current approaches often adopt two contrasting methods: either relying on fixed update rules with limited cognitive grounding or delegating belief change largely to unconstrained LLM interaction. We introduce ScioMind, a cognitively grounded simulation framework that bridges these paradigms by combining structured opinion dynamics with LLM-based agent reasoning. ScioMind integrates three key components: 1) a memory-anchored belief update rule that modulates susceptibility to influence via personality-conditioned anchoring strength; 2) a hierarchical memory architecture that supports persistent, experience-driven belief formation; and 3) dynamic agent profiles derived from a corpus-grounded retrieval pipeline, enabling heterogeneous personalities, rationales, and evolving internal states. We evaluate ScioMind on multiple case studies in a real-world policy debate scenario. Across metrics including polarisation, diversity, extremization, and trajectory stability, the proposed components consistently yield improvements in behavioural realism. In particular, dynamic profiles increase opinion diversity, memory and reflection reduce unstable oscillation, and anchoring induces persistent belief trajectories that better align with patterns reported in political psychology. These results suggest that our cognitively grounded design provides a novel solution to LLM-based social simulation that improves both stable and behavioural realism
Cognifold: Always-On Proactive Memory via Cognitive Folding
May 13, 2026Existing agent memory remains predominantly reactive and retrieval-based, lacking the capacity to autonomously organize experience into persistent cognitive structure. Toward genuinely autonomous agents, we introduce Cognifold, a brain-inspired "always-on" agent memory designed for the next generation of proactive assistants. CogniFold continuously folds fragmented event streams into self-emerging cognitive structures, bootstrapping progressively higher-level cognition from incoming events and accumulated knowledge. We ground this by extending Complementary Learning Systems (CLS) theory from two layers (hippocampus, neocortex) to three, adding a prefrontal intent layer. Emulating the prefrontal cortex as the locus of intentional control and decision-making, CogniFold achieves this through graph-topology self-organization: cognitive structures proactively assemble under the stream, merge when semantically similar, decay when stale, relink through associative recall, and surface intents when concept-cluster density crosses a threshold. We evaluate structural formation using CogEval-Bench, demonstrating that CogniFold uniquely produces memory structures that match cognitive expectations and concept emergence. Furthermore, across 7 broad-coverage benchmarks spanning five cognitive domains, we validate that CogniFold simultaneously performs robustly on conventional memory benchmarks.
ECHO-2: A Large-Scale Distributed Rollout Framework for Cost-Efficient Reinforcement Learning
Feb 03, 2026Reinforcement learning (RL) is a critical stage in post-training large language models (LLMs), involving repeated interaction between rollout generation, reward evaluation, and centralized learning. Distributing rollout execution offers opportunities to leverage more cost-efficient inference resources, but introduces challenges in wide-area coordination and policy dissemination. We present ECHO-2, a distributed RL framework for post-training with remote inference workers and non-negligible dissemination latency. ECHO-2 combines centralized learning with distributed rollouts and treats bounded policy staleness as a user-controlled parameter, enabling rollout generation, dissemination, and training to overlap. We introduce an overlap-based capacity model that relates training time, dissemination latency, and rollout throughput, yielding a practical provisioning rule for sustaining learner utilization. To mitigate dissemination bottlenecks and lower cost, ECHO-2 employs peer-assisted pipelined broadcast and cost-aware activation of heterogeneous workers. Experiments on GRPO post-training of 4B and 8B models under real wide-area bandwidth regimes show that ECHO-2 significantly improves cost efficiency while preserving RL reward comparable to strong baselines.
ComfySearch: Autonomous Exploration and Reasoning for ComfyUI Workflows
Jan 07, 2026AI-generated content has progressed from monolithic models to modular workflows, especially on platforms like ComfyUI, allowing users to customize complex creative pipelines. However, the large number of components in ComfyUI and the difficulty of maintaining long-horizon structural consistency under strict graph constraints frequently lead to low pass rates and workflows of limited quality. To tackle these limitations, we present ComfySearch, an agentic framework that can effectively explore the component space and generate functional ComfyUI pipelines via validation-guided workflow construction. Experiments demonstrate that ComfySearch substantially outperforms existing methods on complex and creative tasks, achieving higher executability (pass) rates, higher solution rates, and stronger generalization.
SEDM: Scalable Self-Evolving Distributed Memory for Agents
Sep 11, 2025Long-term multi-agent systems inevitably generate vast amounts of trajectories and historical interactions, which makes efficient memory management essential for both performance and scalability. Existing methods typically depend on vector retrieval and hierarchical storage, yet they are prone to noise accumulation, uncontrolled memory expansion, and limited generalization across domains. To address these challenges, we present SEDM, Self-Evolving Distributed Memory, a verifiable and adaptive framework that transforms memory from a passive repository into an active, self-optimizing component. SEDM integrates verifiable write admission based on reproducible replay, a self-scheduling memory controller that dynamically ranks and consolidates entries according to empirical utility, and cross-domain knowledge diffusion that abstracts reusable insights to support transfer across heterogeneous tasks. Evaluations on benchmark datasets demonstrate that SEDM improves reasoning accuracy while reducing token overhead compared with strong memory baselines, and further enables knowledge distilled from fact verification to enhance multi-hop reasoning. The results highlight SEDM as a scalable and sustainable memory mechanism for open-ended multi-agent collaboration. The code will be released in the later stage of this project.
Pretraining Large Brain Language Model for Active BCI: Silent Speech
Apr 29, 2025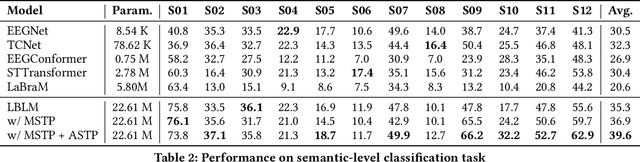
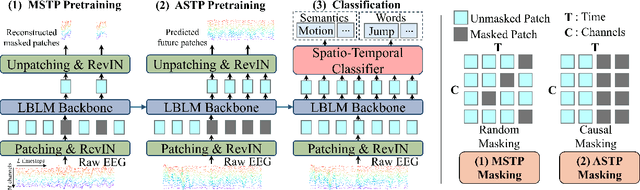
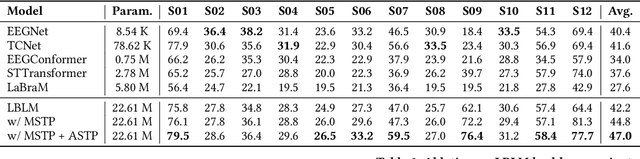
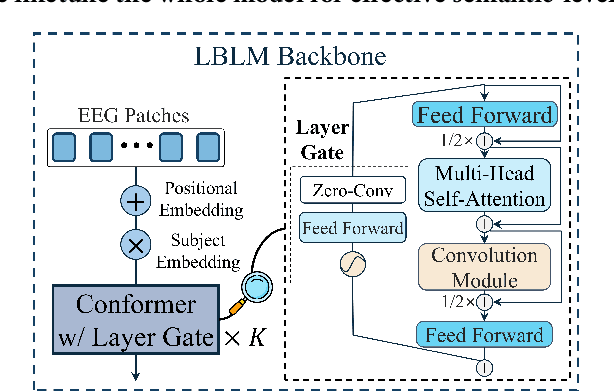
This paper explores silent speech decoding in active brain-computer interface (BCI) systems, which offer more natural and flexible communication than traditional BCI applications. We collected a new silent speech dataset of over 120 hours of electroencephalogram (EEG) recordings from 12 subjects, capturing 24 commonly used English words for language model pretraining and decoding. Following the recent success of pretraining large models with self-supervised paradigms to enhance EEG classification performance, we propose Large Brain Language Model (LBLM) pretrained to decode silent speech for active BCI. To pretrain LBLM, we propose Future Spectro-Temporal Prediction (FSTP) pretraining paradigm to learn effective representations from unlabeled EEG data. Unlike existing EEG pretraining methods that mainly follow a masked-reconstruction paradigm, our proposed FSTP method employs autoregressive modeling in temporal and frequency domains to capture both temporal and spectral dependencies from EEG signals. After pretraining, we finetune our LBLM on downstream tasks, including word-level and semantic-level classification. Extensive experiments demonstrate significant performance gains of the LBLM over fully-supervised and pretrained baseline models. For instance, in the difficult cross-session setting, our model achieves 47.0\% accuracy on semantic-level classification and 39.6\% in word-level classification, outperforming baseline methods by 5.4\% and 7.3\%, respectively. Our research advances silent speech decoding in active BCI systems, offering an innovative solution for EEG language model pretraining and a new dataset for fundamental research.
Scaling Prompt Instructed Zero Shot Composed Image Retrieval with Image-Only Data
Apr 01, 2025



Composed Image Retrieval (CIR) is the task of retrieving images matching a reference image augmented with a text, where the text describes changes to the reference image in natural language. Traditionally, models designed for CIR have relied on triplet data containing a reference image, reformulation text, and a target image. However, curating such triplet data often necessitates human intervention, leading to prohibitive costs. This challenge has hindered the scalability of CIR model training even with the availability of abundant unlabeled data. With the recent advances in foundational models, we advocate a shift in the CIR training paradigm where human annotations can be efficiently replaced by large language models (LLMs). Specifically, we demonstrate the capability of large captioning and language models in efficiently generating data for CIR only relying on unannotated image collections. Additionally, we introduce an embedding reformulation architecture that effectively combines image and text modalities. Our model, named InstructCIR, outperforms state-of-the-art methods in zero-shot composed image retrieval on CIRR and FashionIQ datasets. Furthermore, we demonstrate that by increasing the amount of generated data, our zero-shot model gets closer to the performance of supervised baselines.
Agent-Centric Personalized Multiple Clustering with Multi-Modal LLMs
Mar 31, 2025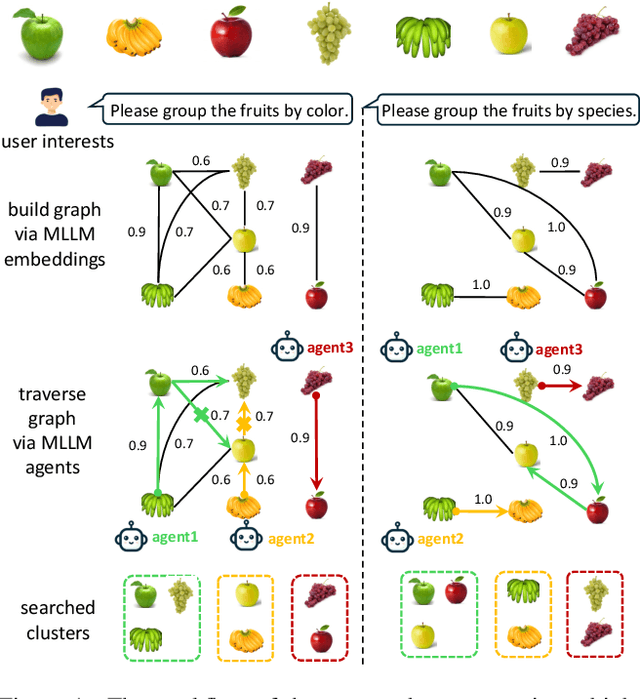
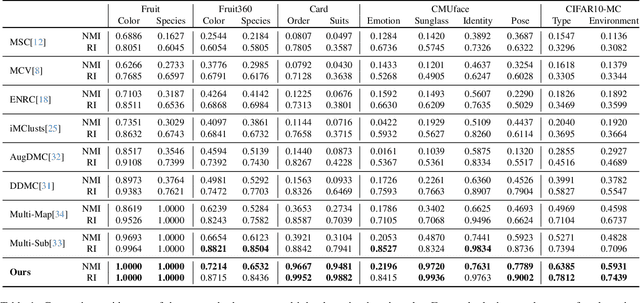
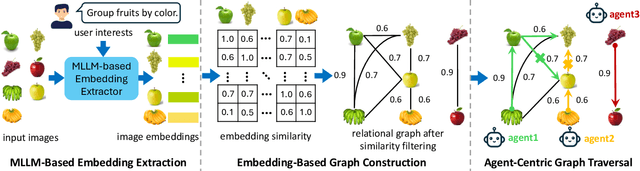

Personalized multiple clustering aims to generate diverse partitions of a dataset based on different user-specific aspects, rather than a single clustering. It has recently drawn research interest for accommodating varying user preferences. Recent approaches primarily use CLIP embeddings with proxy learning to extract representations biased toward user clustering preferences. However, CLIP primarily focuses on coarse image-text alignment, lacking a deep contextual understanding of user interests. To overcome these limitations, we propose an agent-centric personalized clustering framework that leverages multi-modal large language models (MLLMs) as agents to comprehensively traverse a relational graph to search for clusters based on user interests. Due to the advanced reasoning mechanism of MLLMs, the obtained clusters align more closely with user-defined criteria than those obtained from CLIP-based representations. To reduce computational overhead, we shorten the agents' traversal path by constructing a relational graph using user-interest-biased embeddings extracted by MLLMs. A large number of weakly connected edges can be filtered out based on embedding similarity, facilitating an efficient traversal search for agents. Experimental results show that the proposed method achieves NMI scores of 0.9667 and 0.9481 on the Card Order and Card Suits benchmarks, respectively, largely improving the SOTA model by over 140%.
EmbodiedVSR: Dynamic Scene Graph-Guided Chain-of-Thought Reasoning for Visual Spatial Tasks
Mar 14, 2025
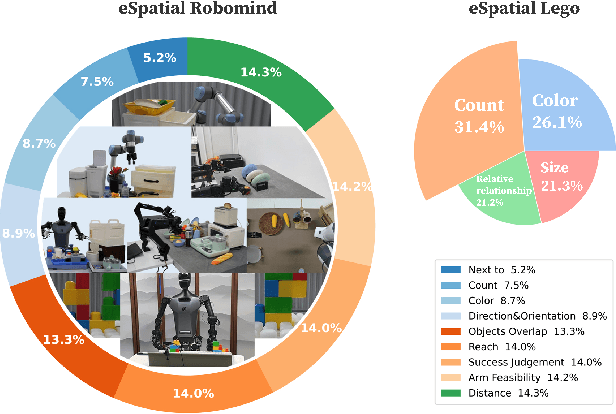
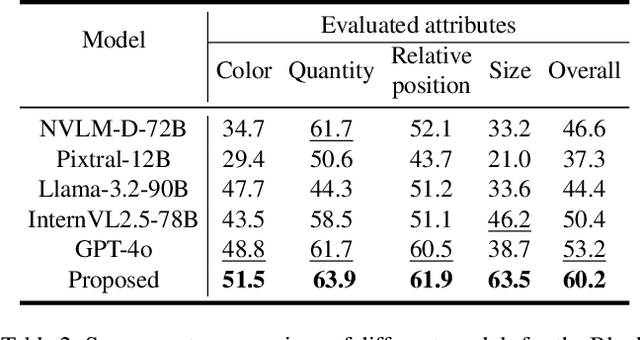
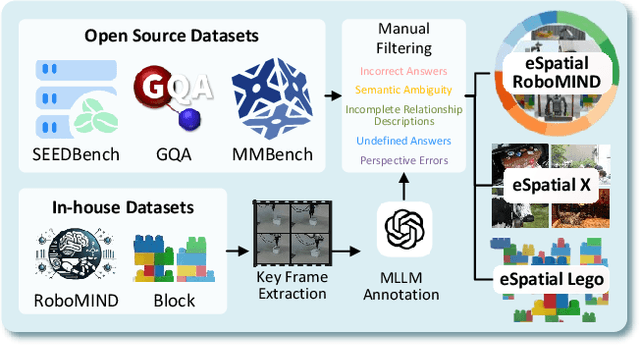
While multimodal large language models (MLLMs) have made groundbreaking progress in embodied intelligence, they still face significant challenges in spatial reasoning for complex long-horizon tasks. To address this gap, we propose EmbodiedVSR (Embodied Visual Spatial Reasoning), a novel framework that integrates dynamic scene graph-guided Chain-of-Thought (CoT) reasoning to enhance spatial understanding for embodied agents. By explicitly constructing structured knowledge representations through dynamic scene graphs, our method enables zero-shot spatial reasoning without task-specific fine-tuning. This approach not only disentangles intricate spatial relationships but also aligns reasoning steps with actionable environmental dynamics. To rigorously evaluate performance, we introduce the eSpatial-Benchmark, a comprehensive dataset including real-world embodied scenarios with fine-grained spatial annotations and adaptive task difficulty levels. Experiments demonstrate that our framework significantly outperforms existing MLLM-based methods in accuracy and reasoning coherence, particularly in long-horizon tasks requiring iterative environment interaction. The results reveal the untapped potential of MLLMs for embodied intelligence when equipped with structured, explainable reasoning mechanisms, paving the way for more reliable deployment in real-world spatial applications. The codes and datasets will be released soon.
WMNav: Integrating Vision-Language Models into World Models for Object Goal Navigation
Mar 04, 2025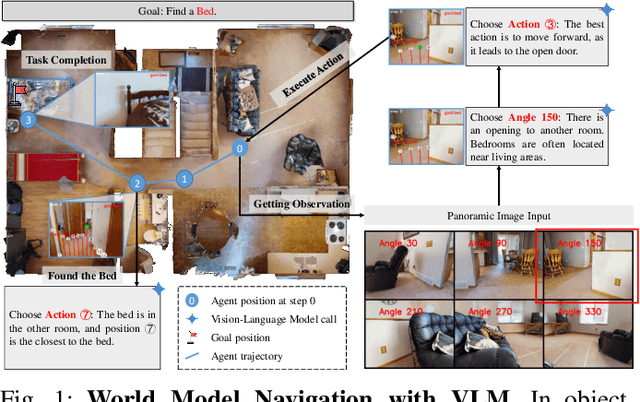
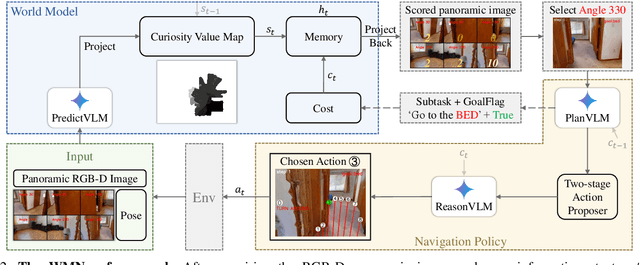
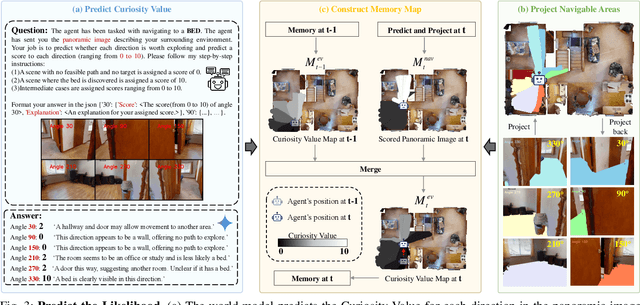

Object Goal Navigation-requiring an agent to locate a specific object in an unseen environment-remains a core challenge in embodied AI. Although recent progress in Vision-Language Model (VLM)-based agents has demonstrated promising perception and decision-making abilities through prompting, none has yet established a fully modular world model design that reduces risky and costly interactions with the environment by predicting the future state of the world. We introduce WMNav, a novel World Model-based Navigation framework powered by Vision-Language Models (VLMs). It predicts possible outcomes of decisions and builds memories to provide feedback to the policy module. To retain the predicted state of the environment, WMNav proposes the online maintained Curiosity Value Map as part of the world model memory to provide dynamic configuration for navigation policy. By decomposing according to a human-like thinking process, WMNav effectively alleviates the impact of model hallucination by making decisions based on the feedback difference between the world model plan and observation. To further boost efficiency, we implement a two-stage action proposer strategy: broad exploration followed by precise localization. Extensive evaluation on HM3D and MP3D validates WMNav surpasses existing zero-shot benchmarks in both success rate and exploration efficiency (absolute improvement: +3.2% SR and +3.2% SPL on HM3D, +13.5% SR and +1.1% SPL on MP3D). Project page: https://b0b8k1ng.github.io/WMNav/.