 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Cognitive Reward Modeling for Human-Centered Autonomous Vehicle Control
Mar 26, 2026Recent advancements in computer vision have accelerated the development of autonomous driving. Despite these advancements, training machines to drive in a way that aligns with human expectations remains a significant challenge. Human factors are still essential, as humans possess a sophisticated cognitive system capable of rapidly interpreting scene information and making accurate decisions. Aligning machine with human intent has been explored with Reinforcement Learning with Human Feedback (RLHF). Conventional RLHF methods rely on collecting human preference data by manually ranking generated outputs, which is time-consuming and indirect. In this work, we propose an electroencephalography (EEG)-guided decision-making framework to incorporate human cognitive insights without behaviour response interruption into reinforcement learning (RL) for autonomous driving. We collected EEG signals from 20 participants in a realistic driving simulator and analyzed event-related potentials (ERP) in response to sudden environmental changes. Our proposed framework employs a neural network to predict the strength of ERP based on the cognitive information from visual scene information. Moreover, we explore the integration of such cognitive information into the reward signal of the RL algorithm. Experimental results show that our framework can improve the collision avoidance ability of the RL algorithm, highlighting the potential of neuro-cognitive feedback in enhancing autonomous driving systems. Our project page is: https://alex95gogo.github.io/Cognitive-Reward/.
CFDA & CLIP at TREC iKAT 2025: Enhancing Personalized Conversational Search via Query Reformulation and Rank Fusion
Sep 19, 2025The 2025 TREC Interactive Knowledge Assistance Track (iKAT) featured both interactive and offline submission tasks. The former requires systems to operate under real-time constraints, making robustness and efficiency as important as accuracy, while the latter enables controlled evaluation of passage ranking and response generation with pre-defined datasets. To address this, we explored query rewriting and retrieval fusion as core strategies. We built our pipelines around Best-of-$N$ selection and Reciprocal Rank Fusion (RRF) strategies to handle different submission tasks. Results show that reranking and fusion improve robustness while revealing trade-offs between effectiveness and efficiency across both tasks.
PreCare: Designing AI Assistants for Advance Care Planning (ACP) to Enhance Personal Value Exploration, Patient Knowledge, and Decisional Confidence
May 14, 2025



Advance Care Planning (ACP) allows individuals to specify their preferred end-of-life life-sustaining treatments before they become incapacitated by injury or terminal illness (e.g., coma, cancer, dementia). While online ACP offers high accessibility, it lacks key benefits of clinical consultations, including personalized value exploration, immediate clarification of decision consequences. To bridge this gap, we conducted two formative studies: 1) shadowed and interviewed 3 ACP teams consisting of physicians, nurses, and social workers (18 patients total), and 2) interviewed 14 users of ACP websites. Building on these insights, we designed PreCare in collaboration with 6 ACP professionals. PreCare is a website with 3 AI-driven assistants designed to guide users through exploring personal values, gaining ACP knowledge, and supporting informed decision-making. A usability study (n=12) showed that PreCare achieved a System Usability Scale (SUS) rating of excellent. A comparative evaluation (n=12) showed that PreCare's AI assistants significantly improved exploration of personal values, knowledge, and decisional confidence, and was preferred by 92% of participants.
Pretraining Large Brain Language Model for Active BCI: Silent Speech
Apr 29, 2025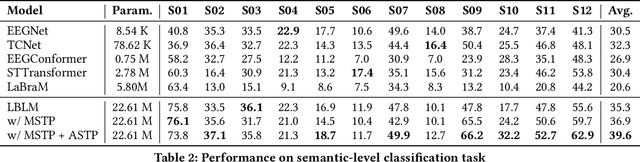
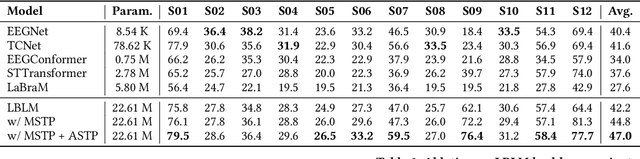
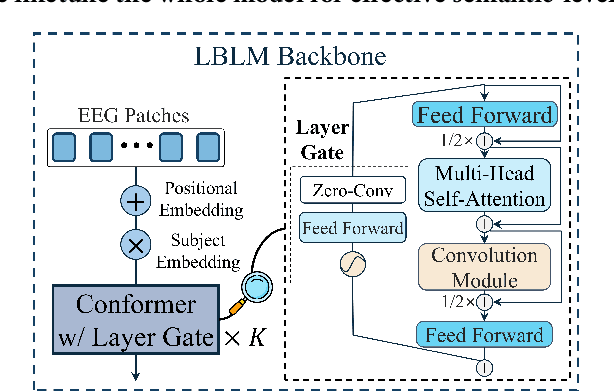
This paper explores silent speech decoding in active brain-computer interface (BCI) systems, which offer more natural and flexible communication than traditional BCI applications. We collected a new silent speech dataset of over 120 hours of electroencephalogram (EEG) recordings from 12 subjects, capturing 24 commonly used English words for language model pretraining and decoding. Following the recent success of pretraining large models with self-supervised paradigms to enhance EEG classification performance, we propose Large Brain Language Model (LBLM) pretrained to decode silent speech for active BCI. To pretrain LBLM, we propose Future Spectro-Temporal Prediction (FSTP) pretraining paradigm to learn effective representations from unlabeled EEG data. Unlike existing EEG pretraining methods that mainly follow a masked-reconstruction paradigm, our proposed FSTP method employs autoregressive modeling in temporal and frequency domains to capture both temporal and spectral dependencies from EEG signals. After pretraining, we finetune our LBLM on downstream tasks, including word-level and semantic-level classification. Extensive experiments demonstrate significant performance gains of the LBLM over fully-supervised and pretrained baseline models. For instance, in the difficult cross-session setting, our model achieves 47.0\% accuracy on semantic-level classification and 39.6\% in word-level classification, outperforming baseline methods by 5.4\% and 7.3\%, respectively. Our research advances silent speech decoding in active BCI systems, offering an innovative solution for EEG language model pretraining and a new dataset for fundamental research.
Multi-Agent Coordination across Diverse Applications: A Survey
Feb 21, 2025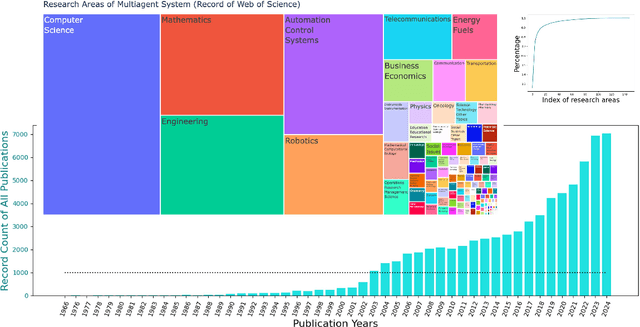
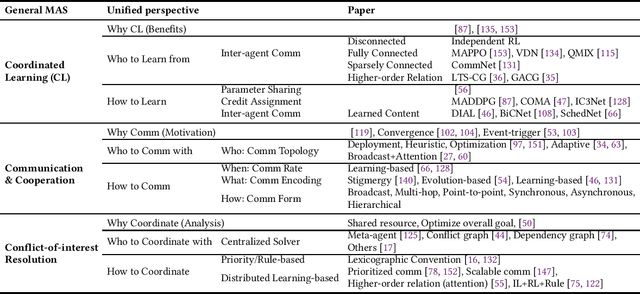
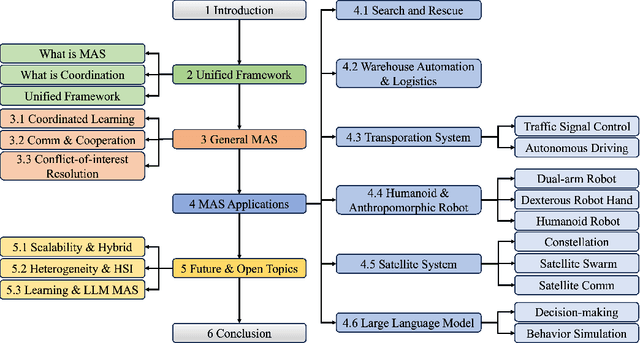
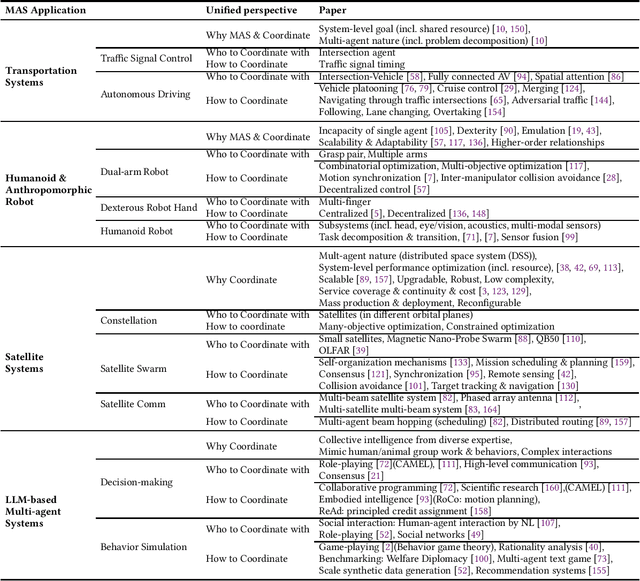
Multi-agent coordination studies the underlying mechanism enabling the trending spread of diverse multi-agent systems (MAS) and has received increasing attention, driven by the expansion of emerging applications and rapid AI advances. This survey outlines the current state of coordination research across applications through a unified understanding that answers four fundamental coordination questions: (1) what is coordination; (2) why coordination; (3) who to coordinate with; and (4) how to coordinate. Our purpose is to explore existing ideas and expertise in coordination and their connections across diverse applications, while identifying and highlighting emerging and promising research directions. First, general coordination problems that are essential to varied applications are identified and analyzed. Second, a number of MAS applications are surveyed, ranging from widely studied domains, e.g., search and rescue, warehouse automation and logistics, and transportation systems, to emerging fields including humanoid and anthropomorphic robots, satellite systems, and large language models (LLMs). Finally, open challenges about the scalability, heterogeneity, and learning mechanisms of MAS are analyzed and discussed. In particular, we identify the hybridization of hierarchical and decentralized coordination, human-MAS coordination, and LLM-based MAS as promising future directions.
A Self-Constructing Multi-Expert Fuzzy System for High-dimensional Data Classification
Oct 17, 2024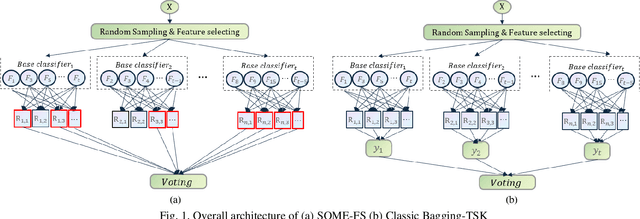
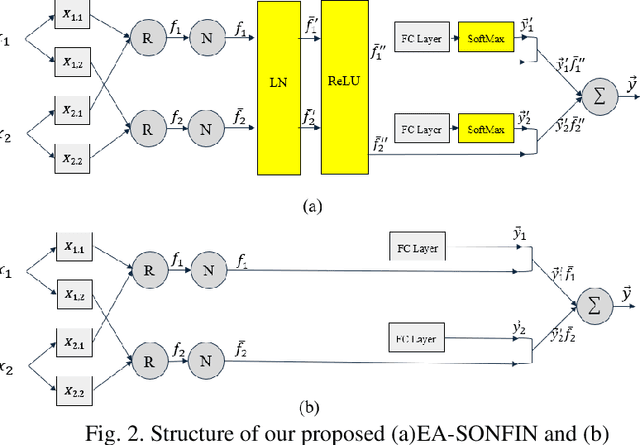
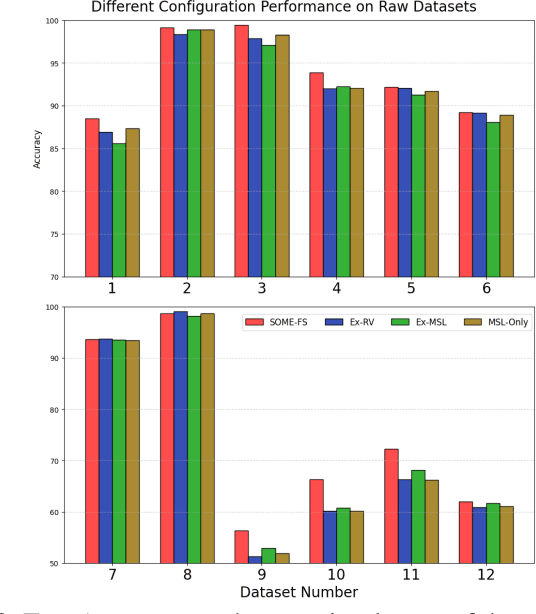
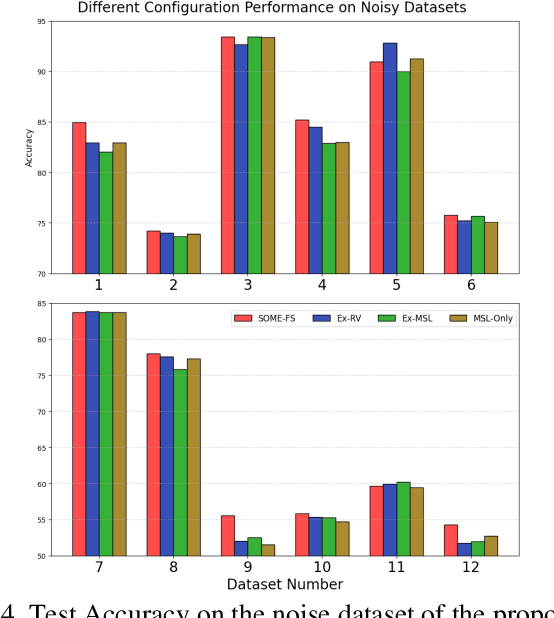
Fuzzy Neural Networks (FNNs) are effective machine learning models for classification tasks, commonly based on the Takagi-Sugeno-Kang (TSK) fuzzy system. However, when faced with high-dimensional data, especially with noise, FNNs encounter challenges such as vanishing gradients, excessive fuzzy rules, and limited access to prior knowledge. To address these challenges, we propose a novel fuzzy system, the Self-Constructing Multi-Expert Fuzzy System (SOME-FS). It combines two learning strategies: mixed structure learning and multi-expert advanced learning. The former enables each base classifier to effectively determine its structure without requiring prior knowledge, while the latter tackles the issue of vanishing gradients by enabling each rule to focus on its local region, thereby enhancing the robustness of the fuzzy classifiers. The overall ensemble architecture enhances the stability and prediction performance of the fuzzy system. Our experimental results demonstrate that the proposed SOME-FS is effective in high-dimensional tabular data, especially in dealing with uncertainty. Moreover, our stable rule mining process can identify concise and core rules learned by the SOME-FS.
iFuzzyTL: Interpretable Fuzzy Transfer Learning for SSVEP BCI System
Oct 16, 2024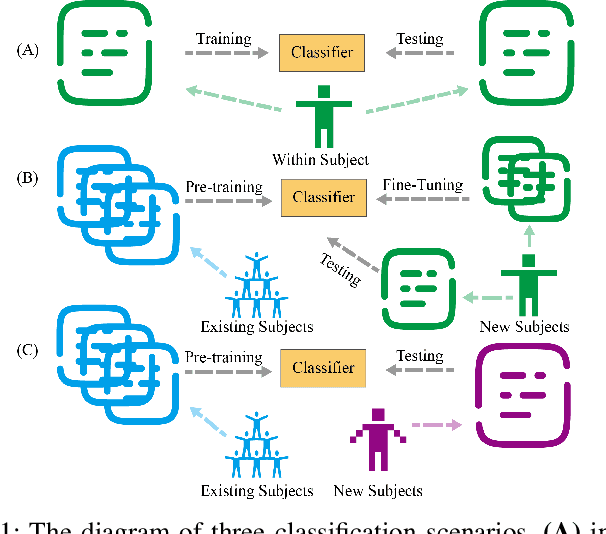
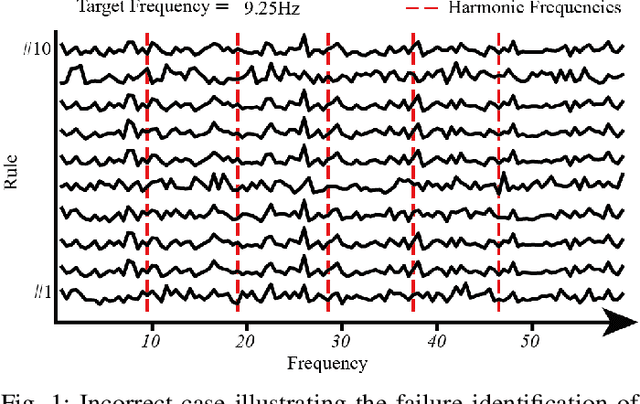
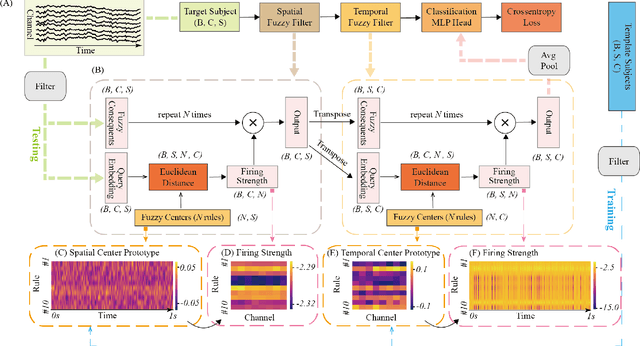
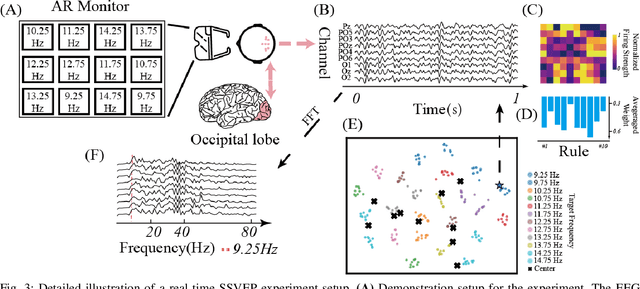
The rapid evolution of Brain-Computer Interfaces (BCIs) has significantly influenced the domain of human-computer interaction, with Steady-State Visual Evoked Potentials (SSVEP) emerging as a notably robust paradigm. This study explores advanced classification techniques leveraging interpretable fuzzy transfer learning (iFuzzyTL) to enhance the adaptability and performance of SSVEP-based systems. Recent efforts have strengthened to reduce calibration requirements through innovative transfer learning approaches, which refine cross-subject generalizability and minimize calibration through strategic application of domain adaptation and few-shot learning strategies. Pioneering developments in deep learning also offer promising enhancements, facilitating robust domain adaptation and significantly improving system responsiveness and accuracy in SSVEP classification. However, these methods often require complex tuning and extensive data, limiting immediate applicability. iFuzzyTL introduces an adaptive framework that combines fuzzy logic principles with neural network architectures, focusing on efficient knowledge transfer and domain adaptation. iFuzzyTL refines input signal processing and classification in a human-interpretable format by integrating fuzzy inference systems and attention mechanisms. This approach bolsters the model's precision and aligns with real-world operational demands by effectively managing the inherent variability and uncertainty of EEG data. The model's efficacy is demonstrated across three datasets: 12JFPM (89.70% accuracy for 1s with an information transfer rate (ITR) of 149.58), Benchmark (85.81% accuracy for 1s with an ITR of 213.99), and eldBETA (76.50% accuracy for 1s with an ITR of 94.63), achieving state-of-the-art results and setting new benchmarks for SSVEP BCI performance.
A Fuzzy-based Approach to Predict Human Interaction by Functional Near-Infrared Spectroscopy
Sep 26, 2024



The paper introduces a Fuzzy-based Attention (Fuzzy Attention Layer) mechanism, a novel computational approach to enhance the interpretability and efficacy of neural models in psychological research. The proposed Fuzzy Attention Layer mechanism is integrated as a neural network layer within the Transformer Encoder model to facilitate the analysis of complex psychological phenomena through neural signals, such as those captured by functional Near-Infrared Spectroscopy (fNIRS). By leveraging fuzzy logic, the Fuzzy Attention Layer is capable of learning and identifying interpretable patterns of neural activity. This capability addresses a significant challenge when using Transformer: the lack of transparency in determining which specific brain activities most contribute to particular predictions. Our experimental results demonstrated on fNIRS data from subjects engaged in social interactions involving handholding reveal that the Fuzzy Attention Layer not only learns interpretable patterns of neural activity but also enhances model performance. Additionally, the learned patterns provide deeper insights into the neural correlates of interpersonal touch and emotional exchange. The application of our model shows promising potential in deciphering the subtle complexities of human social behaviors, thereby contributing significantly to the fields of social neuroscience and psychological AI.
Enhancing End-to-End Autonomous Driving Systems Through Synchronized Human Behavior Data
Aug 20, 2024



This paper presents a pioneering exploration into the integration of fine-grained human supervision within the autonomous driving domain to enhance system performance. The current advances in End-to-End autonomous driving normally are data-driven and rely on given expert trials. However, this reliance limits the systems' generalizability and their ability to earn human trust. Addressing this gap, our research introduces a novel approach by synchronously collecting data from human and machine drivers under identical driving scenarios, focusing on eye-tracking and brainwave data to guide machine perception and decision-making processes. This paper utilizes the Carla simulation to evaluate the impact brought by human behavior guidance. Experimental results show that using human attention to guide machine attention could bring a significant improvement in driving performance. However, guidance by human intention still remains a challenge. This paper pioneers a promising direction and potential for utilizing human behavior guidance to enhance autonomous systems.
Towards Linguistic Neural Representation Learning and Sentence Retrieval from Electroencephalogram Recordings
Aug 08, 2024



Decoding linguistic information from non-invasive brain signals using EEG has gained increasing research attention due to its vast applicational potential. Recently, a number of works have adopted a generative-based framework to decode electroencephalogram (EEG) signals into sentences by utilizing the power generative capacity of pretrained large language models (LLMs). However, this approach has several drawbacks that hinder the further development of linguistic applications for brain-computer interfaces (BCIs). Specifically, the ability of the EEG encoder to learn semantic information from EEG data remains questionable, and the LLM decoder's tendency to generate sentences based on its training memory can be hard to avoid. These issues necessitate a novel approach for converting EEG signals into sentences. In this paper, we propose a novel two-step pipeline that addresses these limitations and enhances the validity of linguistic EEG decoding research. We first confirm that word-level semantic information can be learned from EEG data recorded during natural reading by training a Conformer encoder via a masked contrastive objective for word-level classification. To achieve sentence decoding results, we employ a training-free retrieval method to retrieve sentences based on the predictions from the EEG encoder. Extensive experiments and ablation studies were conducted in this paper for a comprehensive evaluation of the proposed approach. Visualization of the top prediction candidates reveals that our model effectively groups EEG segments into semantic categories with similar meanings, thereby validating its ability to learn patterns from unspoken EEG recordings. Despite the exploratory nature of this work, these results suggest that our method holds promise for providing more reliable solutions for converting EEG signals into text.