 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter- and Intra-Subject Variability in EEG: A Systematic Survey
Feb 01, 2026Electroencephalography (EEG) underpins neuroscience, clinical neurophysiology, and brain-computer interfaces (BCIs), yet pronounced inter- and intra-subject variability limits reliability, reproducibility, and translation. This systematic review studies that quantified or modeled EEG variability across resting-state, event-related potentials (ERPs), and task-related/BCI paradigms (including motor imagery and SSVEP) in healthy and clinical cohorts. Across paradigms, inter-subject differences are typically larger than within-subject fluctuations, but both affect inference and model generalization. Stability is feature-dependent: alpha-band measures and individual alpha peak frequency are often relatively reliable, whereas higher-frequency and many connectivity-derived metrics show more heterogeneous reliability; ERP reliability varies by component, with P300 measures frequently showing moderate-to-good stability. We summarize major sources of variability (biological, state-related, technical, and analytical), review common quantification and modeling approaches (e.g., ICC, CV, SNR, generalizability theory, and multivariate/learning-based methods), and provide recommendations for study design, reporting, and harmonization. Overall, EEG variability should be treated as both a practical constraint to manage and a meaningful signal to leverage for precision neuroscience and robust neurotechnology.
Pretraining Large Brain Language Model for Active BCI: Silent Speech
Apr 29, 2025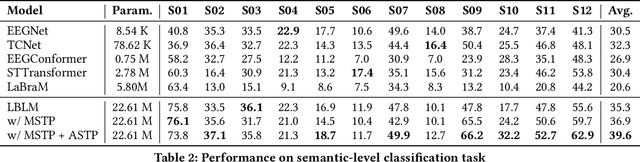
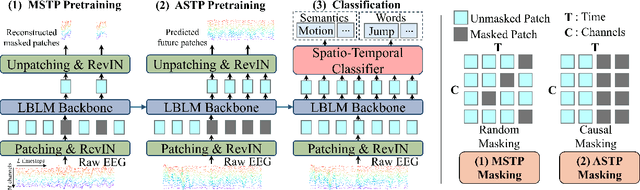
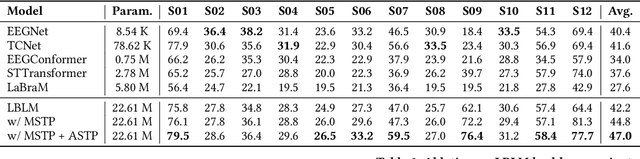
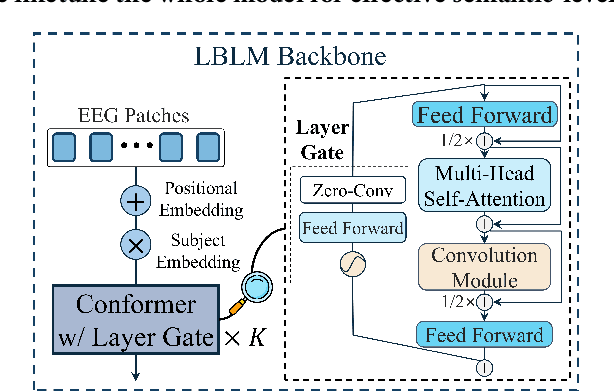
This paper explores silent speech decoding in active brain-computer interface (BCI) systems, which offer more natural and flexible communication than traditional BCI applications. We collected a new silent speech dataset of over 120 hours of electroencephalogram (EEG) recordings from 12 subjects, capturing 24 commonly used English words for language model pretraining and decoding. Following the recent success of pretraining large models with self-supervised paradigms to enhance EEG classification performance, we propose Large Brain Language Model (LBLM) pretrained to decode silent speech for active BCI. To pretrain LBLM, we propose Future Spectro-Temporal Prediction (FSTP) pretraining paradigm to learn effective representations from unlabeled EEG data. Unlike existing EEG pretraining methods that mainly follow a masked-reconstruction paradigm, our proposed FSTP method employs autoregressive modeling in temporal and frequency domains to capture both temporal and spectral dependencies from EEG signals. After pretraining, we finetune our LBLM on downstream tasks, including word-level and semantic-level classification. Extensive experiments demonstrate significant performance gains of the LBLM over fully-supervised and pretrained baseline models. For instance, in the difficult cross-session setting, our model achieves 47.0\% accuracy on semantic-level classification and 39.6\% in word-level classification, outperforming baseline methods by 5.4\% and 7.3\%, respectively. Our research advances silent speech decoding in active BCI systems, offering an innovative solution for EEG language model pretraining and a new dataset for fundamental research.
AEGIS: Human Attention-based Explainable Guidance for Intelligent Vehicle Systems
Apr 08, 2025Improving decision-making capabilities in Autonomous Intelligent Vehicles (AIVs) has been a heated topic in recent years. Despite advancements, training machines to capture regions of interest for comprehensive scene understanding, like human perception and reasoning, remains a significant challenge. This study introduces a novel framework, Human Attention-based Explainable Guidance for Intelligent Vehicle Systems (AEGIS). AEGIS utilizes human attention, converted from eye-tracking, to guide reinforcement learning (RL) models to identify critical regions of interest for decision-making. AEGIS uses a pre-trained human attention model to guide RL models to identify critical regions of interest for decision-making. By collecting 1.2 million frames from 20 participants across six scenarios, AEGIS pre-trains a model to predict human attention patterns.
Can ChatGPT Diagnose Alzheimer's Disease?
Feb 10, 2025Can ChatGPT diagnose Alzheimer's Disease (AD)? AD is a devastating neurodegenerative condition that affects approximately 1 in 9 individuals aged 65 and older, profoundly impairing memory and cognitive function. This paper utilises 9300 electronic health records (EHRs) with data from Magnetic Resonance Imaging (MRI) and cognitive tests to address an intriguing question: As a general-purpose task solver, can ChatGPT accurately detect AD using EHRs? We present an in-depth evaluation of ChatGPT using a black-box approach with zero-shot and multi-shot methods. This study unlocks ChatGPT's capability to analyse MRI and cognitive test results, as well as its potential as a diagnostic tool for AD. By automating aspects of the diagnostic process, this research opens a transformative approach for the healthcare system, particularly in addressing disparities in resource-limited regions where AD specialists are scarce. Hence, it offers a foundation for a promising method for early detection, supporting individuals with timely interventions, which is paramount for Quality of Life (QoL).
Neural Spelling: A Spell-Based BCI System for Language Neural Decoding
Jan 29, 2025



Brain-computer interfaces (BCIs) present a promising avenue by translating neural activity directly into text, eliminating the need for physical actions. However, existing non-invasive BCI systems have not successfully covered the entire alphabet, limiting their practicality. In this paper, we propose a novel non-invasive EEG-based BCI system with Curriculum-based Neural Spelling Framework, which recognizes all 26 alphabet letters by decoding neural signals associated with handwriting first, and then apply a Generative AI (GenAI) to enhance spell-based neural language decoding tasks. Our approach combines the ease of handwriting with the accessibility of EEG technology, utilizing advanced neural decoding algorithms and pre-trained large language models (LLMs) to translate EEG patterns into text with high accuracy. This system show how GenAI can improve the performance of typical spelling-based neural language decoding task, and addresses the limitations of previous methods, offering a scalable and user-friendly solution for individuals with communication impairments, thereby enhancing inclusive communication options.
Contrastive Masked Autoencoders for Character-Level Open-Set Writer Identification
Jan 21, 2025



In the realm of digital forensics and document authentication, writer identification plays a crucial role in determining the authors of documents based on handwriting styles. The primary challenge in writer-id is the "open-set scenario", where the goal is accurately recognizing writers unseen during the model training. To overcome this challenge, representation learning is the key. This method can capture unique handwriting features, enabling it to recognize styles not previously encountered during training. Building on this concept, this paper introduces the Contrastive Masked Auto-Encoders (CMAE) for Character-level Open-Set Writer Identification. We merge Masked Auto-Encoders (MAE) with Contrastive Learning (CL) to simultaneously and respectively capture sequential information and distinguish diverse handwriting styles. Demonstrating its effectiveness, our model achieves state-of-the-art (SOTA) results on the CASIA online handwriting dataset, reaching an impressive precision rate of 89.7%. Our study advances universal writer-id with a sophisticated representation learning approach, contributing substantially to the ever-evolving landscape of digital handwriting analysis, and catering to the demands of an increasingly interconnected world.
A Self-Constructing Multi-Expert Fuzzy System for High-dimensional Data Classification
Oct 17, 2024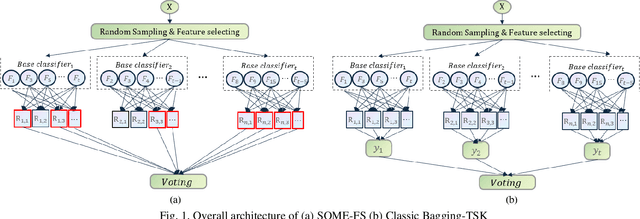
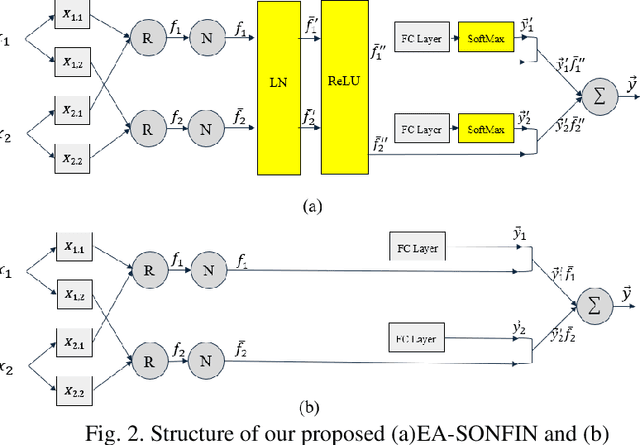
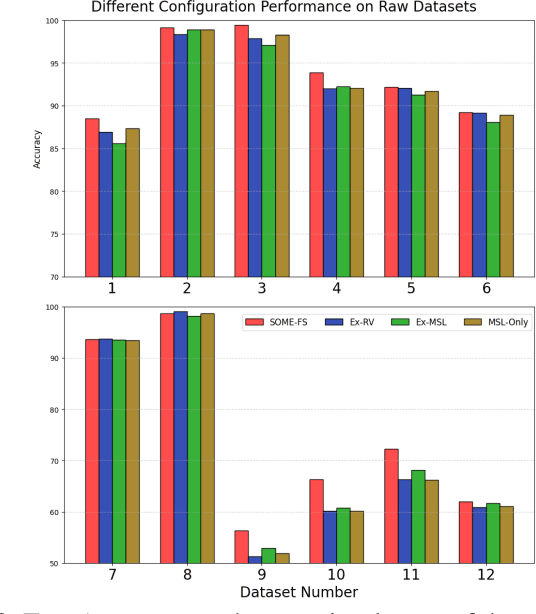
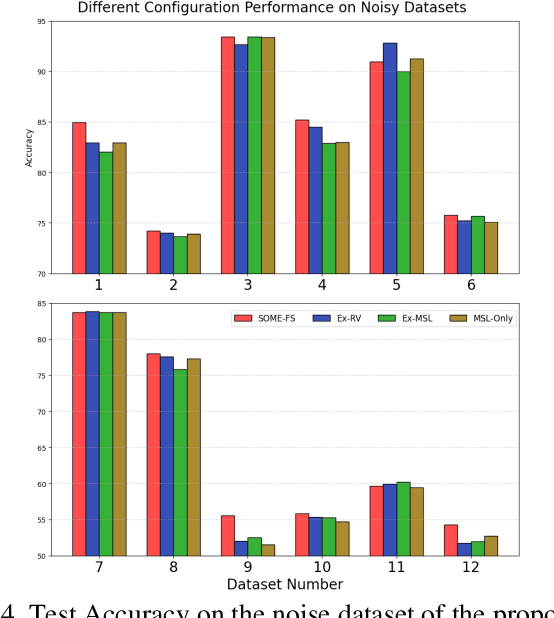
Fuzzy Neural Networks (FNNs) are effective machine learning models for classification tasks, commonly based on the Takagi-Sugeno-Kang (TSK) fuzzy system. However, when faced with high-dimensional data, especially with noise, FNNs encounter challenges such as vanishing gradients, excessive fuzzy rules, and limited access to prior knowledge. To address these challenges, we propose a novel fuzzy system, the Self-Constructing Multi-Expert Fuzzy System (SOME-FS). It combines two learning strategies: mixed structure learning and multi-expert advanced learning. The former enables each base classifier to effectively determine its structure without requiring prior knowledge, while the latter tackles the issue of vanishing gradients by enabling each rule to focus on its local region, thereby enhancing the robustness of the fuzzy classifiers. The overall ensemble architecture enhances the stability and prediction performance of the fuzzy system. Our experimental results demonstrate that the proposed SOME-FS is effective in high-dimensional tabular data, especially in dealing with uncertainty. Moreover, our stable rule mining process can identify concise and core rules learned by the SOME-FS.
iFuzzyTL: Interpretable Fuzzy Transfer Learning for SSVEP BCI System
Oct 16, 2024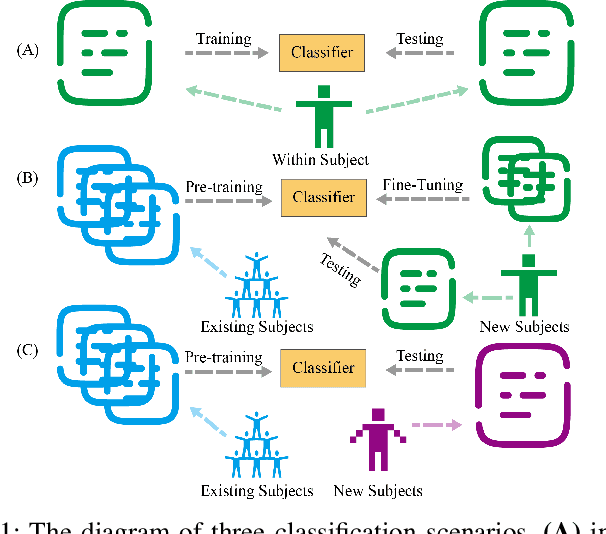
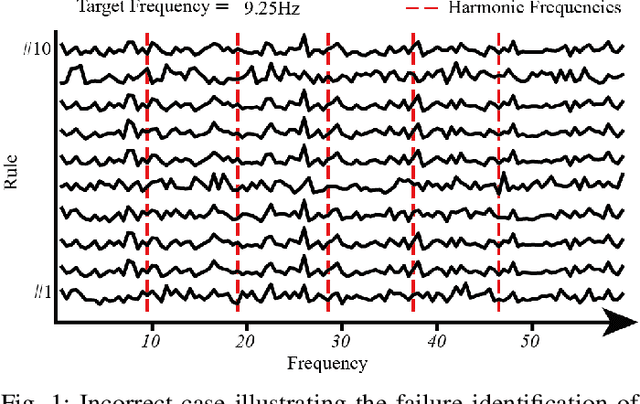
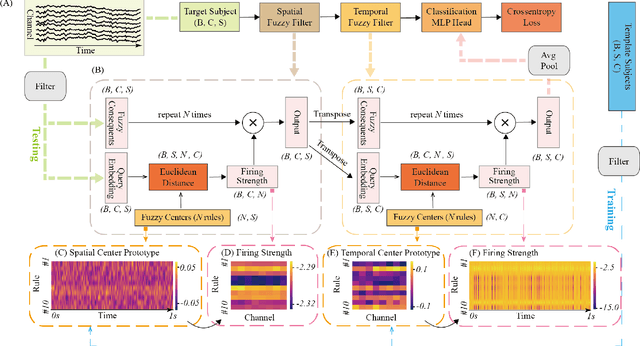
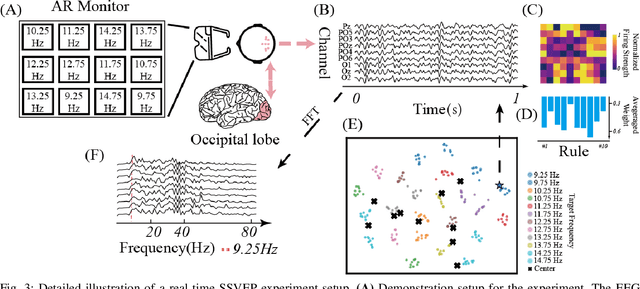
The rapid evolution of Brain-Computer Interfaces (BCIs) has significantly influenced the domain of human-computer interaction, with Steady-State Visual Evoked Potentials (SSVEP) emerging as a notably robust paradigm. This study explores advanced classification techniques leveraging interpretable fuzzy transfer learning (iFuzzyTL) to enhance the adaptability and performance of SSVEP-based systems. Recent efforts have strengthened to reduce calibration requirements through innovative transfer learning approaches, which refine cross-subject generalizability and minimize calibration through strategic application of domain adaptation and few-shot learning strategies. Pioneering developments in deep learning also offer promising enhancements, facilitating robust domain adaptation and significantly improving system responsiveness and accuracy in SSVEP classification. However, these methods often require complex tuning and extensive data, limiting immediate applicability. iFuzzyTL introduces an adaptive framework that combines fuzzy logic principles with neural network architectures, focusing on efficient knowledge transfer and domain adaptation. iFuzzyTL refines input signal processing and classification in a human-interpretable format by integrating fuzzy inference systems and attention mechanisms. This approach bolsters the model's precision and aligns with real-world operational demands by effectively managing the inherent variability and uncertainty of EEG data. The model's efficacy is demonstrated across three datasets: 12JFPM (89.70% accuracy for 1s with an information transfer rate (ITR) of 149.58), Benchmark (85.81% accuracy for 1s with an ITR of 213.99), and eldBETA (76.50% accuracy for 1s with an ITR of 94.63), achieving state-of-the-art results and setting new benchmarks for SSVEP BCI performance.
A Fuzzy-based Approach to Predict Human Interaction by Functional Near-Infrared Spectroscopy
Sep 26, 2024



The paper introduces a Fuzzy-based Attention (Fuzzy Attention Layer) mechanism, a novel computational approach to enhance the interpretability and efficacy of neural models in psychological research. The proposed Fuzzy Attention Layer mechanism is integrated as a neural network layer within the Transformer Encoder model to facilitate the analysis of complex psychological phenomena through neural signals, such as those captured by functional Near-Infrared Spectroscopy (fNIRS). By leveraging fuzzy logic, the Fuzzy Attention Layer is capable of learning and identifying interpretable patterns of neural activity. This capability addresses a significant challenge when using Transformer: the lack of transparency in determining which specific brain activities most contribute to particular predictions. Our experimental results demonstrated on fNIRS data from subjects engaged in social interactions involving handholding reveal that the Fuzzy Attention Layer not only learns interpretable patterns of neural activity but also enhances model performance. Additionally, the learned patterns provide deeper insights into the neural correlates of interpersonal touch and emotional exchange. The application of our model shows promising potential in deciphering the subtle complexities of human social behaviors, thereby contributing significantly to the fields of social neuroscience and psychological AI.
BELT-2: Bootstrapping EEG-to-Language representation alignment for multi-task brain decoding
Aug 28, 2024



The remarkable success of large language models (LLMs) across various multi-modality applications is well established. However, integrating large language models with humans, or brain dynamics, remains relatively unexplored. In this paper, we introduce BELT-2, a pioneering multi-task model designed to enhance both encoding and decoding performance from EEG signals. To bolster the quality of the EEG encoder, BELT-2 is the first work to innovatively 1) adopt byte-pair encoding (BPE)-level EEG-language alignment and 2) integrate multi-task training and decoding in the EEG domain. Inspired by the idea of \textbf{\textit{Bridging the Brain with GPT}}, we further connect the multi-task EEG encoder with LLMs by utilizing prefix-tuning on intermediary output from the EEG encoder. These innovative efforts make BELT-2 a pioneering breakthrough, making it the first work in the field capable of decoding coherent and readable sentences from non-invasive brain signals. Our experiments highlight significant advancements over prior techniques in both quantitative and qualitative measures, achieving a decoding performance with a BLEU-1 score of 52.2\% on the ZuCo dataset. Furthermore, BELT-2 shows a remarkable improvement ranging from 31\% to 162\% on other translation benchmarks. Codes can be accessed via the provided anonymous link~\footnote{https://anonymous.4open.science/r/BELT-2-0048}.