 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainStack: Neuro-MoE with Functionally Guided Expert Routing for EEG-Based Language Decoding
Jan 29, 2026Decoding linguistic information from electroencephalography (EEG) remains challenging due to the brain's distributed and nonlinear organization. We present BrainStack, a functionally guided neuro-mixture-of-experts (Neuro-MoE) framework that models the brain's modular functional architecture through anatomically partitioned expert networks. Each functional region is represented by a specialized expert that learns localized neural dynamics, while a transformer-based global expert captures cross-regional dependencies. A learnable routing gate adaptively aggregates these heterogeneous experts, enabling context-dependent expert coordination and selective fusion. To promote coherent representation across the hierarchy, we introduce cross-regional distillation, where the global expert provides top-down regularization to the regional experts. We further release SilentSpeech-EEG (SS-EEG), a large-scale benchmark comprising over 120 hours of EEG recordings from 12 subjects performing 24 silent words, the largest dataset of its kind. Experiments demonstrate that BrainStack consistently outperforms state-of-the-art models, achieving superior accuracy and generalization across subjects. Our results establish BrainStack as a functionally modular, neuro-inspired MoE paradigm that unifies neuroscientific priors with adaptive expert routing, paving the way for scalable and interpretable brain-language decoding.
Can SSD-Mamba2 Unlock Reinforcement Learning for End-to-End Motion Control?
Sep 09, 2025End-to-end reinforcement learning for motion control promises unified perception-action policies that scale across embodiments and tasks, yet most deployed controllers are either blind (proprioception-only) or rely on fusion backbones with unfavorable compute-memory trade-offs. Recurrent controllers struggle with long-horizon credit assignment, and Transformer-based fusion incurs quadratic cost in token length, limiting temporal and spatial context. We present a vision-driven cross-modal RL framework built on SSD-Mamba2, a selective state-space backbone that applies state-space duality (SSD) to enable both recurrent and convolutional scanning with hardware-aware streaming and near-linear scaling. Proprioceptive states and exteroceptive observations (e.g., depth tokens) are encoded into compact tokens and fused by stacked SSD-Mamba2 layers. The selective state-space updates retain long-range dependencies with markedly lower latency and memory use than quadratic self-attention, enabling longer look-ahead, higher token resolution, and stable training under limited compute. Policies are trained end-to-end under curricula that randomize terrain and appearance and progressively increase scene complexity. A compact, state-centric reward balances task progress, energy efficiency, and safety. Across diverse motion-control scenarios, our approach consistently surpasses strong state-of-the-art baselines in return, safety (collisions and falls), and sample efficiency, while converging faster at the same compute budget. These results suggest that SSD-Mamba2 provides a practical fusion backbone for scalable, foresightful, and efficient end-to-end motion control.
Pretraining Large Brain Language Model for Active BCI: Silent Speech
Apr 29, 2025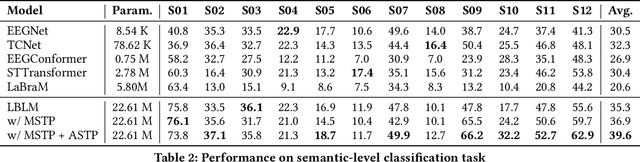
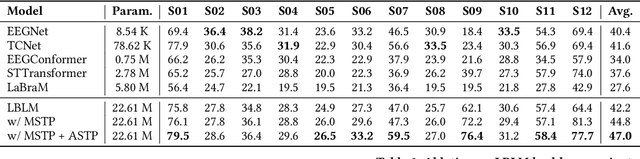
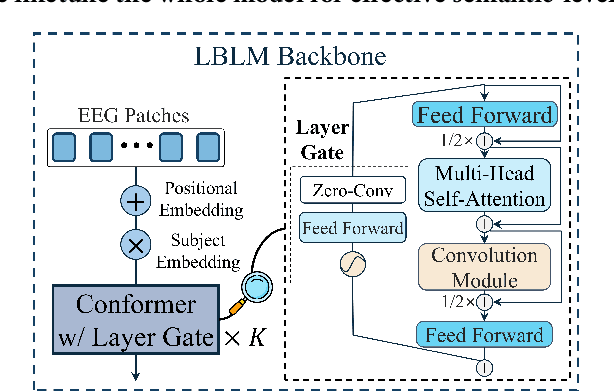
This paper explores silent speech decoding in active brain-computer interface (BCI) systems, which offer more natural and flexible communication than traditional BCI applications. We collected a new silent speech dataset of over 120 hours of electroencephalogram (EEG) recordings from 12 subjects, capturing 24 commonly used English words for language model pretraining and decoding. Following the recent success of pretraining large models with self-supervised paradigms to enhance EEG classification performance, we propose Large Brain Language Model (LBLM) pretrained to decode silent speech for active BCI. To pretrain LBLM, we propose Future Spectro-Temporal Prediction (FSTP) pretraining paradigm to learn effective representations from unlabeled EEG data. Unlike existing EEG pretraining methods that mainly follow a masked-reconstruction paradigm, our proposed FSTP method employs autoregressive modeling in temporal and frequency domains to capture both temporal and spectral dependencies from EEG signals. After pretraining, we finetune our LBLM on downstream tasks, including word-level and semantic-level classification. Extensive experiments demonstrate significant performance gains of the LBLM over fully-supervised and pretrained baseline models. For instance, in the difficult cross-session setting, our model achieves 47.0\% accuracy on semantic-level classification and 39.6\% in word-level classification, outperforming baseline methods by 5.4\% and 7.3\%, respectively. Our research advances silent speech decoding in active BCI systems, offering an innovative solution for EEG language model pretraining and a new dataset for fundamental research.
E2H: A Two-Stage Non-Invasive Neural Signal Driven Humanoid Robotic Whole-Body Control Framework
Oct 03, 2024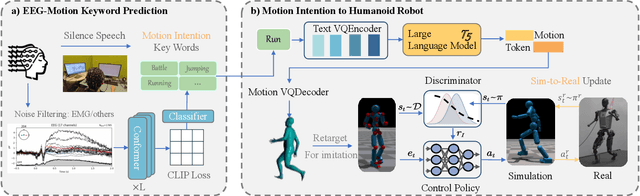

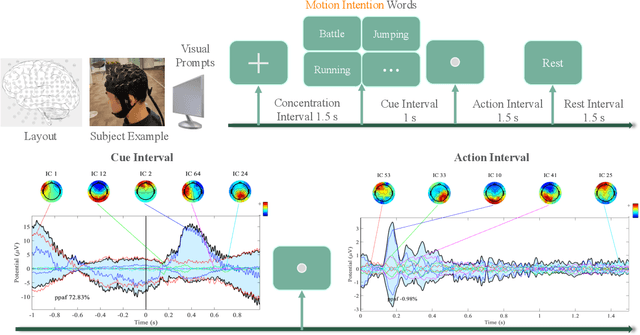
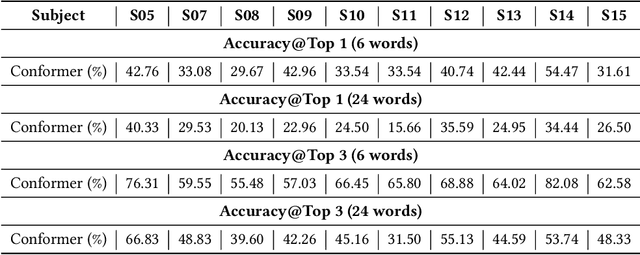
Recent advancements in humanoid robotics, including the integration of hierarchical reinforcement learning-based control and the utilization of LLM planning, have significantly enhanced the ability of robots to perform complex tasks. In contrast to the highly developed humanoid robots, the human factors involved remain relatively unexplored. Directly controlling humanoid robots with the brain has already appeared in many science fiction novels, such as Pacific Rim and Gundam. In this work, we present E2H (EEG-to-Humanoid), an innovative framework that pioneers the control of humanoid robots using high-frequency non-invasive neural signals. As the none-invasive signal quality remains low in decoding precise spatial trajectory, we decompose the E2H framework in an innovative two-stage formation: 1) decoding neural signals (EEG) into semantic motion keywords, 2) utilizing LLM facilitated motion generation with a precise motion imitation control policy to realize humanoid robotics control. The method of directly driving robots with brainwave commands offers a novel approach to human-machine collaboration, especially in situations where verbal commands are impractical, such as in cases of speech impairments, space exploration, or underwater exploration, unlocking significant potential. E2H offers an exciting glimpse into the future, holding immense potential for human-computer interaction.
BELT-2: Bootstrapping EEG-to-Language representation alignment for multi-task brain decoding
Aug 28, 2024



The remarkable success of large language models (LLMs) across various multi-modality applications is well established. However, integrating large language models with humans, or brain dynamics, remains relatively unexplored. In this paper, we introduce BELT-2, a pioneering multi-task model designed to enhance both encoding and decoding performance from EEG signals. To bolster the quality of the EEG encoder, BELT-2 is the first work to innovatively 1) adopt byte-pair encoding (BPE)-level EEG-language alignment and 2) integrate multi-task training and decoding in the EEG domain. Inspired by the idea of \textbf{\textit{Bridging the Brain with GPT}}, we further connect the multi-task EEG encoder with LLMs by utilizing prefix-tuning on intermediary output from the EEG encoder. These innovative efforts make BELT-2 a pioneering breakthrough, making it the first work in the field capable of decoding coherent and readable sentences from non-invasive brain signals. Our experiments highlight significant advancements over prior techniques in both quantitative and qualitative measures, achieving a decoding performance with a BLEU-1 score of 52.2\% on the ZuCo dataset. Furthermore, BELT-2 shows a remarkable improvement ranging from 31\% to 162\% on other translation benchmarks. Codes can be accessed via the provided anonymous link~\footnote{https://anonymous.4open.science/r/BELT-2-0048}.
Enhancing End-to-End Autonomous Driving Systems Through Synchronized Human Behavior Data
Aug 20, 2024



This paper presents a pioneering exploration into the integration of fine-grained human supervision within the autonomous driving domain to enhance system performance. The current advances in End-to-End autonomous driving normally are data-driven and rely on given expert trials. However, this reliance limits the systems' generalizability and their ability to earn human trust. Addressing this gap, our research introduces a novel approach by synchronously collecting data from human and machine drivers under identical driving scenarios, focusing on eye-tracking and brainwave data to guide machine perception and decision-making processes. This paper utilizes the Carla simulation to evaluate the impact brought by human behavior guidance. Experimental results show that using human attention to guide machine attention could bring a significant improvement in driving performance. However, guidance by human intention still remains a challenge. This paper pioneers a promising direction and potential for utilizing human behavior guidance to enhance autonomous systems.
Towards Linguistic Neural Representation Learning and Sentence Retrieval from Electroencephalogram Recordings
Aug 08, 2024



Decoding linguistic information from non-invasive brain signals using EEG has gained increasing research attention due to its vast applicational potential. Recently, a number of works have adopted a generative-based framework to decode electroencephalogram (EEG) signals into sentences by utilizing the power generative capacity of pretrained large language models (LLMs). However, this approach has several drawbacks that hinder the further development of linguistic applications for brain-computer interfaces (BCIs). Specifically, the ability of the EEG encoder to learn semantic information from EEG data remains questionable, and the LLM decoder's tendency to generate sentences based on its training memory can be hard to avoid. These issues necessitate a novel approach for converting EEG signals into sentences. In this paper, we propose a novel two-step pipeline that addresses these limitations and enhances the validity of linguistic EEG decoding research. We first confirm that word-level semantic information can be learned from EEG data recorded during natural reading by training a Conformer encoder via a masked contrastive objective for word-level classification. To achieve sentence decoding results, we employ a training-free retrieval method to retrieve sentences based on the predictions from the EEG encoder. Extensive experiments and ablation studies were conducted in this paper for a comprehensive evaluation of the proposed approach. Visualization of the top prediction candidates reveals that our model effectively groups EEG segments into semantic categories with similar meanings, thereby validating its ability to learn patterns from unspoken EEG recordings. Despite the exploratory nature of this work, these results suggest that our method holds promise for providing more reliable solutions for converting EEG signals into text.
Masked EEG Modeling for Driving Intention Prediction
Aug 08, 2024



Driving under drowsy conditions significantly escalates the risk of vehicular accidents. Although recent efforts have focused on using electroencephalography to detect drowsiness, helping prevent accidents caused by driving in such states, seamless human-machine interaction in driving scenarios requires a more versatile EEG-based system. This system should be capable of understanding a driver's intention while demonstrating resilience to artifacts induced by sudden movements. This paper pioneers a novel research direction in BCI-assisted driving, studying the neural patterns related to driving intentions and presenting a novel method for driving intention prediction. In particular, our preliminary analysis of the EEG signal using independent component analysis suggests a close relation between the intention of driving maneuvers and the neural activities in central-frontal and parietal areas. Power spectral density analysis at a group level also reveals a notable distinction among various driving intentions in the frequency domain. To exploit these brain dynamics, we propose a novel Masked EEG Modeling framework for predicting human driving intentions, including the intention for left turning, right turning, and straight proceeding. Extensive experiments, encompassing comprehensive quantitative and qualitative assessments on public dataset, demonstrate the proposed method is proficient in predicting driving intentions across various vigilance states. Specifically, our model attains an accuracy of 85.19% when predicting driving intentions for drowsy subjects, which shows its promising potential for mitigating traffic accidents related to drowsy driving. Notably, our method maintains over 75% accuracy when more than half of the channels are missing or corrupted, underscoring its adaptability in real-life driving.
BELT:Bootstrapping Electroencephalography-to-Language Decoding and Zero-Shot Sentiment Classification by Natural Language Supervision
Sep 21, 2023



This paper presents BELT, a novel model and learning framework for the pivotal topic of brain-to-language translation research. The translation from noninvasive brain signals into readable natural language has the potential to promote the application scenario as well as the development of brain-computer interfaces (BCI) as a whole. The critical problem in brain signal decoding or brain-to-language translation is the acquisition of semantically appropriate and discriminative EEG representation from a dataset of limited scale and quality. The proposed BELT method is a generic and efficient framework that bootstraps EEG representation learning using off-the-shelf large-scale pretrained language models (LMs). With a large LM's capacity for understanding semantic information and zero-shot generalization, BELT utilizes large LMs trained on Internet-scale datasets to bring significant improvements to the understanding of EEG signals. In particular, the BELT model is composed of a deep conformer encoder and a vector quantization encoder. Semantical EEG representation is achieved by a contrastive learning step that provides natural language supervision. We achieve state-of-the-art results on two featuring brain decoding tasks including the brain-to-language translation and zero-shot sentiment classification. Specifically, our model surpasses the baseline model on both tasks by 5.45% and over 10% and archives a 42.31% BLEU-1 score and 67.32% precision on the main evaluation metrics for translation and zero-shot sentiment classification respectively.
Generalizing Multimodal Variational Methods to Sets
Dec 19, 2022Making sense of multiple modalities can yield a more comprehensive description of real-world phenomena. However, learning the co-representation of diverse modalities is still a long-standing endeavor in emerging machine learning applications and research. Previous generative approaches for multimodal input approximate a joint-modality posterior by uni-modality posteriors as product-of-experts (PoE) or mixture-of-experts (MoE). We argue that these approximations lead to a defective bound for the optimization process and loss of semantic connection among modalities. This paper presents a novel variational method on sets called the Set Multimodal VAE (SMVAE) for learning a multimodal latent space while handling the missing modality problem. By modeling the joint-modality posterior distribution directly, the proposed SMVAE learns to exchange information between multiple modalities and compensate for the drawbacks caused by factorization. In public datasets of various domains, the experimental results demonstrate that the proposed method is applicable to order-agnostic cross-modal generation while achieving outstanding performance compared to the state-of-the-art multimodal methods. The source code for our method is available online https://anonymous.4open.science/r/SMVAE-9B3C/.