 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuGaze: Reshaping the future BCI
Apr 21, 2025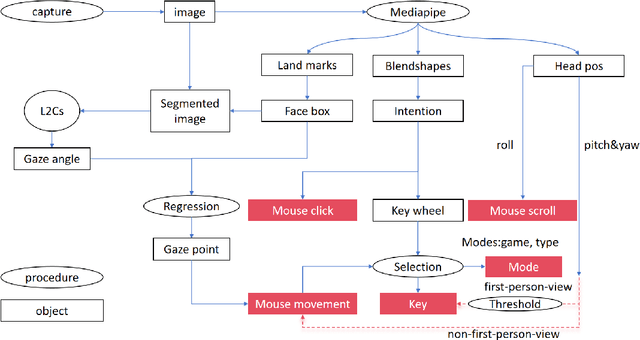

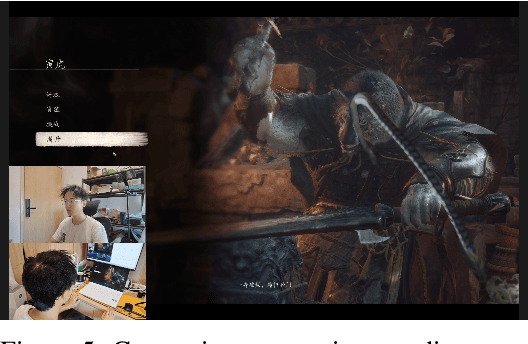
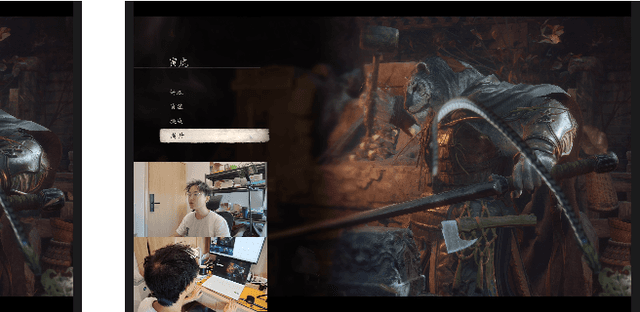
Traditional brain-computer interfaces (BCIs), reliant on costly electroencephalography or invasive implants, struggle with complex human-computer interactions due to setup complexity and limited precision. We present NeuGaze, a novel webcam-based system that leverages eye gaze, head movements, and facial expressions to enable intuitive, real-time control using only a standard 30 Hz webcam, often pre-installed in laptops. Requiring minimal calibration, NeuGaze achieves performance comparable to conventional inputs, supporting precise cursor navigation, key triggering via an efficient skill wheel, and dynamic gaming interactions, such as defeating formidable opponents in first-person games. By harnessing preserved neck-up functionalities in motor-impaired individuals, NeuGaze eliminates the need for specialized hardware, offering a low-cost, accessible alternative to BCIs. This paradigm empowers diverse applications, from assistive technology to entertainment, redefining human-computer interaction for motor-impaired users. Project is at \href{https://github.com/NeuSpeech/NeuGaze}{github.com/NeuSpeech/NeuGaze}.
Efficient Gravitational Wave Parameter Estimation via Knowledge Distillation: A ResNet1D-IAF Approach
Dec 11, 2024With the rapid development of gravitational wave astronomy, the increasing number of detected events necessitates efficient methods for parameter estimation and model updates. This study presents a novel approach using knowledge distillation techniques to enhance computational efficiency in gravitational wave analysis. We develop a framework combining ResNet1D and Inverse Autoregressive Flow (IAF) architectures, where knowledge from a complex teacher model is transferred to a lighter student model. Our experimental results show that the student model achieves a validation loss of 3.70 with optimal configuration (40,100,0.75), compared to the teacher model's 4.09, while reducing the number of parameters by 43\%. The Jensen-Shannon divergence between teacher and student models remains below 0.0001 across network layers, indicating successful knowledge transfer. By optimizing ResNet layers (7-16) and hidden features (70-120), we achieve a 35\% reduction in inference time while maintaining parameter estimation accuracy. This work demonstrates significant improvements in computational efficiency for gravitational wave data analysis, providing valuable insights for real-time event processing.
Adaptive Epsilon Adversarial Training for Robust Gravitational Wave Parameter Estimation Using Normalizing Flows
Dec 10, 2024Adversarial training with Normalizing Flow (NF) models is an emerging research area aimed at improving model robustness through adversarial samples. In this study, we focus on applying adversarial training to NF models for gravitational wave parameter estimation. We propose an adaptive epsilon method for Fast Gradient Sign Method (FGSM) adversarial training, which dynamically adjusts perturbation strengths based on gradient magnitudes using logarithmic scaling. Our hybrid architecture, combining ResNet and Inverse Autoregressive Flow, reduces the Negative Log Likelihood (NLL) loss by 47\% under FGSM attacks compared to the baseline model, while maintaining an NLL of 4.2 on clean data (only 5\% higher than the baseline). For perturbation strengths between 0.01 and 0.1, our model achieves an average NLL of 5.8, outperforming both fixed-epsilon (NLL: 6.7) and progressive-epsilon (NLL: 7.2) methods. Under stronger Projected Gradient Descent attacks with perturbation strength of 0.05, our model maintains an NLL of 6.4, demonstrating superior robustness while avoiding catastrophic overfitting.
NeuGPT: Unified multi-modal Neural GPT
Oct 28, 2024This paper introduces NeuGPT, a groundbreaking multi-modal language generation model designed to harmonize the fragmented landscape of neural recording research. Traditionally, studies in the field have been compartmentalized by signal type, with EEG, MEG, ECoG, SEEG, fMRI, and fNIRS data being analyzed in isolation. Recognizing the untapped potential for cross-pollination and the adaptability of neural signals across varying experimental conditions, we set out to develop a unified model capable of interfacing with multiple modalities. Drawing inspiration from the success of pre-trained large models in NLP, computer vision, and speech processing, NeuGPT is architected to process a diverse array of neural recordings and interact with speech and text data. Our model mainly focus on brain-to-text decoding, improving SOTA from 6.94 to 12.92 on BLEU-1 and 6.93 to 13.06 on ROUGE-1F. It can also simulate brain signals, thereby serving as a novel neural interface. Code is available at \href{https://github.com/NeuSpeech/NeuGPT}{NeuSpeech/NeuGPT (https://github.com/NeuSpeech/NeuGPT) .}
E2H: A Two-Stage Non-Invasive Neural Signal Driven Humanoid Robotic Whole-Body Control Framework
Oct 03, 2024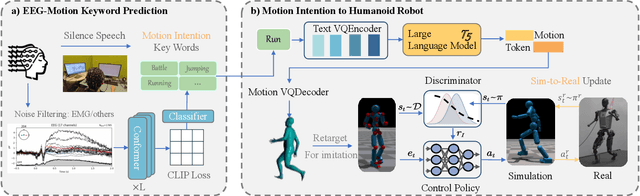

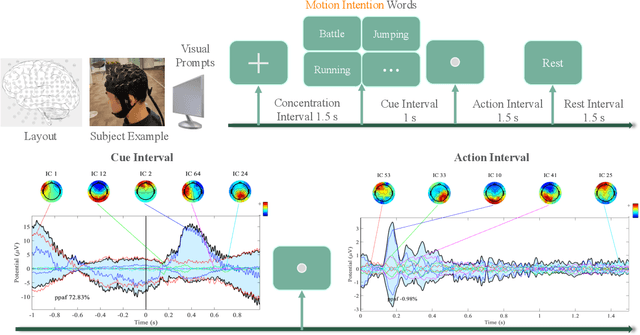
Recent advancements in humanoid robotics, including the integration of hierarchical reinforcement learning-based control and the utilization of LLM planning, have significantly enhanced the ability of robots to perform complex tasks. In contrast to the highly developed humanoid robots, the human factors involved remain relatively unexplored. Directly controlling humanoid robots with the brain has already appeared in many science fiction novels, such as Pacific Rim and Gundam. In this work, we present E2H (EEG-to-Humanoid), an innovative framework that pioneers the control of humanoid robots using high-frequency non-invasive neural signals. As the none-invasive signal quality remains low in decoding precise spatial trajectory, we decompose the E2H framework in an innovative two-stage formation: 1) decoding neural signals (EEG) into semantic motion keywords, 2) utilizing LLM facilitated motion generation with a precise motion imitation control policy to realize humanoid robotics control. The method of directly driving robots with brainwave commands offers a novel approach to human-machine collaboration, especially in situations where verbal commands are impractical, such as in cases of speech impairments, space exploration, or underwater exploration, unlocking significant potential. E2H offers an exciting glimpse into the future, holding immense potential for human-computer interaction.
MAD: Multi-Alignment MEG-to-Text Decoding
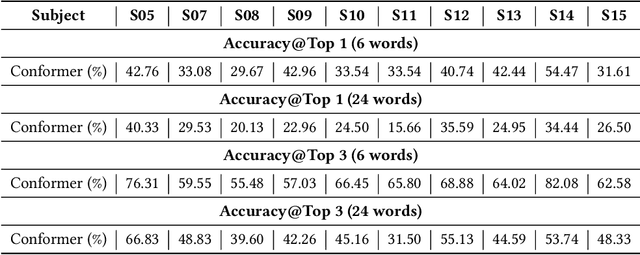
Jun 03, 2024Deciphering language from brain activity is a crucial task in brain-computer interface (BCI) research. Non-invasive cerebral signaling techniques including electroencephalography (EEG) and magnetoencephalography (MEG) are becoming increasingly popular due to their safety and practicality, avoiding invasive electrode implantation. However, current works under-investigated three points: 1) a predominant focus on EEG with limited exploration of MEG, which provides superior signal quality; 2) poor performance on unseen text, indicating the need for models that can better generalize to diverse linguistic contexts; 3) insufficient integration of information from other modalities, which could potentially constrain our capacity to comprehensively understand the intricate dynamics of brain activity. This study presents a novel approach for translating MEG signals into text using a speech-decoding framework with multiple alignments. Our method is the first to introduce an end-to-end multi-alignment framework for totally unseen text generation directly from MEG signals. We achieve an impressive BLEU-1 score on the $\textit{GWilliams}$ dataset, significantly outperforming the baseline from 5.49 to 10.44 on the BLEU-1 metric. This improvement demonstrates the advancement of our model towards real-world applications and underscores its potential in advancing BCI research. Code is available at $\href{https://github.com/NeuSpeech/MAD-MEG2text}{https://github.com/NeuSpeech/MAD-MEG2text}$.
Are EEG-to-Text Models Working?
May 10, 2024This work critically analyzes existing models for open-vocabulary EEG-to-Text translation. We identify a crucial limitation: previous studies often employed implicit teacher-forcing during evaluation, artificially inflating performance metrics. Additionally, they lacked a critical benchmark - comparing model performance on pure noise inputs. We propose a methodology to differentiate between models that truly learn from EEG signals and those that simply memorize training data. Our analysis reveals that model performance on noise data can be comparable to that on EEG data. These findings highlight the need for stricter evaluation practices in EEG-to-Text research, emphasizing transparent reporting and rigorous benchmarking with noise inputs. This approach will lead to more reliable assessments of model capabilities and pave the way for robust EEG-to-Text communication systems.
Decode Neural signal as Speech
Mar 04, 2024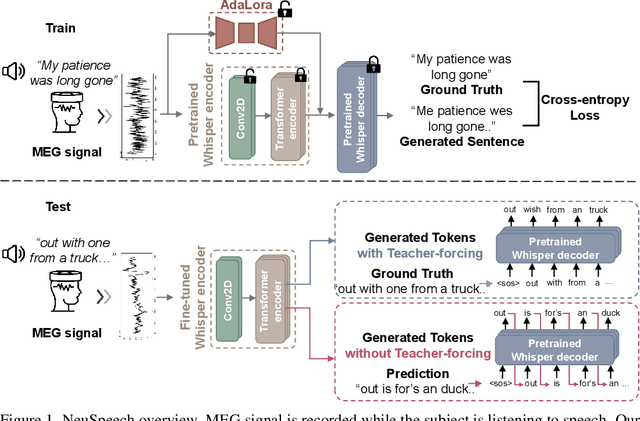
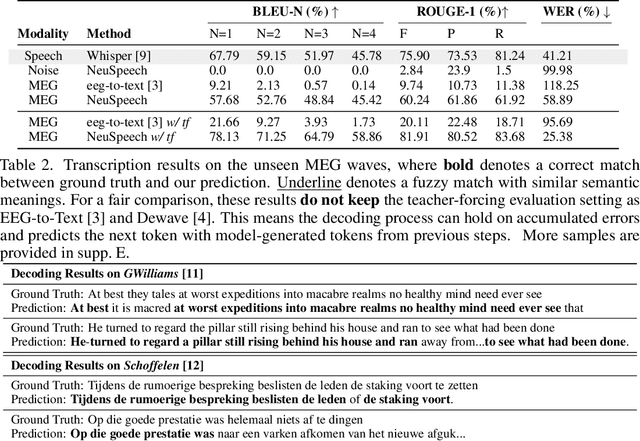
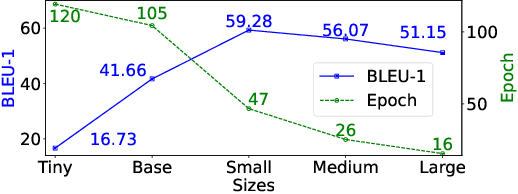
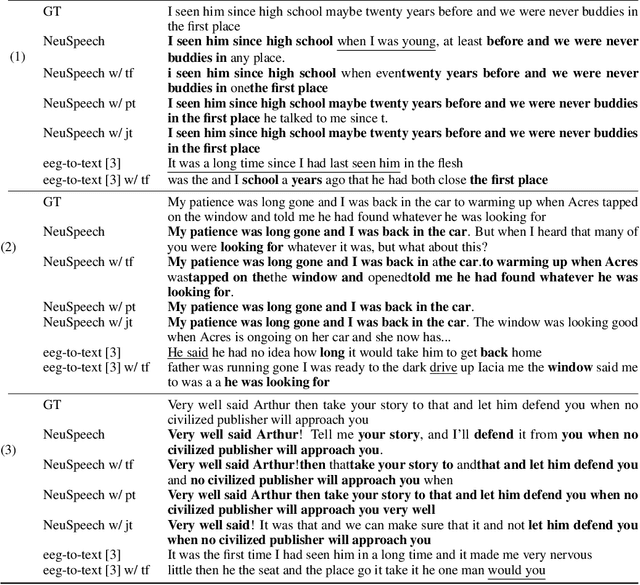
Decoding language from brain dynamics is an important open direction in the realm of brain-computer interface (BCI), especially considering the rapid growth of large language models. Compared to invasive-based signals which require electrode implantation surgery, non-invasive neural signals (e.g. EEG, MEG) have attracted increasing attention considering their safety and generality. However, the exploration is not adequate in three aspects: 1) previous methods mainly focus on EEG but none of the previous works address this problem on MEG with better signal quality; 2) prior works have predominantly used ``teacher-forcing" during generative decoding, which is impractical; 3) prior works are mostly ``BART-based" not fully auto-regressive, which performs better in other sequence tasks. In this paper, we explore the brain-to-text translation of MEG signals in a speech-decoding formation. Here we are the first to investigate a cross-attention-based ``whisper" model for generating text directly from MEG signals without teacher forcing. Our model achieves impressive BLEU-1 scores of 60.30 and 52.89 without pretraining \& teacher-forcing on two major datasets (\textit{GWilliams} and \textit{Schoffelen}). This paper conducts a comprehensive review to understand how speech decoding formation performs on the neural decoding tasks, including pretraining initialization, training \& evaluation set splitting, augmentation, and scaling law.
Mapping EEG Signals to Visual Stimuli: A Deep Learning Approach to Match vs. Mismatch Classification
Sep 08, 2023



Existing approaches to modeling associations between visual stimuli and brain responses are facing difficulties in handling between-subject variance and model generalization. Inspired by the recent progress in modeling speech-brain response, we propose in this work a ``match-vs-mismatch'' deep learning model to classify whether a video clip induces excitatory responses in recorded EEG signals and learn associations between the visual content and corresponding neural recordings. Using an exclusive experimental dataset, we demonstrate that the proposed model is able to achieve the highest accuracy on unseen subjects as compared to other baseline models. Furthermore, we analyze the inter-subject noise using a subject-level silhouette score in the embedding space and show that the developed model is able to mitigate inter-subject noise and significantly reduce the silhouette score. Moreover, we examine the Grad-CAM activation score and show that the brain regions associated with language processing contribute most to the model predictions, followed by regions associated with visual processing. These results have the potential to facilitate the development of neural recording-based video reconstruction and its related applications.
All in One: Exploring Unified Vision-Language Tracking with Multi-Modal Alignment
Jul 07, 2023



Current mainstream vision-language (VL) tracking framework consists of three parts, \ie a visual feature extractor, a language feature extractor, and a fusion model. To pursue better performance, a natural modus operandi for VL tracking is employing customized and heavier unimodal encoders, and multi-modal fusion models. Albeit effective, existing VL trackers separate feature extraction and feature integration, resulting in extracted features that lack semantic guidance and have limited target-aware capability in complex scenarios, \eg similar distractors and extreme illumination. In this work, inspired by the recent success of exploring foundation models with unified architecture for both natural language and computer vision tasks, we propose an All-in-One framework, which learns joint feature extraction and interaction by adopting a unified transformer backbone. Specifically, we mix raw vision and language signals to generate language-injected vision tokens, which we then concatenate before feeding into the unified backbone architecture. This approach achieves feature integration in a unified backbone, removing the need for carefully-designed fusion modules and resulting in a more effective and efficient VL tracking framework. To further improve the learning efficiency, we introduce a multi-modal alignment module based on cross-modal and intra-modal contrastive objectives, providing more reasonable representations for the unified All-in-One transformer backbone. Extensive experiments on five benchmarks, \ie OTB99-L, TNL2K, LaSOT, LaSOT$_{\rm Ext}$ and WebUAV-3M, demonstrate the superiority of the proposed tracker against existing state-of-the-arts on VL tracking. Codes will be made publicly available.