 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuGPT: Unified multi-modal Neural GPT
Oct 28, 2024This paper introduces NeuGPT, a groundbreaking multi-modal language generation model designed to harmonize the fragmented landscape of neural recording research. Traditionally, studies in the field have been compartmentalized by signal type, with EEG, MEG, ECoG, SEEG, fMRI, and fNIRS data being analyzed in isolation. Recognizing the untapped potential for cross-pollination and the adaptability of neural signals across varying experimental conditions, we set out to develop a unified model capable of interfacing with multiple modalities. Drawing inspiration from the success of pre-trained large models in NLP, computer vision, and speech processing, NeuGPT is architected to process a diverse array of neural recordings and interact with speech and text data. Our model mainly focus on brain-to-text decoding, improving SOTA from 6.94 to 12.92 on BLEU-1 and 6.93 to 13.06 on ROUGE-1F. It can also simulate brain signals, thereby serving as a novel neural interface. Code is available at \href{https://github.com/NeuSpeech/NeuGPT}{NeuSpeech/NeuGPT (https://github.com/NeuSpeech/NeuGPT) .}
MIPI 2024 Challenge on Few-shot RAW Image Denoising: Methods and Results
Jun 11, 2024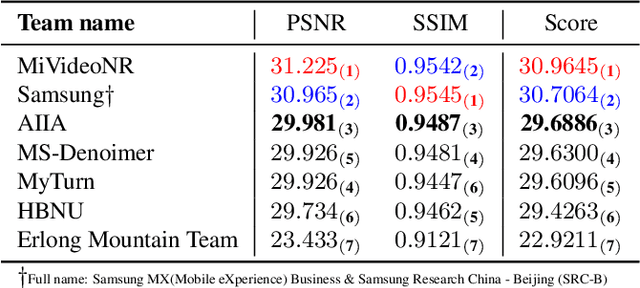
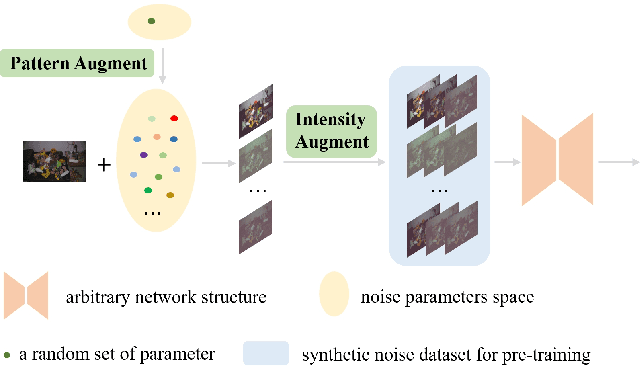

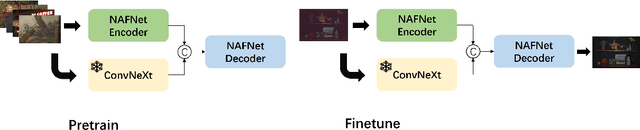
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Few-shot RAW Image Denoising track on MIPI 2024. In total, 165 participants were successfully registered, and 7 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art erformance on Few-shot RAW Image Denoising. More details of this challenge and the link to the dataset can be found at https://mipichallenge.org/MIPI2024.
MAD: Multi-Alignment MEG-to-Text Decoding
Jun 03, 2024Deciphering language from brain activity is a crucial task in brain-computer interface (BCI) research. Non-invasive cerebral signaling techniques including electroencephalography (EEG) and magnetoencephalography (MEG) are becoming increasingly popular due to their safety and practicality, avoiding invasive electrode implantation. However, current works under-investigated three points: 1) a predominant focus on EEG with limited exploration of MEG, which provides superior signal quality; 2) poor performance on unseen text, indicating the need for models that can better generalize to diverse linguistic contexts; 3) insufficient integration of information from other modalities, which could potentially constrain our capacity to comprehensively understand the intricate dynamics of brain activity. This study presents a novel approach for translating MEG signals into text using a speech-decoding framework with multiple alignments. Our method is the first to introduce an end-to-end multi-alignment framework for totally unseen text generation directly from MEG signals. We achieve an impressive BLEU-1 score on the $\textit{GWilliams}$ dataset, significantly outperforming the baseline from 5.49 to 10.44 on the BLEU-1 metric. This improvement demonstrates the advancement of our model towards real-world applications and underscores its potential in advancing BCI research. Code is available at $\href{https://github.com/NeuSpeech/MAD-MEG2text}{https://github.com/NeuSpeech/MAD-MEG2text}$.
Are EEG-to-Text Models Working?
May 10, 2024This work critically analyzes existing models for open-vocabulary EEG-to-Text translation. We identify a crucial limitation: previous studies often employed implicit teacher-forcing during evaluation, artificially inflating performance metrics. Additionally, they lacked a critical benchmark - comparing model performance on pure noise inputs. We propose a methodology to differentiate between models that truly learn from EEG signals and those that simply memorize training data. Our analysis reveals that model performance on noise data can be comparable to that on EEG data. These findings highlight the need for stricter evaluation practices in EEG-to-Text research, emphasizing transparent reporting and rigorous benchmarking with noise inputs. This approach will lead to more reliable assessments of model capabilities and pave the way for robust EEG-to-Text communication systems.