 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriple-Phase Sequential Fusion Network for Hepatobiliary Phase Liver MRI Synthesis
Apr 24, 2026Gadoxetate disodium-enhanced MRI is essential for the detection and characterization of hepatocellular carcinoma. However, acquisition of the hepatobiliary phase (HBP) requires a prolonged post-contrast delay, which reduces workflow efficiency and increases the risk of motion artifacts. In this study, we propose a Triple-Phase Sequential Fusion Network (TriPF-Net) to synthesize HBP images by leveraging the sequential information from pre-HBP sequences: while T1-weighted imaging serves as the indispensable baseline, the model adaptively integrates arterial-phase (AP) and venous-phase (VP) features when available. By modeling the tissue-specific contrast uptake and excretion dynamics across these three phases, TriPF-Net ensures robust HBP synthesis even under the stochastic absence of one or both dynamic contrast-enhanced sequences. The framework comprises an Enhanced Region-Guided Encoder and a Dynamic Feature Unification Module, optimized with a Region-Guided Sequential Fusion Loss to maintain physiological consistency. In addition, clinical variables, including age, sex, total bilirubin, and albumin, are incorporated to enhance physiological consistency. Compared with conventional methods, TriPF-Net achieved superior performance on datasets from two centers. On the internal dataset, the model achieved an MAE of 10.65, a PSNR of 23.27, and an SSIM of 0.76. On the external validation dataset, the corresponding values were 12.41, 23.11, and 0.78, respectively. This flexible solution enhances clinical workflow and lesion depiction, potentially eliminating the need for delayed HBP acquisition in HCC imaging.
From Prompt Optimization to Multi-Dimensional Credibility Evaluation: Enhancing Trustworthiness of Chinese LLM-Generated Liver MRI Reports
Oct 27, 2025Large language models (LLMs) have demonstrated promising performance in generating diagnostic conclusions from imaging findings, thereby supporting radiology reporting, trainee education, and quality control. However, systematic guidance on how to optimize prompt design across different clinical contexts remains underexplored. Moreover, a comprehensive and standardized framework for assessing the trustworthiness of LLM-generated radiology reports is yet to be established. This study aims to enhance the trustworthiness of LLM-generated liver MRI reports by introducing a Multi-Dimensional Credibility Assessment (MDCA) framework and providing guidance on institution-specific prompt optimization. The proposed framework is applied to evaluate and compare the performance of several advanced LLMs, including Kimi-K2-Instruct-0905, Qwen3-235B-A22B-Instruct-2507, DeepSeek-V3, and ByteDance-Seed-OSS-36B-Instruct, using the SiliconFlow platform.
Enhanced Generative Structure Prior for Chinese Text Image Super-resolution
Aug 11, 2025Faithful text image super-resolution (SR) is challenging because each character has a unique structure and usually exhibits diverse font styles and layouts. While existing methods primarily focus on English text, less attention has been paid to more complex scripts like Chinese. In this paper, we introduce a high-quality text image SR framework designed to restore the precise strokes of low-resolution (LR) Chinese characters. Unlike methods that rely on character recognition priors to regularize the SR task, we propose a novel structure prior that offers structure-level guidance to enhance visual quality. Our framework incorporates this structure prior within a StyleGAN model, leveraging its generative capabilities for restoration. To maintain the integrity of character structures while accommodating various font styles and layouts, we implement a codebook-based mechanism that restricts the generative space of StyleGAN. Each code in the codebook represents the structure of a specific character, while the vector $w$ in StyleGAN controls the character's style, including typeface, orientation, and location. Through the collaborative interaction between the codebook and style, we generate a high-resolution structure prior that aligns with LR characters both spatially and structurally. Experiments demonstrate that this structure prior provides robust, character-specific guidance, enabling the accurate restoration of clear strokes in degraded characters, even for real-world LR Chinese text with irregular layouts. Our code and pre-trained models will be available at https://github.com/csxmli2016/MARCONetPlusPlus
AnimateAnywhere: Rouse the Background in Human Image Animation
Apr 28, 2025



Human image animation aims to generate human videos of given characters and backgrounds that adhere to the desired pose sequence. However, existing methods focus more on human actions while neglecting the generation of background, which typically leads to static results or inharmonious movements. The community has explored camera pose-guided animation tasks, yet preparing the camera trajectory is impractical for most entertainment applications and ordinary users. As a remedy, we present an AnimateAnywhere framework, rousing the background in human image animation without requirements on camera trajectories. In particular, based on our key insight that the movement of the human body often reflects the motion of the background, we introduce a background motion learner (BML) to learn background motions from human pose sequences. To encourage the model to learn more accurate cross-frame correspondences, we further deploy an epipolar constraint on the 3D attention map. Specifically, the mask used to suppress geometrically unreasonable attention is carefully constructed by combining an epipolar mask and the current 3D attention map. Extensive experiments demonstrate that our AnimateAnywhere effectively learns the background motion from human pose sequences, achieving state-of-the-art performance in generating human animation results with vivid and realistic backgrounds. The source code and model will be available at https://github.com/liuxiaoyu1104/AnimateAnywhere.
NTIRE 2025 Challenge on Real-World Face Restoration: Methods and Results
Apr 20, 2025This paper provides a review of the NTIRE 2025 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural, realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. The track of the challenge evaluates performance using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 141 registrants, with 13 teams submitting valid models, and ultimately, 10 teams achieved a valid score in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
Omegance: A Single Parameter for Various Granularities in Diffusion-Based Synthesis
Nov 26, 2024



In this work, we introduce a single parameter $\omega$, to effectively control granularity in diffusion-based synthesis. This parameter is incorporated during the denoising steps of the diffusion model's reverse process. Our approach does not require model retraining, architectural modifications, or additional computational overhead during inference, yet enables precise control over the level of details in the generated outputs. Moreover, spatial masks or denoising schedules with varying $\omega$ values can be applied to achieve region-specific or timestep-specific granularity control. Prior knowledge of image composition from control signals or reference images further facilitates the creation of precise $\omega$ masks for granularity control on specific objects. To highlight the parameter's role in controlling subtle detail variations, the technique is named Omegance, combining "omega" and "nuance". Our method demonstrates impressive performance across various image and video synthesis tasks and is adaptable to advanced diffusion models. The code is available at https://github.com/itsmag11/Omegance.
Inherently Interpretable Tree Ensemble Learning
Oct 24, 2024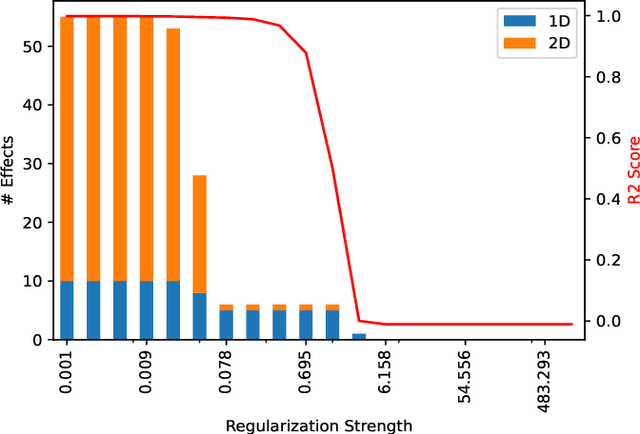
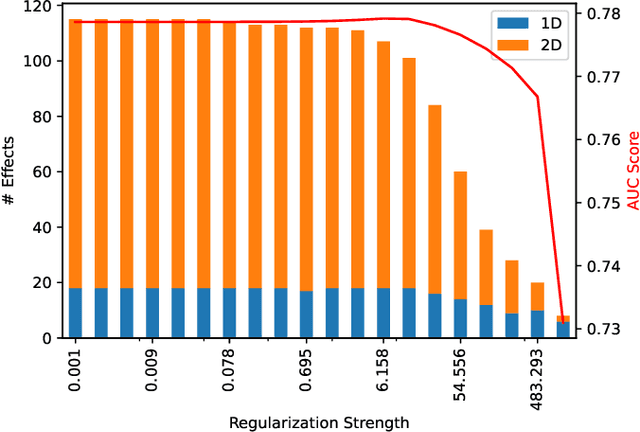
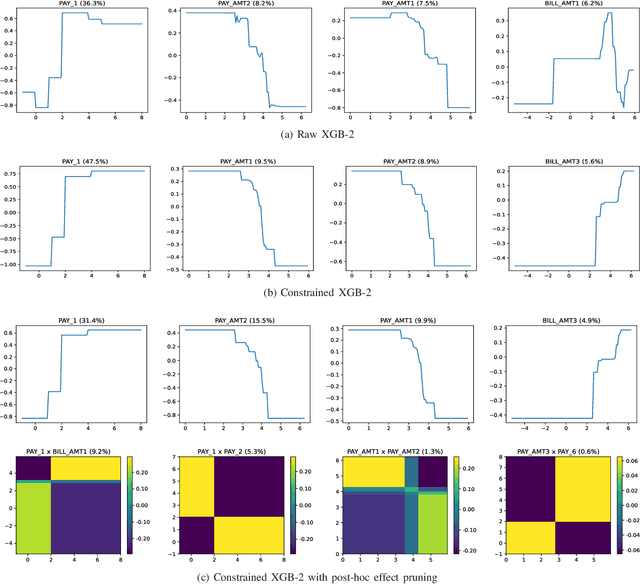
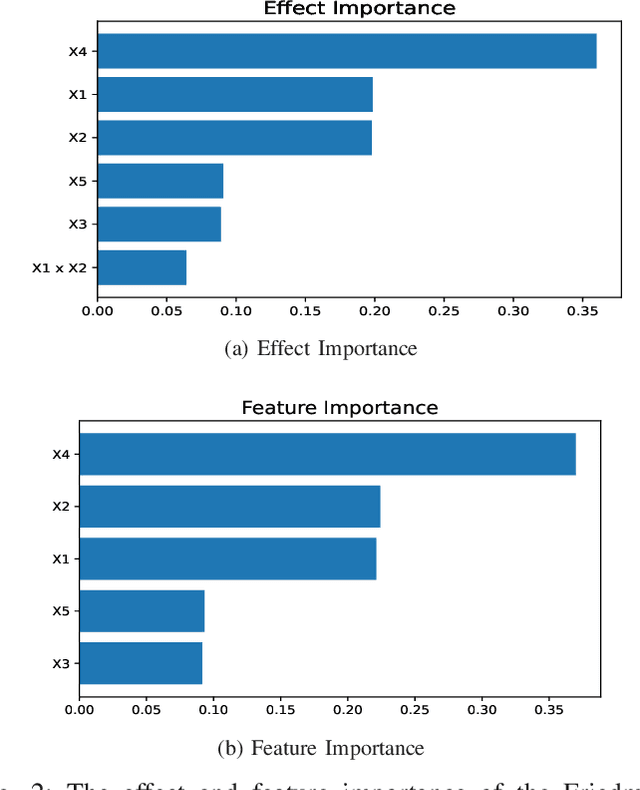
Tree ensemble models like random forests and gradient boosting machines are widely used in machine learning due to their excellent predictive performance. However, a high-performance ensemble consisting of a large number of decision trees lacks sufficient transparency and explainability. In this paper, we demonstrate that when shallow decision trees are used as base learners, the ensemble learning algorithms can not only become inherently interpretable subject to an equivalent representation as the generalized additive models but also sometimes lead to better generalization performance. First, an interpretation algorithm is developed that converts the tree ensemble into the functional ANOVA representation with inherent interpretability. Second, two strategies are proposed to further enhance the model interpretability, i.e., by adding constraints in the model training stage and post-hoc effect pruning. Experiments on simulations and real-world datasets show that our proposed methods offer a better trade-off between model interpretation and predictive performance, compared with its counterpart benchmarks.
Combining Generative and Geometry Priors for Wide-Angle Portrait Correction
Oct 13, 2024Wide-angle lens distortion in portrait photography presents a significant challenge for capturing photo-realistic and aesthetically pleasing images. Such distortions are especially noticeable in facial regions. In this work, we propose encapsulating the generative face prior as a guided natural manifold to facilitate the correction of facial regions. Moreover, a notable central symmetry relationship exists in the non-face background, yet it has not been explored in the correction process. This geometry prior motivates us to introduce a novel constraint to explicitly enforce symmetry throughout the correction process, thereby contributing to a more visually appealing and natural correction in the non-face region. Experiments demonstrate that our approach outperforms previous methods by a large margin, excelling not only in quantitative measures such as line straightness and shape consistency metrics but also in terms of perceptual visual quality. All the code and models are available at https://github.com/Dev-Mrha/DualPriorsCorrection.
AITTI: Learning Adaptive Inclusive Token for Text-to-Image Generation
Jun 18, 2024
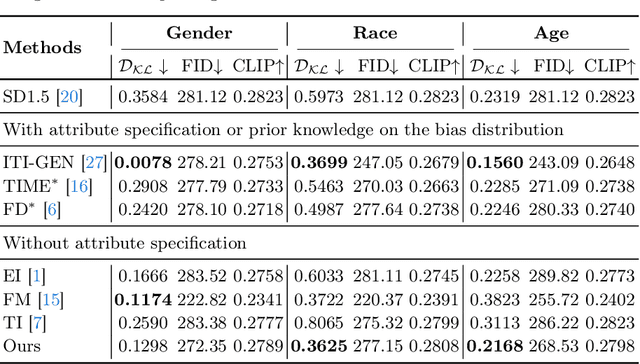
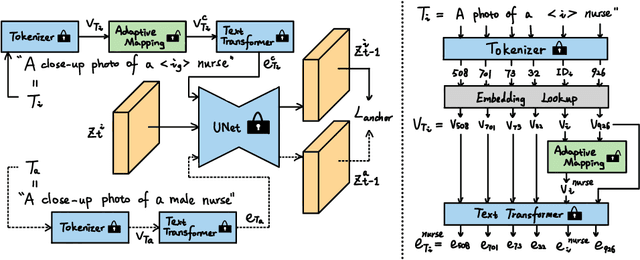
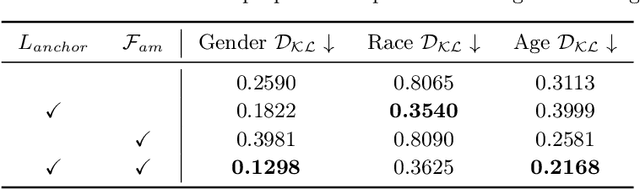
Despite the high-quality results of text-to-image generation, stereotypical biases have been spotted in their generated contents, compromising the fairness of generative models. In this work, we propose to learn adaptive inclusive tokens to shift the attribute distribution of the final generative outputs. Unlike existing de-biasing approaches, our method requires neither explicit attribute specification nor prior knowledge of the bias distribution. Specifically, the core of our method is a lightweight adaptive mapping network, which can customize the inclusive tokens for the concepts to be de-biased, making the tokens generalizable to unseen concepts regardless of their original bias distributions. This is achieved by tuning the adaptive mapping network with a handful of balanced and inclusive samples using an anchor loss. Experimental results demonstrate that our method outperforms previous bias mitigation methods without attribute specification while preserving the alignment between generative results and text descriptions. Moreover, our method achieves comparable performance to models that require specific attributes or editing directions for generation. Extensive experiments showcase the effectiveness of our adaptive inclusive tokens in mitigating stereotypical bias in text-to-image generation. The code will be available at https://github.com/itsmag11/AITTI.
MIPI 2024 Challenge on Few-shot RAW Image Denoising: Methods and Results
Jun 11, 2024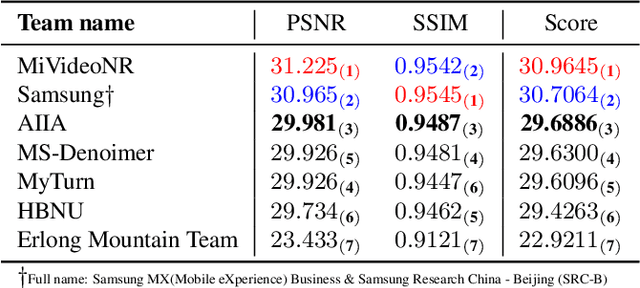
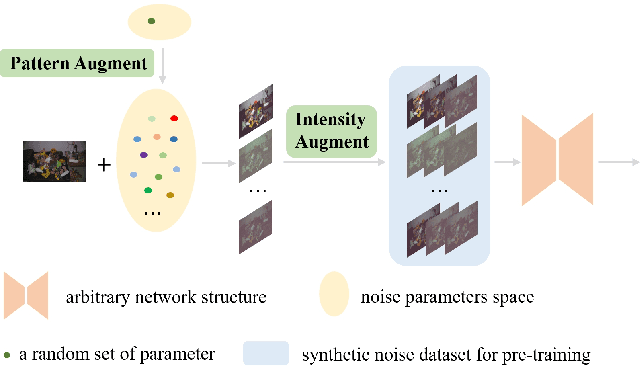

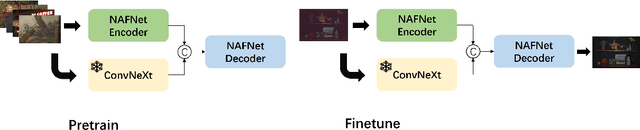
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Few-shot RAW Image Denoising track on MIPI 2024. In total, 165 participants were successfully registered, and 7 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art erformance on Few-shot RAW Image Denoising. More details of this challenge and the link to the dataset can be found at https://mipichallenge.org/MIPI2024.