 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildDepth: A Multimodal Dataset for 3D Wildlife Perception and Depth Estimation
Mar 17, 2026Depth estimation and 3D reconstruction have been extensively studied as core topics in computer vision. Starting from rigid objects with relatively simple geometric shapes, such as vehicles, the research has expanded to address general objects, including challenging deformable objects, such as humans and animals. However, for the animal, in particular, the majority of existing models are trained based on datasets without metric scale, which can help validate image-only models. To address this limitation, we present WildDepth, a multimodal dataset and benchmark suite for depth estimation, behavior detection, and 3D reconstruction from diverse categories of animals ranging from domestic to wild environments with synchronized RGB and LiDAR. Experimental results show that the use of multi-modal data improves depth reliability by up to 10% RMSE, while RGB-LiDAR fusion enhances 3D reconstruction fidelity by 12% in Chamfer distance. By releasing WildDepth and its benchmarks, we aim to foster robust multimodal perception systems that generalize across domains.
According to Me: Long-Term Personalized Referential Memory QA
Mar 02, 2026Personalized AI assistants must recall and reason over long-term user memory, which naturally spans multiple modalities and sources such as images, videos, and emails. However, existing Long-term Memory benchmarks focus primarily on dialogue history, failing to capture realistic personalized references grounded in lived experience. We introduce ATM-Bench, the first benchmark for multimodal, multi-source personalized referential Memory QA. ATM-Bench contains approximately four years of privacy-preserving personal memory data and human-annotated question-answer pairs with ground-truth memory evidence, including queries that require resolving personal references, multi-evidence reasoning from multi-source and handling conflicting evidence. We propose Schema-Guided Memory (SGM) to structurally represent memory items originated from different sources. In experiments, we implement 5 state-of-the-art memory systems along with a standard RAG baseline and evaluate variants with different memory ingestion, retrieval, and answer generation techniques. We find poor performance (under 20\% accuracy) on the ATM-Bench-Hard set, and that SGM improves performance over Descriptive Memory commonly adopted in prior works. Code available at: https://github.com/JingbiaoMei/ATM-Bench
Omegance: A Single Parameter for Various Granularities in Diffusion-Based Synthesis
Nov 26, 2024



In this work, we introduce a single parameter $\omega$, to effectively control granularity in diffusion-based synthesis. This parameter is incorporated during the denoising steps of the diffusion model's reverse process. Our approach does not require model retraining, architectural modifications, or additional computational overhead during inference, yet enables precise control over the level of details in the generated outputs. Moreover, spatial masks or denoising schedules with varying $\omega$ values can be applied to achieve region-specific or timestep-specific granularity control. Prior knowledge of image composition from control signals or reference images further facilitates the creation of precise $\omega$ masks for granularity control on specific objects. To highlight the parameter's role in controlling subtle detail variations, the technique is named Omegance, combining "omega" and "nuance". Our method demonstrates impressive performance across various image and video synthesis tasks and is adaptable to advanced diffusion models. The code is available at https://github.com/itsmag11/Omegance.
AITTI: Learning Adaptive Inclusive Token for Text-to-Image Generation
Jun 18, 2024
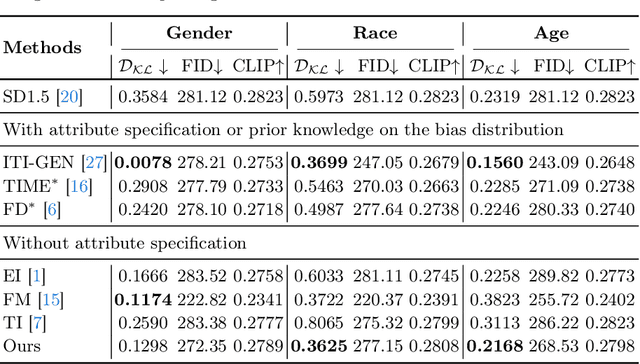
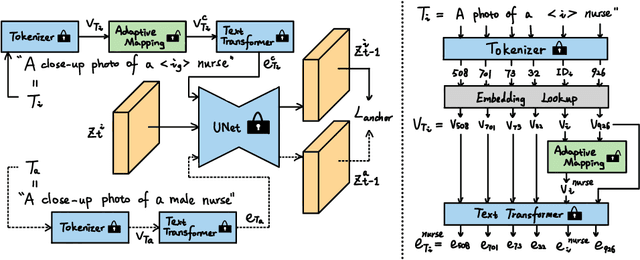
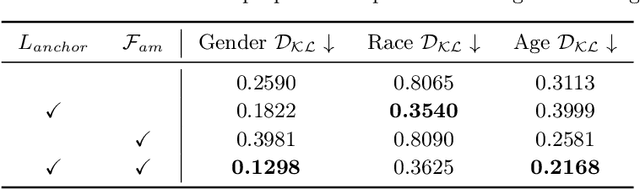
Despite the high-quality results of text-to-image generation, stereotypical biases have been spotted in their generated contents, compromising the fairness of generative models. In this work, we propose to learn adaptive inclusive tokens to shift the attribute distribution of the final generative outputs. Unlike existing de-biasing approaches, our method requires neither explicit attribute specification nor prior knowledge of the bias distribution. Specifically, the core of our method is a lightweight adaptive mapping network, which can customize the inclusive tokens for the concepts to be de-biased, making the tokens generalizable to unseen concepts regardless of their original bias distributions. This is achieved by tuning the adaptive mapping network with a handful of balanced and inclusive samples using an anchor loss. Experimental results demonstrate that our method outperforms previous bias mitigation methods without attribute specification while preserving the alignment between generative results and text descriptions. Moreover, our method achieves comparable performance to models that require specific attributes or editing directions for generation. Extensive experiments showcase the effectiveness of our adaptive inclusive tokens in mitigating stereotypical bias in text-to-image generation. The code will be available at https://github.com/itsmag11/AITTI.
When StyleGAN Meets Stable Diffusion: a $\mathscr{W}_+$ Adapter for Personalized Image Generation
Nov 29, 2023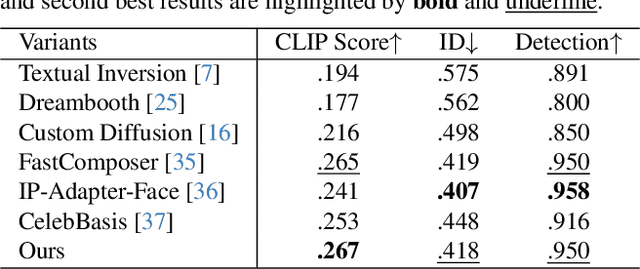
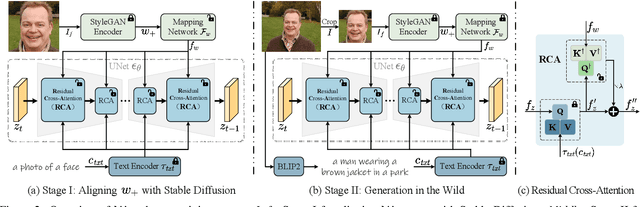
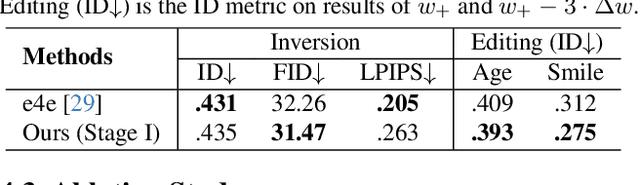

Text-to-image diffusion models have remarkably excelled in producing diverse, high-quality, and photo-realistic images. This advancement has spurred a growing interest in incorporating specific identities into generated content. Most current methods employ an inversion approach to embed a target visual concept into the text embedding space using a single reference image. However, the newly synthesized faces either closely resemble the reference image in terms of facial attributes, such as expression, or exhibit a reduced capacity for identity preservation. Text descriptions intended to guide the facial attributes of the synthesized face may fall short, owing to the intricate entanglement of identity information with identity-irrelevant facial attributes derived from the reference image. To address these issues, we present the novel use of the extended StyleGAN embedding space $\mathcal{W}_+$, to achieve enhanced identity preservation and disentanglement for diffusion models. By aligning this semantically meaningful human face latent space with text-to-image diffusion models, we succeed in maintaining high fidelity in identity preservation, coupled with the capacity for semantic editing. Additionally, we propose new training objectives to balance the influences of both prompt and identity conditions, ensuring that the identity-irrelevant background remains unaffected during facial attribute modifications. Extensive experiments reveal that our method adeptly generates personalized text-to-image outputs that are not only compatible with prompt descriptions but also amenable to common StyleGAN editing directions in diverse settings. Our source code will be available at \url{https://github.com/csxmli2016/w-plus-adapter}.
Dense Point Prediction: A Simple Baseline for Crowd Counting and Localization
Apr 26, 2021

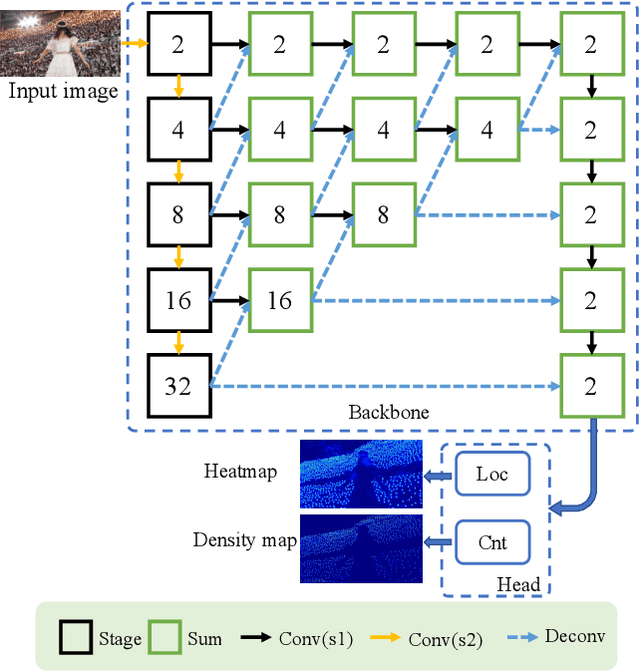
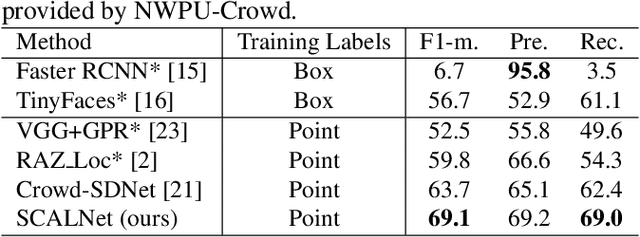
In this paper, we propose a simple yet effective crowd counting and localization network named SCALNet. Unlike most existing works that separate the counting and localization tasks, we consider those tasks as a pixel-wise dense prediction problem and integrate them into an end-to-end framework. Specifically, for crowd counting, we adopt a counting head supervised by the Mean Square Error (MSE) loss. For crowd localization, the key insight is to recognize the keypoint of people, i.e., the center point of heads. We propose a localization head to distinguish dense crowds trained by two loss functions, i.e., Negative-Suppressed Focal (NSF) loss and False-Positive (FP) loss, which balances the positive/negative examples and handles the false-positive predictions. Experiments on the recent and large-scale benchmark, NWPU-Crowd, show that our approach outperforms the state-of-the-art methods by more than 5% and 10% improvement in crowd localization and counting tasks, respectively. The code is publicly available at https://github.com/WangyiNTU/SCALNet.
A Self-Training Approach for Point-Supervised Object Detection and Counting in Crowds
Jul 25, 2020
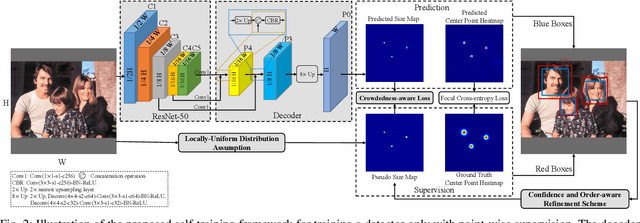


In this paper, we propose a novel self-training approach which enables a typical object detector trained only with point-level annotations (i.e., objects are labeled with points) to estimate both the center points and sizes of crowded objects. Specifically, during training we utilize the available point annotations to directly supervise the estimation of the center points of objects. Based on a locally-uniform distribution assumption, we initialize pseudo object sizes from the point-level supervisory information, which are then leveraged to guide the regression of object sizes via a crowdedness-aware loss. Meanwhile, we propose a confidence and order-aware refinement scheme to continuously refine the initial pseudo object sizes such that the ability of the detector is increasingly boosted to simultaneously detect and count objects in crowds. Moreover, to address extremely crowded scenes, we propose an effective decoding method to improve the representation ability of the detector. Experimental results on the WiderFace benchmark show that our approach significantly outperforms state-of-the-art point-supervised methods under both detection and counting tasks, i.e., our method improves the average precision by more than 10% and reduces the counting error by 31.2%. In addition, our method obtains the best results on the dense crowd counting dataset (i.e., ShanghaiTech) and vehicle counting datasets (i.e., CARPK and PUCPR+) when compared with state-of-the-art counting-by-detection methods. We will make the code publicly available to facilitate future research.