 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Training Approach for Point-Supervised Object Detection and Counting in Crowds
Paper and Code

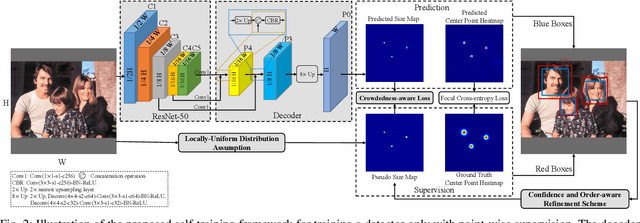


In this paper, we propose a novel self-training approach which enables a typical object detector trained only with point-level annotations (i.e., objects are labeled with points) to estimate both the center points and sizes of crowded objects. Specifically, during training we utilize the available point annotations to directly supervise the estimation of the center points of objects. Based on a locally-uniform distribution assumption, we initialize pseudo object sizes from the point-level supervisory information, which are then leveraged to guide the regression of object sizes via a crowdedness-aware loss. Meanwhile, we propose a confidence and order-aware refinement scheme to continuously refine the initial pseudo object sizes such that the ability of the detector is increasingly boosted to simultaneously detect and count objects in crowds. Moreover, to address extremely crowded scenes, we propose an effective decoding method to improve the representation ability of the detector. Experimental results on the WiderFace benchmark show that our approach significantly outperforms state-of-the-art point-supervised methods under both detection and counting tasks, i.e., our method improves the average precision by more than 10% and reduces the counting error by 31.2%. In addition, our method obtains the best results on the dense crowd counting dataset (i.e., ShanghaiTech) and vehicle counting datasets (i.e., CARPK and PUCPR+) when compared with state-of-the-art counting-by-detection methods. We will make the code publicly available to facilitate future research.