 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Trajectories: Unlocking the Intrinsic Generative Optimality of Diffusion Models via Graph-Theoretic Planning
Mar 16, 2026Diffusion models operate in a reflexive System 1 mode, constrained by a fixed, content-agnostic sampling schedule. This rigidity arises from the curse of state dimensionality, where the combinatorial explosion of possible states in the high-dimensional noise manifold renders explicit trajectory planning intractable and leads to systematic computational misallocation. To address this, we introduce Chain-of-Trajectories (CoTj), a train-free framework enabling System 2 deliberative planning. Central to CoTj is Diffusion DNA, a low-dimensional signature that quantifies per-stage denoising difficulty and serves as a proxy for the high-dimensional state space, allowing us to reformulate sampling as graph planning on a directed acyclic graph. Through a Predict-Plan-Execute paradigm, CoTj dynamically allocates computational effort to the most challenging generative phases. Experiments across multiple generative models demonstrate that CoTj discovers context-aware trajectories, improving output quality and stability while reducing redundant computation. This work establishes a new foundation for resource-aware, planning-based diffusion modeling. The code is available at https://github.com/UnicomAI/CoTj.
From Prompt Optimization to Multi-Dimensional Credibility Evaluation: Enhancing Trustworthiness of Chinese LLM-Generated Liver MRI Reports
Oct 27, 2025Large language models (LLMs) have demonstrated promising performance in generating diagnostic conclusions from imaging findings, thereby supporting radiology reporting, trainee education, and quality control. However, systematic guidance on how to optimize prompt design across different clinical contexts remains underexplored. Moreover, a comprehensive and standardized framework for assessing the trustworthiness of LLM-generated radiology reports is yet to be established. This study aims to enhance the trustworthiness of LLM-generated liver MRI reports by introducing a Multi-Dimensional Credibility Assessment (MDCA) framework and providing guidance on institution-specific prompt optimization. The proposed framework is applied to evaluate and compare the performance of several advanced LLMs, including Kimi-K2-Instruct-0905, Qwen3-235B-A22B-Instruct-2507, DeepSeek-V3, and ByteDance-Seed-OSS-36B-Instruct, using the SiliconFlow platform.
Fuzzy Reasoning Chain (FRC): An Innovative Reasoning Framework from Fuzziness to Clarity
Sep 26, 2025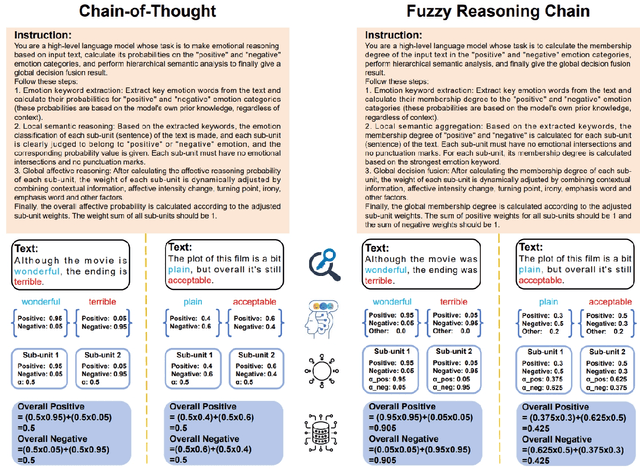
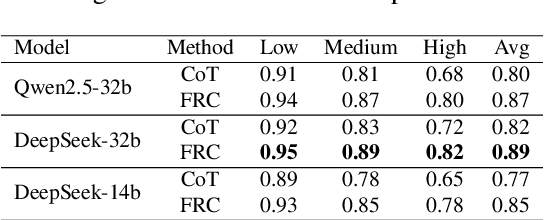
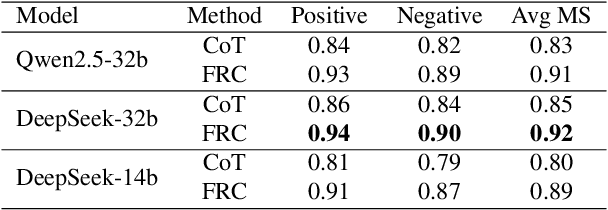
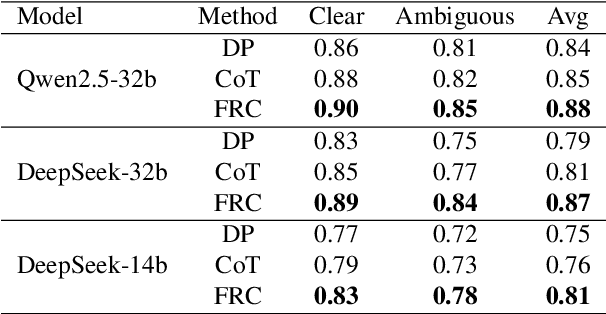
With the rapid advancement of large language models (LLMs), natural language processing (NLP) has achieved remarkable progress. Nonetheless, significant challenges remain in handling texts with ambiguity, polysemy, or uncertainty. We introduce the Fuzzy Reasoning Chain (FRC) framework, which integrates LLM semantic priors with continuous fuzzy membership degrees, creating an explicit interaction between probability-based reasoning and fuzzy membership reasoning. This transition allows ambiguous inputs to be gradually transformed into clear and interpretable decisions while capturing conflicting or uncertain signals that traditional probability-based methods cannot. We validate FRC on sentiment analysis tasks, where both theoretical analysis and empirical results show that it ensures stable reasoning and facilitates knowledge transfer across different model scales. These findings indicate that FRC provides a general mechanism for managing subtle and ambiguous expressions with improved interpretability and robustness.
Optimizing for the Shortest Path in Denoising Diffusion Model
Mar 06, 2025In this research, we propose a novel denoising diffusion model based on shortest-path modeling that optimizes residual propagation to enhance both denoising efficiency and quality. Drawing on Denoising Diffusion Implicit Models (DDIM) and insights from graph theory, our model, termed the Shortest Path Diffusion Model (ShortDF), treats the denoising process as a shortest-path problem aimed at minimizing reconstruction error. By optimizing the initial residuals, we improve the efficiency of the reverse diffusion process and the quality of the generated samples. Extensive experiments on multiple standard benchmarks demonstrate that ShortDF significantly reduces diffusion time (or steps) while enhancing the visual fidelity of generated samples compared to prior arts. This work, we suppose, paves the way for interactive diffusion-based applications and establishes a foundation for rapid data generation. Code is available at https://github.com/UnicomAI/ShortDF
Learning Triangular Distribution in Visual World
Dec 04, 2023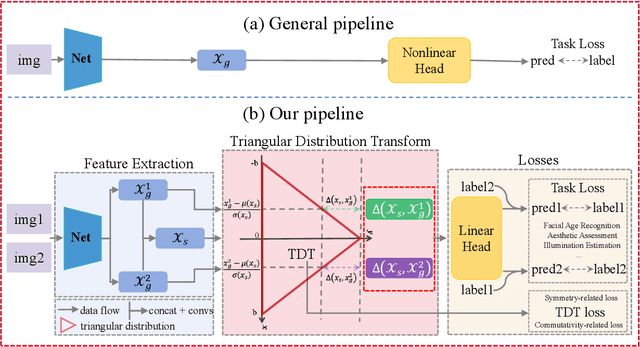

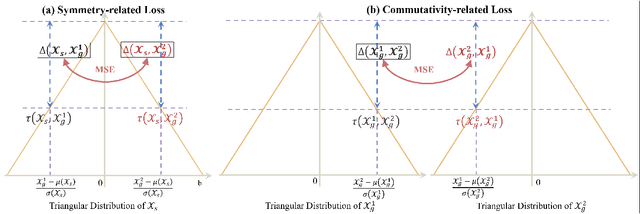
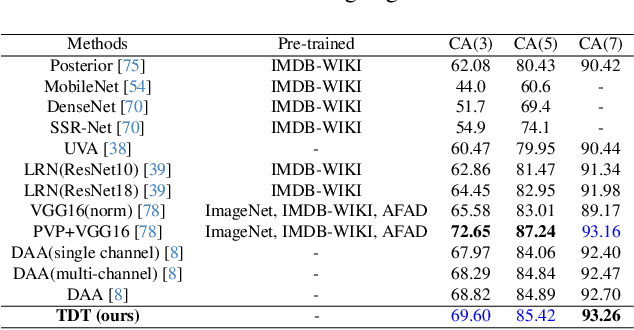
Convolution neural network is successful in pervasive vision tasks, including label distribution learning, which usually takes the form of learning an injection from the non-linear visual features to the well-defined labels. However, how the discrepancy between features is mapped to the label discrepancy is ambient, and its correctness is not guaranteed. To address these problems, we study the mathematical connection between feature and its label, presenting a general and simple framework for label distribution learning. We propose a so-called Triangular Distribution Transform (TDT) to build an injective function between feature and label, guaranteeing that any symmetric feature discrepancy linearly reflects the difference between labels. The proposed TDT can be used as a plug-in in mainstream backbone networks to address different label distribution learning tasks. Experiments on Facial Age Recognition, Illumination Chromaticity Estimation, and Aesthetics assessment show that TDT achieves on-par or better results than the prior arts.
DAA: A Delta Age AdaIN operation for age estimation via binary code transformer
Mar 14, 2023
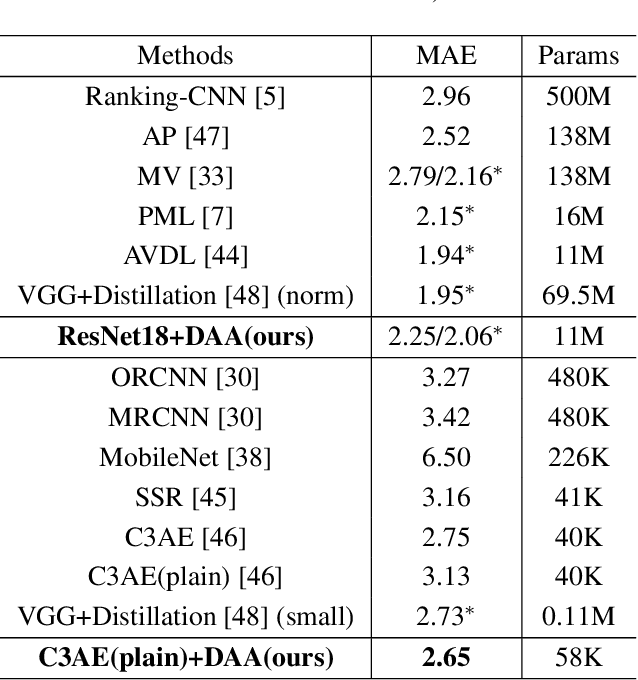


Naked eye recognition of age is usually based on comparison with the age of others. However, this idea is ignored by computer tasks because it is difficult to obtain representative contrast images of each age. Inspired by the transfer learning, we designed the Delta Age AdaIN (DAA) operation to obtain the feature difference with each age, which obtains the style map of each age through the learned values representing the mean and standard deviation. We let the input of transfer learning as the binary code of age natural number to obtain continuous age feature information. The learned two groups of values in Binary code mapping are corresponding to the mean and standard deviation of the comparison ages. In summary, our method consists of four parts: FaceEncoder, DAA operation, Binary code mapping, and AgeDecoder modules. After getting the delta age via AgeDecoder, we take the average value of all comparison ages and delta ages as the predicted age. Compared with state-of-the-art methods, our method achieves better performance with fewer parameters on multiple facial age datasets.