 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVM-SLAM: Semantic Visual SLAM with Multi-Sensor Fusion in a Bird's Eye View for Automated Valet Parking
Sep 15, 2023Automated Valet Parking (AVP) requires precise localization in challenging garage conditions, including poor lighting, sparse textures, repetitive structures, dynamic scenes, and the absence of Global Positioning System (GPS) signals, which often pose problems for conventional localization methods. To address these adversities, we present AVM-SLAM, a semantic visual SLAM framework with multi-sensor fusion in a Bird's Eye View (BEV). Our framework integrates four fisheye cameras, four wheel encoders, and an Inertial Measurement Unit (IMU). The fisheye cameras form an Around View Monitor (AVM) subsystem, generating BEV images. Convolutional Neural Networks (CNNs) extract semantic features from these images, aiding in mapping and localization tasks. These semantic features provide long-term stability and perspective invariance, effectively mitigating environmental challenges. Additionally, data fusion from wheel encoders and IMU enhances system robustness by improving motion estimation and reducing drift. To validate AVM-SLAM's efficacy and robustness, we provide a large-scale, high-resolution underground garage dataset, available at https://github.com/yale-cv/avm-slam. This dataset enables researchers to further explore and assess AVM-SLAM in similar environments.
DAA: A Delta Age AdaIN operation for age estimation via binary code transformer
Mar 14, 2023
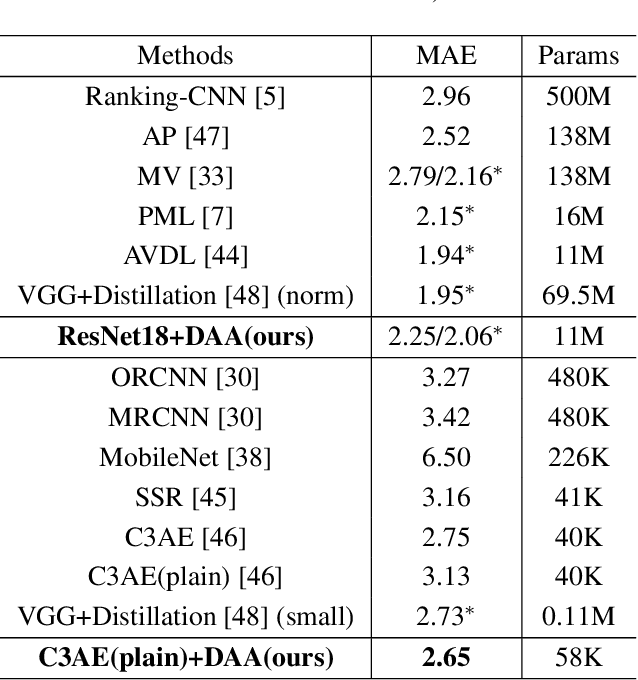


Naked eye recognition of age is usually based on comparison with the age of others. However, this idea is ignored by computer tasks because it is difficult to obtain representative contrast images of each age. Inspired by the transfer learning, we designed the Delta Age AdaIN (DAA) operation to obtain the feature difference with each age, which obtains the style map of each age through the learned values representing the mean and standard deviation. We let the input of transfer learning as the binary code of age natural number to obtain continuous age feature information. The learned two groups of values in Binary code mapping are corresponding to the mean and standard deviation of the comparison ages. In summary, our method consists of four parts: FaceEncoder, DAA operation, Binary code mapping, and AgeDecoder modules. After getting the delta age via AgeDecoder, we take the average value of all comparison ages and delta ages as the predicted age. Compared with state-of-the-art methods, our method achieves better performance with fewer parameters on multiple facial age datasets.