 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Trajectories: Unlocking the Intrinsic Generative Optimality of Diffusion Models via Graph-Theoretic Planning
Mar 16, 2026Diffusion models operate in a reflexive System 1 mode, constrained by a fixed, content-agnostic sampling schedule. This rigidity arises from the curse of state dimensionality, where the combinatorial explosion of possible states in the high-dimensional noise manifold renders explicit trajectory planning intractable and leads to systematic computational misallocation. To address this, we introduce Chain-of-Trajectories (CoTj), a train-free framework enabling System 2 deliberative planning. Central to CoTj is Diffusion DNA, a low-dimensional signature that quantifies per-stage denoising difficulty and serves as a proxy for the high-dimensional state space, allowing us to reformulate sampling as graph planning on a directed acyclic graph. Through a Predict-Plan-Execute paradigm, CoTj dynamically allocates computational effort to the most challenging generative phases. Experiments across multiple generative models demonstrate that CoTj discovers context-aware trajectories, improving output quality and stability while reducing redundant computation. This work establishes a new foundation for resource-aware, planning-based diffusion modeling. The code is available at https://github.com/UnicomAI/CoTj.
Fuzzy Reasoning Chain (FRC): An Innovative Reasoning Framework from Fuzziness to Clarity
Sep 26, 2025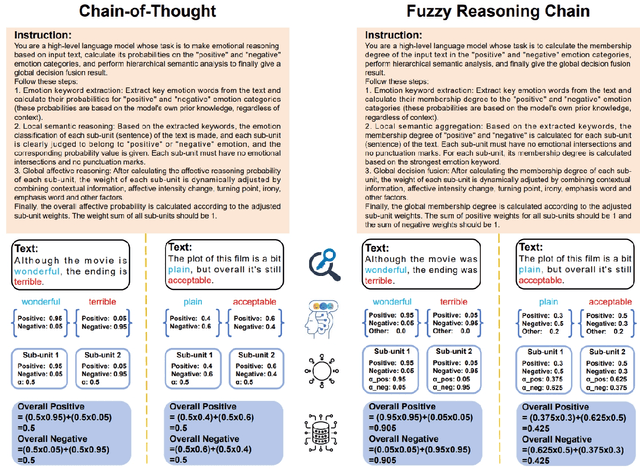
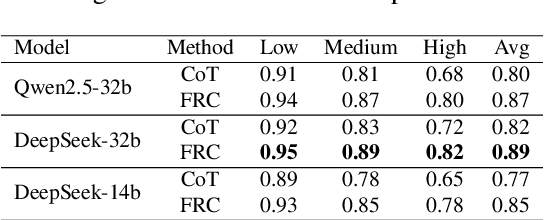
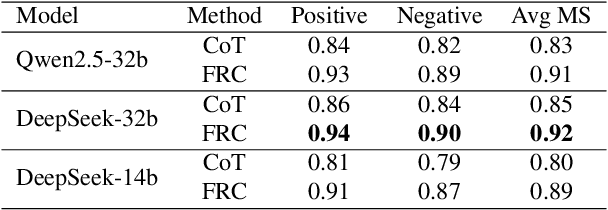
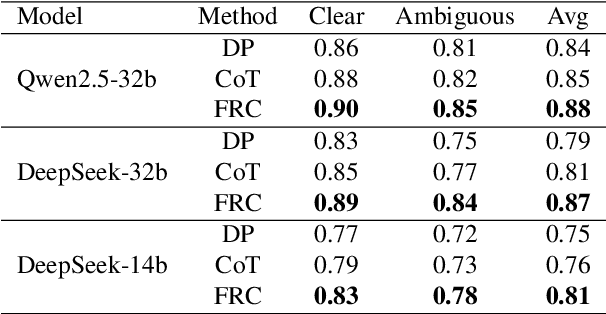
With the rapid advancement of large language models (LLMs), natural language processing (NLP) has achieved remarkable progress. Nonetheless, significant challenges remain in handling texts with ambiguity, polysemy, or uncertainty. We introduce the Fuzzy Reasoning Chain (FRC) framework, which integrates LLM semantic priors with continuous fuzzy membership degrees, creating an explicit interaction between probability-based reasoning and fuzzy membership reasoning. This transition allows ambiguous inputs to be gradually transformed into clear and interpretable decisions while capturing conflicting or uncertain signals that traditional probability-based methods cannot. We validate FRC on sentiment analysis tasks, where both theoretical analysis and empirical results show that it ensures stable reasoning and facilitates knowledge transfer across different model scales. These findings indicate that FRC provides a general mechanism for managing subtle and ambiguous expressions with improved interpretability and robustness.
Hierarchical Deep Fusion Framework for Multi-dimensional Facial Forgery Detection -- The 2024 Global Deepfake Image Detection Challenge
Sep 16, 2025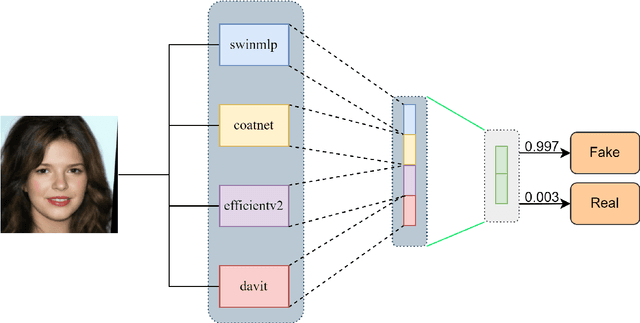

The proliferation of sophisticated deepfake technology poses significant challenges to digital security and authenticity. Detecting these forgeries, especially across a wide spectrum of manipulation techniques, requires robust and generalized models. This paper introduces the Hierarchical Deep Fusion Framework (HDFF), an ensemble-based deep learning architecture designed for high-performance facial forgery detection. Our framework integrates four diverse pre-trained sub-models, Swin-MLP, CoAtNet, EfficientNetV2, and DaViT, which are meticulously fine-tuned through a multi-stage process on the MultiFFDI dataset. By concatenating the feature representations from these specialized models and training a final classifier layer, HDFF effectively leverages their collective strengths. This approach achieved a final score of 0.96852 on the competition's private leaderboard, securing the 20th position out of 184 teams, demonstrating the efficacy of hierarchical fusion for complex image classification tasks.
SLearnLLM: A Self-Learning Framework for Efficient Domain-Specific Adaptation of Large Language Models
May 23, 2025



When using supervised fine-tuning (SFT) to adapt large language models (LLMs) to specific domains, a significant challenge arises: should we use the entire SFT dataset for fine-tuning? Common practice often involves fine-tuning directly on the entire dataset due to limited information on the LLM's past training data. However, if the SFT dataset largely overlaps with the model's existing knowledge, the performance gains are minimal, leading to wasted computational resources. Identifying the unknown knowledge within the SFT dataset and using it to fine-tune the model could substantially improve the training efficiency. To address this challenge, we propose a self-learning framework for LLMs inspired by human learning pattern. This framework takes a fine-tuning (SFT) dataset in a specific domain as input. First, the LLMs answer the questions in the SFT dataset. The LLMs then objectively grade the responses and filter out the incorrectly answered QA pairs. Finally, we fine-tune the LLMs based on this filtered QA set. Experimental results in the fields of agriculture and medicine demonstrate that our method substantially reduces training time while achieving comparable improvements to those attained with full dataset fine-tuning. By concentrating on the unknown knowledge within the SFT dataset, our approach enhances the efficiency of fine-tuning LLMs.
A Multimodal Benchmark Dataset and Model for Crop Disease Diagnosis
Mar 10, 2025While conversational generative AI has shown considerable potential in enhancing decision-making for agricultural professionals, its exploration has predominantly been anchored in text-based interactions. The evolution of multimodal conversational AI, leveraging vast amounts of image-text data from diverse sources, marks a significant stride forward. However, the application of such advanced vision-language models in the agricultural domain, particularly for crop disease diagnosis, remains underexplored. In this work, we present the crop disease domain multimodal (CDDM) dataset, a pioneering resource designed to advance the field of agricultural research through the application of multimodal learning techniques. The dataset comprises 137,000 images of various crop diseases, accompanied by 1 million question-answer pairs that span a broad spectrum of agricultural knowledge, from disease identification to management practices. By integrating visual and textual data, CDDM facilitates the development of sophisticated question-answering systems capable of providing precise, useful advice to farmers and agricultural professionals. We demonstrate the utility of the dataset by finetuning state-of-the-art multimodal models, showcasing significant improvements in crop disease diagnosis. Specifically, we employed a novel finetuning strategy that utilizes low-rank adaptation (LoRA) to finetune the visual encoder, adapter and language model simultaneously. Our contributions include not only the dataset but also a finetuning strategy and a benchmark to stimulate further research in agricultural technology, aiming to bridge the gap between advanced AI techniques and practical agricultural applications. The dataset is available at https: //github.com/UnicomAI/UnicomBenchmark/tree/main/CDDMBench.
Optimizing for the Shortest Path in Denoising Diffusion Model
Mar 06, 2025In this research, we propose a novel denoising diffusion model based on shortest-path modeling that optimizes residual propagation to enhance both denoising efficiency and quality. Drawing on Denoising Diffusion Implicit Models (DDIM) and insights from graph theory, our model, termed the Shortest Path Diffusion Model (ShortDF), treats the denoising process as a shortest-path problem aimed at minimizing reconstruction error. By optimizing the initial residuals, we improve the efficiency of the reverse diffusion process and the quality of the generated samples. Extensive experiments on multiple standard benchmarks demonstrate that ShortDF significantly reduces diffusion time (or steps) while enhancing the visual fidelity of generated samples compared to prior arts. This work, we suppose, paves the way for interactive diffusion-based applications and establishes a foundation for rapid data generation. Code is available at https://github.com/UnicomAI/ShortDF
Training Interactive Agent in Large FPS Game Map with Rule-enhanced Reinforcement Learning
Oct 07, 2024In the realm of competitive gaming, 3D first-person shooter (FPS) games have gained immense popularity, prompting the development of game AI systems to enhance gameplay. However, deploying game AI in practical scenarios still poses challenges, particularly in large-scale and complex FPS games. In this paper, we focus on the practical deployment of game AI in the online multiplayer competitive 3D FPS game called Arena Breakout, developed by Tencent Games. We propose a novel gaming AI system named Private Military Company Agent (PMCA), which is interactable within a large game map and engages in combat with players while utilizing tactical advantages provided by the surrounding terrain. To address the challenges of navigation and combat in modern 3D FPS games, we introduce a method that combines navigation mesh (Navmesh) and shooting-rule with deep reinforcement learning (NSRL). The integration of Navmesh enhances the agent's global navigation capabilities while shooting behavior is controlled using rule-based methods to ensure controllability. NSRL employs a DRL model to predict when to enable the navigation mesh, resulting in a diverse range of behaviors for the game AI. Customized rewards for human-like behaviors are also employed to align PMCA's behavior with that of human players.
Data-Centric AI Paradigm Based on Application-Driven Fine-grained Dataset Design
Sep 23, 2022
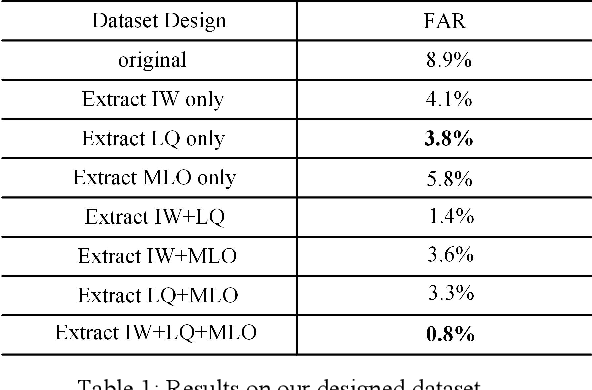


Deep learning has a wide range of applications in industrial scenario, but reducing false alarm (FA) remains a major difficulty. Optimizing network architecture or network parameters is used to tackle this challenge in academic circles, while ignoring the essential characteristics of data in application scenarios, which often results in increased FA in new scenarios. In this paper, we propose a novel paradigm for fine-grained design of datasets, driven by industrial applications. We flexibly select positive and negative sample sets according to the essential features of the data and application requirements, and add the remaining samples to the training set as uncertainty classes. We collect more than 10,000 mask-wearing recognition samples covering various application scenarios as our experimental data. Compared with the traditional data design methods, our method achieves better results and effectively reduces FA. We make all contributions available to the research community for broader use. The contributions will be available at https://github.com/huh30/OpenDatasets.
Video synthesis of human upper body with realistic face
Sep 12, 2019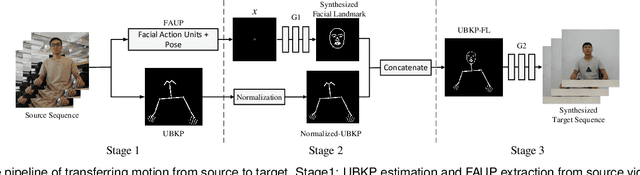
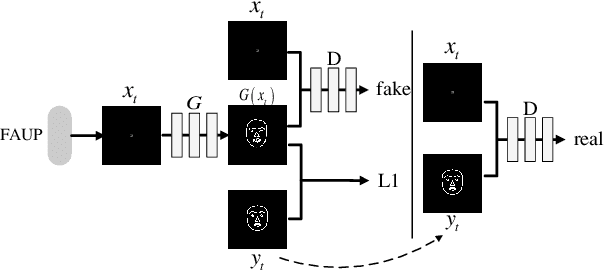
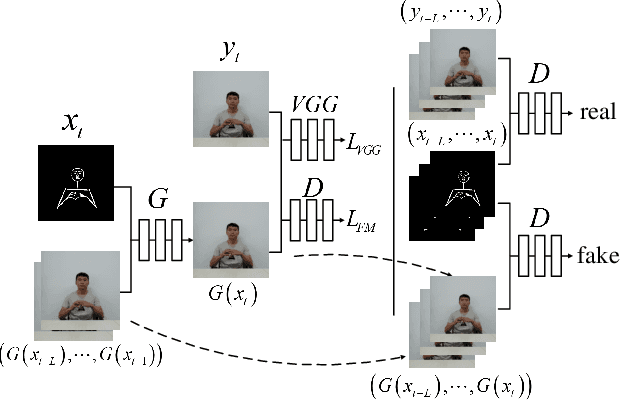

This paper presents a generative adversarial learning-based human upper body video synthesis approach to generate an upper body video of target person that is consistent with the body motion, face expression, and pose of the person in source video. We use upper body keypoints, facial action units and poses as intermediate representations between source video and target video. Instead of directly transferring the source video to the target video, we firstly map the source person's facial action units and poses into the target person's facial landmarks, then combine the normalized upper body keypoints and generated facial landmarks with spatio-temporal smoothing to generate the corresponding target video's image. Experimental results demonstrated the effectiveness of our method.
A Neural Virtual Anchor Synthesizer based on Seq2Seq and GAN Models
Sep 12, 2019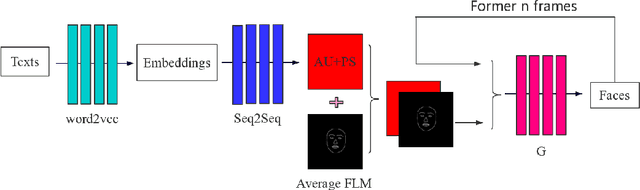
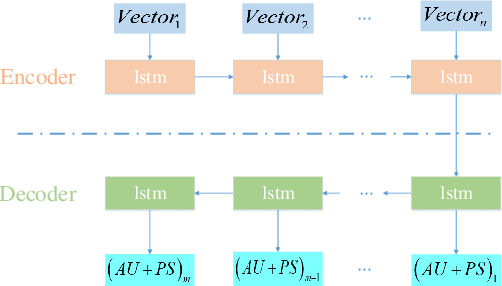
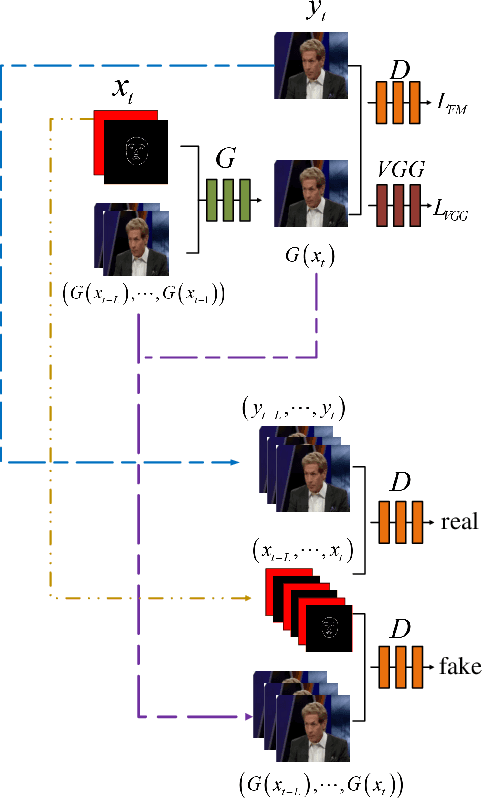

This paper presents a novel framework to generate realistic face video of an anchor, who is reading certain news. This task is also known as Virtual Anchor. Given some paragraphs of words, we first utilize a pretrained Word2Vec model to embed each word into a vector; then we utilize a Seq2Seq-based model to translate these word embeddings into action units and head poses of the target anchor; these action units and head poses will be concatenated with facial landmarks as well as the former $n$ synthesized frames, and the concatenation serves as input of a Pix2PixHD-based model to synthesize realistic facial images for the virtual anchor. The experimental results demonstrate our framework is feasible for the synthesis of virtual anchor.