Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Virtual Anchor Synthesizer based on Seq2Seq and GAN Models
Paper and Code
Sep 12, 2019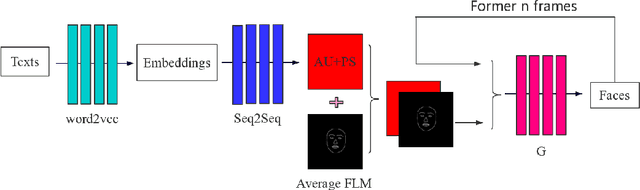
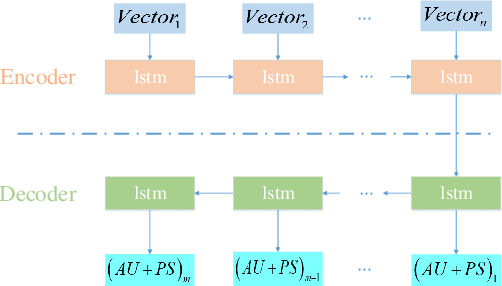
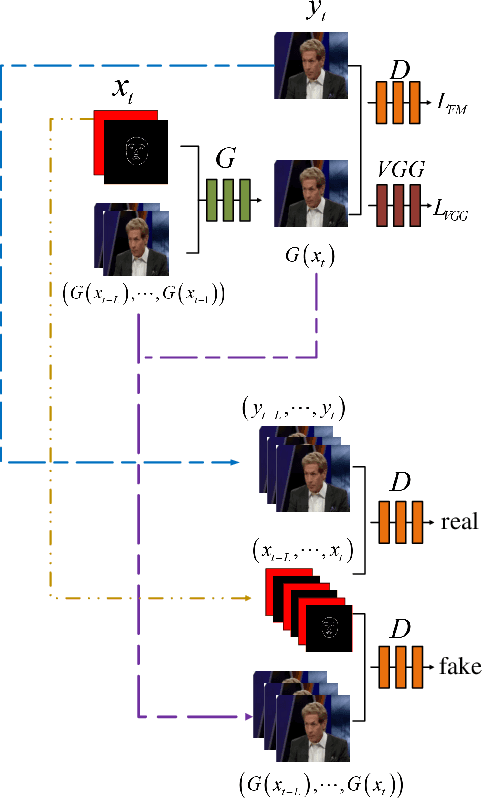

This paper presents a novel framework to generate realistic face video of an anchor, who is reading certain news. This task is also known as Virtual Anchor. Given some paragraphs of words, we first utilize a pretrained Word2Vec model to embed each word into a vector; then we utilize a Seq2Seq-based model to translate these word embeddings into action units and head poses of the target anchor; these action units and head poses will be concatenated with facial landmarks as well as the former $n$ synthesized frames, and the concatenation serves as input of a Pix2PixHD-based model to synthesize realistic facial images for the virtual anchor. The experimental results demonstrate our framework is feasible for the synthesis of virtual anchor.
* Accepted to ISMAR 2019
View paper on