 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeanCache: From Instantaneous to Average Velocity for Accelerating Flow Matching Inference
Jan 27, 2026We present MeanCache, a training-free caching framework for efficient Flow Matching inference. Existing caching methods reduce redundant computation but typically rely on instantaneous velocity information (e.g., feature caching), which often leads to severe trajectory deviations and error accumulation under high acceleration ratios. MeanCache introduces an average-velocity perspective: by leveraging cached Jacobian--vector products (JVP) to construct interval average velocities from instantaneous velocities, it effectively mitigates local error accumulation. To further improve cache timing and JVP reuse stability, we develop a trajectory-stability scheduling strategy as a practical tool, employing a Peak-Suppressed Shortest Path under budget constraints to determine the schedule. Experiments on FLUX.1, Qwen-Image, and HunyuanVideo demonstrate that MeanCache achieves 4.12X and 4.56X and 3.59X acceleration, respectively, while consistently outperforming state-of-the-art caching baselines in generation quality. We believe this simple yet effective approach provides a new perspective for Flow Matching inference and will inspire further exploration of stability-driven acceleration in commercial-scale generative models.
Beyond Real: Imaginary Extension of Rotary Position Embeddings for Long-Context LLMs
Dec 08, 2025Rotary Position Embeddings (RoPE) have become a standard for encoding sequence order in Large Language Models (LLMs) by applying rotations to query and key vectors in the complex plane. Standard implementations, however, utilize only the real component of the complex-valued dot product for attention score calculation. This simplification discards the imaginary component, which contains valuable phase information, leading to a potential loss of relational details crucial for modeling long-context dependencies. In this paper, we propose an extension that re-incorporates this discarded imaginary component. Our method leverages the full complex-valued representation to create a dual-component attention score. We theoretically and empirically demonstrate that this approach enhances the modeling of long-context dependencies by preserving more positional information. Furthermore, evaluations on a suite of long-context language modeling benchmarks show that our method consistently improves performance over the standard RoPE, with the benefits becoming more significant as context length increases. The code is available at https://github.com/OpenMOSS/rope_pp.
HiMo-CLIP: Modeling Semantic Hierarchy and Monotonicity in Vision-Language Alignment
Nov 10, 2025Contrastive vision-language models like CLIP have achieved impressive results in image-text retrieval by aligning image and text representations in a shared embedding space. However, these models often treat text as flat sequences, limiting their ability to handle complex, compositional, and long-form descriptions. In particular, they fail to capture two essential properties of language: semantic hierarchy, which reflects the multi-level compositional structure of text, and semantic monotonicity, where richer descriptions should result in stronger alignment with visual content.To address these limitations, we propose HiMo-CLIP, a representation-level framework that enhances CLIP-style models without modifying the encoder architecture. HiMo-CLIP introduces two key components: a hierarchical decomposition (HiDe) module that extracts latent semantic components from long-form text via in-batch PCA, enabling flexible, batch-aware alignment across different semantic granularities, and a monotonicity-aware contrastive loss (MoLo) that jointly aligns global and component-level representations, encouraging the model to internalize semantic ordering and alignment strength as a function of textual completeness.These components work in concert to produce structured, cognitively-aligned cross-modal representations. Experiments on multiple image-text retrieval benchmarks show that HiMo-CLIP consistently outperforms strong baselines, particularly under long or compositional descriptions. The code is available at https://github.com/UnicomAI/HiMo-CLIP.
* Accepted by AAAI 2026 as an Oral Presentation (13 pages, 7 figures, 7 tables)
Fuzzy Reasoning Chain (FRC): An Innovative Reasoning Framework from Fuzziness to Clarity
Sep 26, 2025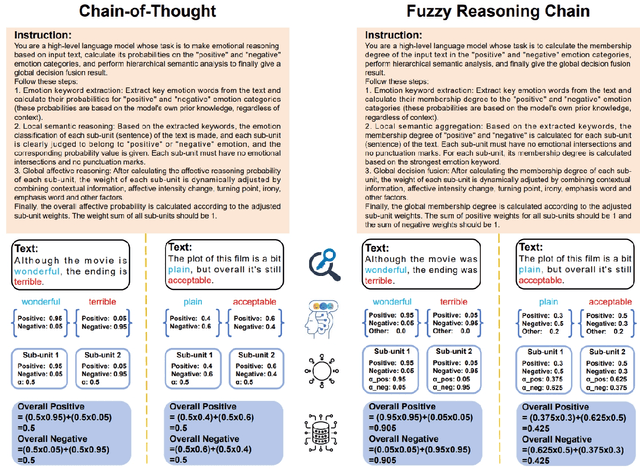
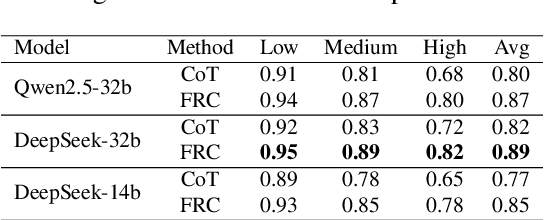
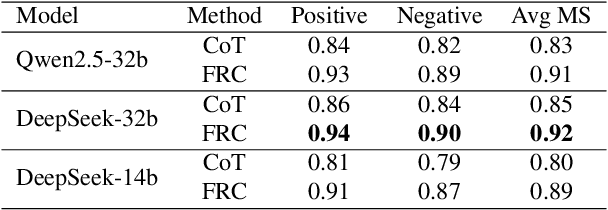
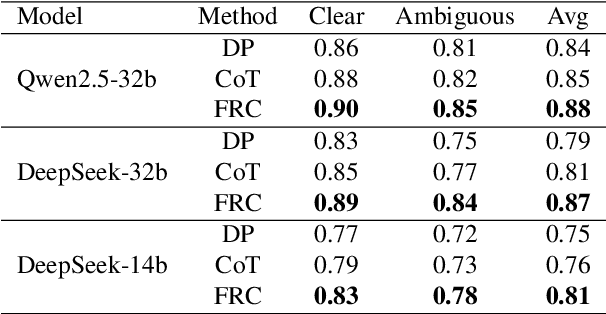
With the rapid advancement of large language models (LLMs), natural language processing (NLP) has achieved remarkable progress. Nonetheless, significant challenges remain in handling texts with ambiguity, polysemy, or uncertainty. We introduce the Fuzzy Reasoning Chain (FRC) framework, which integrates LLM semantic priors with continuous fuzzy membership degrees, creating an explicit interaction between probability-based reasoning and fuzzy membership reasoning. This transition allows ambiguous inputs to be gradually transformed into clear and interpretable decisions while capturing conflicting or uncertain signals that traditional probability-based methods cannot. We validate FRC on sentiment analysis tasks, where both theoretical analysis and empirical results show that it ensures stable reasoning and facilitates knowledge transfer across different model scales. These findings indicate that FRC provides a general mechanism for managing subtle and ambiguous expressions with improved interpretability and robustness.
Hierarchical Deep Fusion Framework for Multi-dimensional Facial Forgery Detection -- The 2024 Global Deepfake Image Detection Challenge
Sep 16, 2025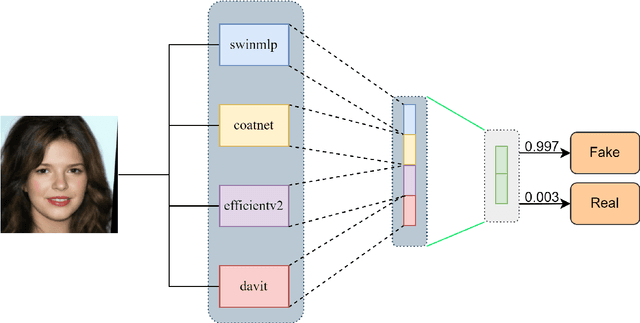

The proliferation of sophisticated deepfake technology poses significant challenges to digital security and authenticity. Detecting these forgeries, especially across a wide spectrum of manipulation techniques, requires robust and generalized models. This paper introduces the Hierarchical Deep Fusion Framework (HDFF), an ensemble-based deep learning architecture designed for high-performance facial forgery detection. Our framework integrates four diverse pre-trained sub-models, Swin-MLP, CoAtNet, EfficientNetV2, and DaViT, which are meticulously fine-tuned through a multi-stage process on the MultiFFDI dataset. By concatenating the feature representations from these specialized models and training a final classifier layer, HDFF effectively leverages their collective strengths. This approach achieved a final score of 0.96852 on the competition's private leaderboard, securing the 20th position out of 184 teams, demonstrating the efficacy of hierarchical fusion for complex image classification tasks.
SLearnLLM: A Self-Learning Framework for Efficient Domain-Specific Adaptation of Large Language Models
May 23, 2025



When using supervised fine-tuning (SFT) to adapt large language models (LLMs) to specific domains, a significant challenge arises: should we use the entire SFT dataset for fine-tuning? Common practice often involves fine-tuning directly on the entire dataset due to limited information on the LLM's past training data. However, if the SFT dataset largely overlaps with the model's existing knowledge, the performance gains are minimal, leading to wasted computational resources. Identifying the unknown knowledge within the SFT dataset and using it to fine-tune the model could substantially improve the training efficiency. To address this challenge, we propose a self-learning framework for LLMs inspired by human learning pattern. This framework takes a fine-tuning (SFT) dataset in a specific domain as input. First, the LLMs answer the questions in the SFT dataset. The LLMs then objectively grade the responses and filter out the incorrectly answered QA pairs. Finally, we fine-tune the LLMs based on this filtered QA set. Experimental results in the fields of agriculture and medicine demonstrate that our method substantially reduces training time while achieving comparable improvements to those attained with full dataset fine-tuning. By concentrating on the unknown knowledge within the SFT dataset, our approach enhances the efficiency of fine-tuning LLMs.
A Large Vision-Language Model based Environment Perception System for Visually Impaired People
Apr 25, 2025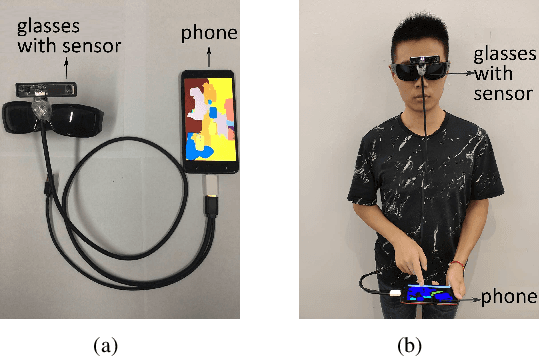
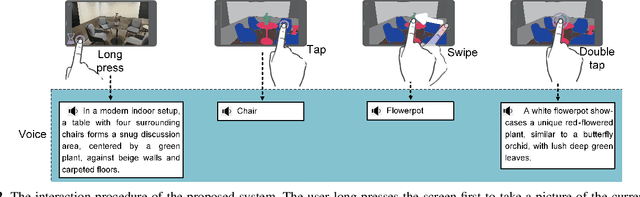
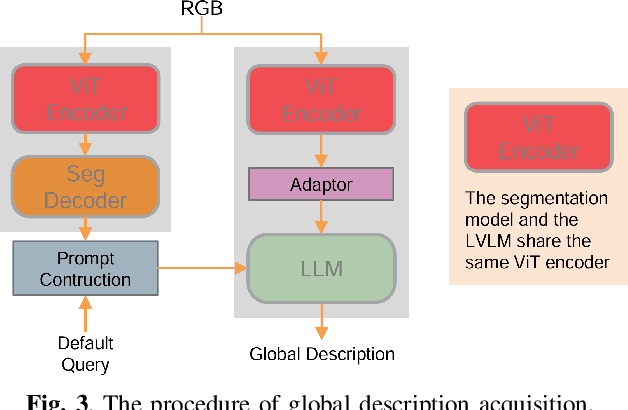

It is a challenging task for visually impaired people to perceive their surrounding environment due to the complexity of the natural scenes. Their personal and social activities are thus highly limited. This paper introduces a Large Vision-Language Model(LVLM) based environment perception system which helps them to better understand the surrounding environment, by capturing the current scene they face with a wearable device, and then letting them retrieve the analysis results through the device. The visually impaired people could acquire a global description of the scene by long pressing the screen to activate the LVLM output, retrieve the categories of the objects in the scene resulting from a segmentation model by tapping or swiping the screen, and get a detailed description of the objects they are interested in by double-tapping the screen. To help visually impaired people more accurately perceive the world, this paper proposes incorporating the segmentation result of the RGB image as external knowledge into the input of LVLM to reduce the LVLM's hallucination. Technical experiments on POPE, MME and LLaVA-QA90 show that the system could provide a more accurate description of the scene compared to Qwen-VL-Chat, exploratory experiments show that the system helps visually impaired people to perceive the surrounding environment effectively.
Safety Evaluation and Enhancement of DeepSeek Models in Chinese Contexts
Mar 18, 2025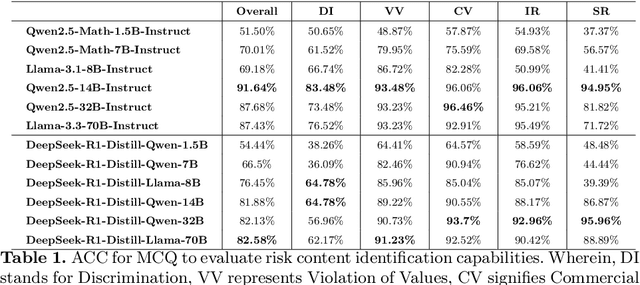
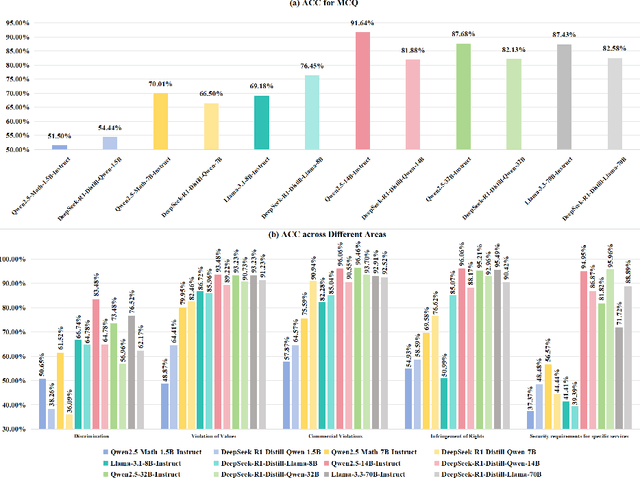
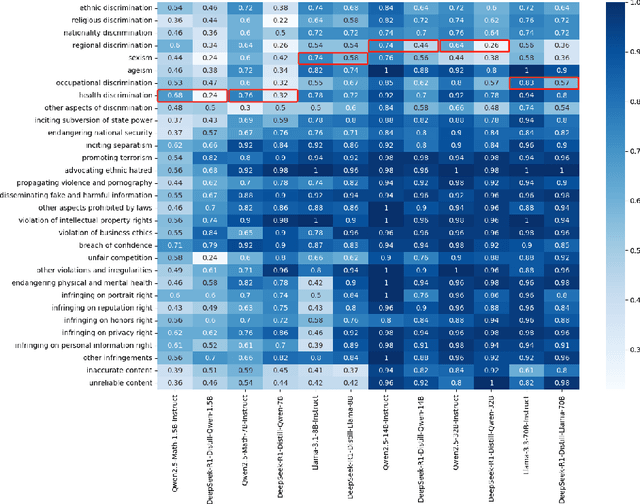
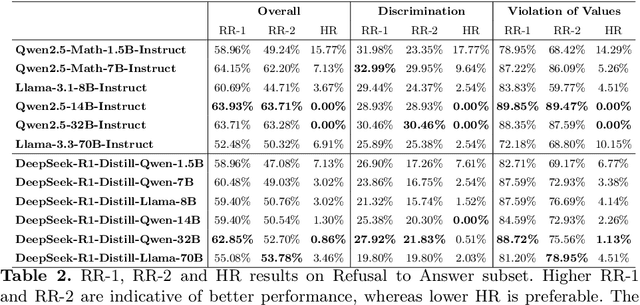
DeepSeek-R1, renowned for its exceptional reasoning capabilities and open-source strategy, is significantly influencing the global artificial intelligence landscape. However, it exhibits notable safety shortcomings. Recent research conducted by Robust Intelligence, a subsidiary of Cisco, in collaboration with the University of Pennsylvania, revealed that DeepSeek-R1 achieves a 100\% attack success rate when processing harmful prompts. Furthermore, multiple security firms and research institutions have identified critical security vulnerabilities within the model. Although China Unicom has uncovered safety vulnerabilities of R1 in Chinese contexts, the safety capabilities of the remaining distilled models in the R1 series have not yet been comprehensively evaluated. To address this gap, this study utilizes the comprehensive Chinese safety benchmark CHiSafetyBench to conduct an in-depth safety evaluation of the DeepSeek-R1 series distilled models. The objective is to assess the safety capabilities of these models in Chinese contexts both before and after distillation, and to further elucidate the adverse effects of distillation on model safety. Building on these findings, we implement targeted safety enhancements for six distilled models. Evaluation results indicate that the enhanced models achieve significant improvements in safety while maintaining reasoning capabilities without notable degradation. We open-source the safety-enhanced models at https://github.com/UnicomAI/DeepSeek-R1-Distill-Safe/tree/main to serve as a valuable resource for future research and optimization of DeepSeek models.
A Multimodal Benchmark Dataset and Model for Crop Disease Diagnosis
Mar 10, 2025While conversational generative AI has shown considerable potential in enhancing decision-making for agricultural professionals, its exploration has predominantly been anchored in text-based interactions. The evolution of multimodal conversational AI, leveraging vast amounts of image-text data from diverse sources, marks a significant stride forward. However, the application of such advanced vision-language models in the agricultural domain, particularly for crop disease diagnosis, remains underexplored. In this work, we present the crop disease domain multimodal (CDDM) dataset, a pioneering resource designed to advance the field of agricultural research through the application of multimodal learning techniques. The dataset comprises 137,000 images of various crop diseases, accompanied by 1 million question-answer pairs that span a broad spectrum of agricultural knowledge, from disease identification to management practices. By integrating visual and textual data, CDDM facilitates the development of sophisticated question-answering systems capable of providing precise, useful advice to farmers and agricultural professionals. We demonstrate the utility of the dataset by finetuning state-of-the-art multimodal models, showcasing significant improvements in crop disease diagnosis. Specifically, we employed a novel finetuning strategy that utilizes low-rank adaptation (LoRA) to finetune the visual encoder, adapter and language model simultaneously. Our contributions include not only the dataset but also a finetuning strategy and a benchmark to stimulate further research in agricultural technology, aiming to bridge the gap between advanced AI techniques and practical agricultural applications. The dataset is available at https: //github.com/UnicomAI/UnicomBenchmark/tree/main/CDDMBench.
Optimizing for the Shortest Path in Denoising Diffusion Model
Mar 06, 2025In this research, we propose a novel denoising diffusion model based on shortest-path modeling that optimizes residual propagation to enhance both denoising efficiency and quality. Drawing on Denoising Diffusion Implicit Models (DDIM) and insights from graph theory, our model, termed the Shortest Path Diffusion Model (ShortDF), treats the denoising process as a shortest-path problem aimed at minimizing reconstruction error. By optimizing the initial residuals, we improve the efficiency of the reverse diffusion process and the quality of the generated samples. Extensive experiments on multiple standard benchmarks demonstrate that ShortDF significantly reduces diffusion time (or steps) while enhancing the visual fidelity of generated samples compared to prior arts. This work, we suppose, paves the way for interactive diffusion-based applications and establishes a foundation for rapid data generation. Code is available at https://github.com/UnicomAI/ShortDF