 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Deep Fusion Framework for Multi-dimensional Facial Forgery Detection -- The 2024 Global Deepfake Image Detection Challenge
Sep 16, 2025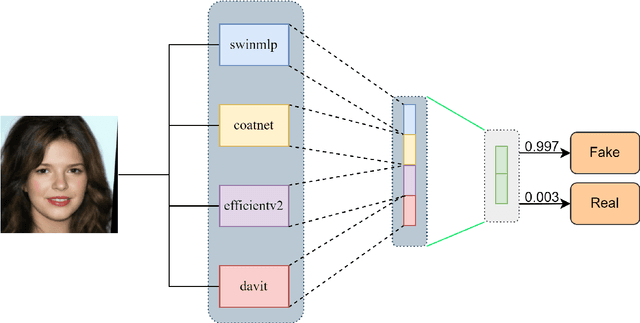

The proliferation of sophisticated deepfake technology poses significant challenges to digital security and authenticity. Detecting these forgeries, especially across a wide spectrum of manipulation techniques, requires robust and generalized models. This paper introduces the Hierarchical Deep Fusion Framework (HDFF), an ensemble-based deep learning architecture designed for high-performance facial forgery detection. Our framework integrates four diverse pre-trained sub-models, Swin-MLP, CoAtNet, EfficientNetV2, and DaViT, which are meticulously fine-tuned through a multi-stage process on the MultiFFDI dataset. By concatenating the feature representations from these specialized models and training a final classifier layer, HDFF effectively leverages their collective strengths. This approach achieved a final score of 0.96852 on the competition's private leaderboard, securing the 20th position out of 184 teams, demonstrating the efficacy of hierarchical fusion for complex image classification tasks.
SLearnLLM: A Self-Learning Framework for Efficient Domain-Specific Adaptation of Large Language Models
May 23, 2025



When using supervised fine-tuning (SFT) to adapt large language models (LLMs) to specific domains, a significant challenge arises: should we use the entire SFT dataset for fine-tuning? Common practice often involves fine-tuning directly on the entire dataset due to limited information on the LLM's past training data. However, if the SFT dataset largely overlaps with the model's existing knowledge, the performance gains are minimal, leading to wasted computational resources. Identifying the unknown knowledge within the SFT dataset and using it to fine-tune the model could substantially improve the training efficiency. To address this challenge, we propose a self-learning framework for LLMs inspired by human learning pattern. This framework takes a fine-tuning (SFT) dataset in a specific domain as input. First, the LLMs answer the questions in the SFT dataset. The LLMs then objectively grade the responses and filter out the incorrectly answered QA pairs. Finally, we fine-tune the LLMs based on this filtered QA set. Experimental results in the fields of agriculture and medicine demonstrate that our method substantially reduces training time while achieving comparable improvements to those attained with full dataset fine-tuning. By concentrating on the unknown knowledge within the SFT dataset, our approach enhances the efficiency of fine-tuning LLMs.
A Large Vision-Language Model based Environment Perception System for Visually Impaired People
Apr 25, 2025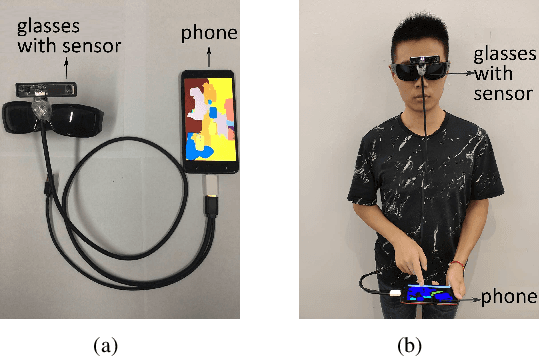
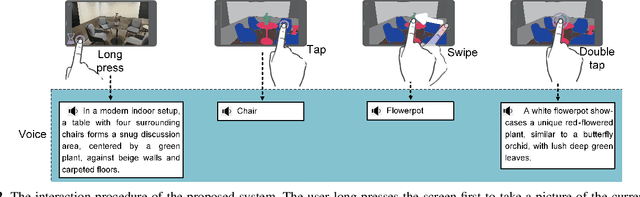
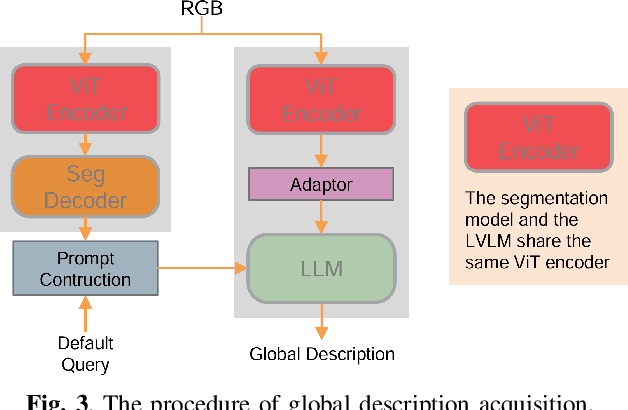

It is a challenging task for visually impaired people to perceive their surrounding environment due to the complexity of the natural scenes. Their personal and social activities are thus highly limited. This paper introduces a Large Vision-Language Model(LVLM) based environment perception system which helps them to better understand the surrounding environment, by capturing the current scene they face with a wearable device, and then letting them retrieve the analysis results through the device. The visually impaired people could acquire a global description of the scene by long pressing the screen to activate the LVLM output, retrieve the categories of the objects in the scene resulting from a segmentation model by tapping or swiping the screen, and get a detailed description of the objects they are interested in by double-tapping the screen. To help visually impaired people more accurately perceive the world, this paper proposes incorporating the segmentation result of the RGB image as external knowledge into the input of LVLM to reduce the LVLM's hallucination. Technical experiments on POPE, MME and LLaVA-QA90 show that the system could provide a more accurate description of the scene compared to Qwen-VL-Chat, exploratory experiments show that the system helps visually impaired people to perceive the surrounding environment effectively.
A Multimodal Benchmark Dataset and Model for Crop Disease Diagnosis
Mar 10, 2025While conversational generative AI has shown considerable potential in enhancing decision-making for agricultural professionals, its exploration has predominantly been anchored in text-based interactions. The evolution of multimodal conversational AI, leveraging vast amounts of image-text data from diverse sources, marks a significant stride forward. However, the application of such advanced vision-language models in the agricultural domain, particularly for crop disease diagnosis, remains underexplored. In this work, we present the crop disease domain multimodal (CDDM) dataset, a pioneering resource designed to advance the field of agricultural research through the application of multimodal learning techniques. The dataset comprises 137,000 images of various crop diseases, accompanied by 1 million question-answer pairs that span a broad spectrum of agricultural knowledge, from disease identification to management practices. By integrating visual and textual data, CDDM facilitates the development of sophisticated question-answering systems capable of providing precise, useful advice to farmers and agricultural professionals. We demonstrate the utility of the dataset by finetuning state-of-the-art multimodal models, showcasing significant improvements in crop disease diagnosis. Specifically, we employed a novel finetuning strategy that utilizes low-rank adaptation (LoRA) to finetune the visual encoder, adapter and language model simultaneously. Our contributions include not only the dataset but also a finetuning strategy and a benchmark to stimulate further research in agricultural technology, aiming to bridge the gap between advanced AI techniques and practical agricultural applications. The dataset is available at https: //github.com/UnicomAI/UnicomBenchmark/tree/main/CDDMBench.
Piculet: Specialized Models-Guided Hallucination Decrease for MultiModal Large Language Models
Aug 02, 2024



Multimodal Large Language Models (MLLMs) have made significant progress in bridging the gap between visual and language modalities. However, hallucinations in MLLMs, where the generated text does not align with image content, continue to be a major challenge. Existing methods for addressing hallucinations often rely on instruction-tuning, which requires retraining the model with specific data, which increases the cost of utilizing MLLMs further. In this paper, we introduce a novel training-free method, named Piculet, for enhancing the input representation of MLLMs. Piculet leverages multiple specialized models to extract descriptions of visual information from the input image and combine these descriptions with the original image and query as input to the MLLM. We evaluate our method both quantitively and qualitatively, and the results demonstrate that Piculet greatly decreases hallucinations of MLLMs. Our method can be easily extended to different MLLMs while being universal.
Application-Driven AI Paradigm for Hand-Held Action Detection
Oct 13, 2022
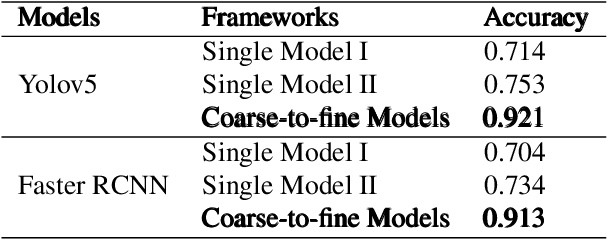
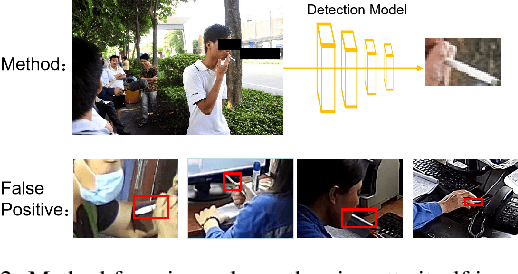
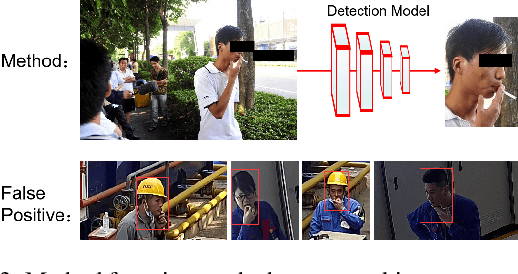
In practical applications especially with safety requirement, some hand-held actions need to be monitored closely, including smoking cigarettes, dialing, eating, etc. Taking smoking cigarettes as example, existing smoke detection algorithms usually detect the cigarette or cigarette with hand as the target object only, which leads to low accuracy. In this paper, we propose an application-driven AI paradigm for hand-held action detection based on hierarchical object detection. It is a coarse-to-fine hierarchical detection framework composed of two modules. The first one is a coarse detection module with the human pose consisting of the whole hand, cigarette and head as target object. The followed second one is a fine detection module with the fingers holding cigarette, mouth area and the whole cigarette as target. Some experiments are done with the dataset collected from real-world scenarios, and the results show that the proposed framework achieve higher detection rate with good adaptation and robustness in complex environments.