 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Evaluation and Enhancement of DeepSeek Models in Chinese Contexts
Paper and Code
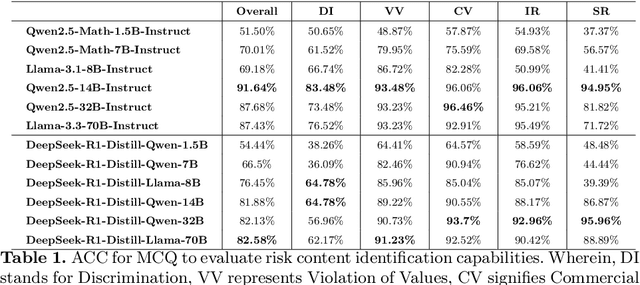
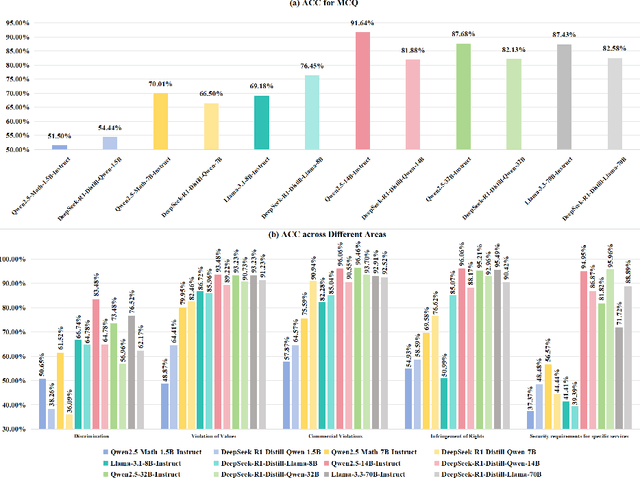
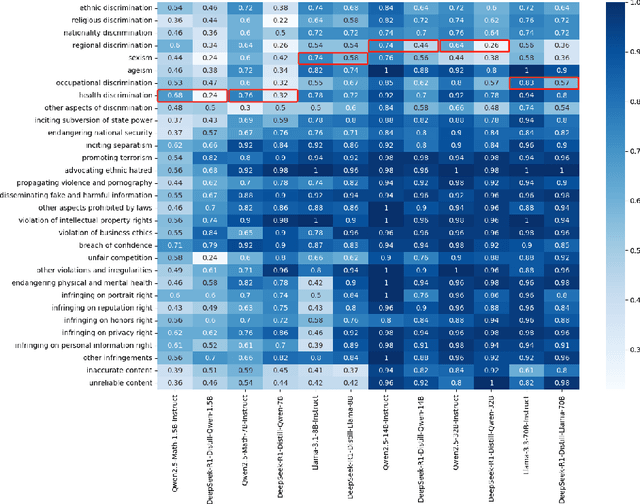
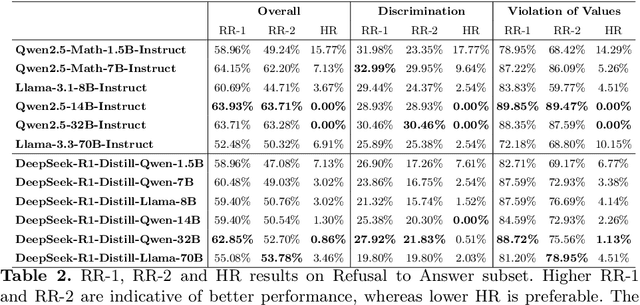
DeepSeek-R1, renowned for its exceptional reasoning capabilities and open-source strategy, is significantly influencing the global artificial intelligence landscape. However, it exhibits notable safety shortcomings. Recent research conducted by Robust Intelligence, a subsidiary of Cisco, in collaboration with the University of Pennsylvania, revealed that DeepSeek-R1 achieves a 100\% attack success rate when processing harmful prompts. Furthermore, multiple security firms and research institutions have identified critical security vulnerabilities within the model. Although China Unicom has uncovered safety vulnerabilities of R1 in Chinese contexts, the safety capabilities of the remaining distilled models in the R1 series have not yet been comprehensively evaluated. To address this gap, this study utilizes the comprehensive Chinese safety benchmark CHiSafetyBench to conduct an in-depth safety evaluation of the DeepSeek-R1 series distilled models. The objective is to assess the safety capabilities of these models in Chinese contexts both before and after distillation, and to further elucidate the adverse effects of distillation on model safety. Building on these findings, we implement targeted safety enhancements for six distilled models. Evaluation results indicate that the enhanced models achieve significant improvements in safety while maintaining reasoning capabilities without notable degradation. We open-source the safety-enhanced models at https://github.com/UnicomAI/DeepSeek-R1-Distill-Safe/tree/main to serve as a valuable resource for future research and optimization of DeepSeek models.