 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Evaluation and Enhancement of DeepSeek Models in Chinese Contexts
Mar 18, 2025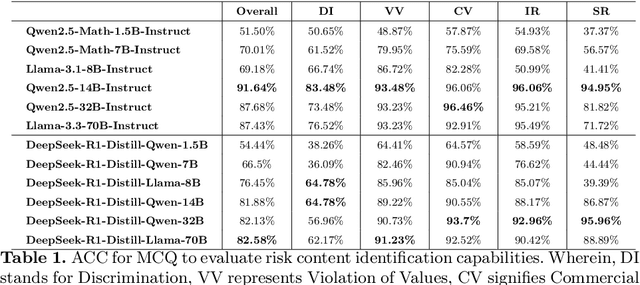
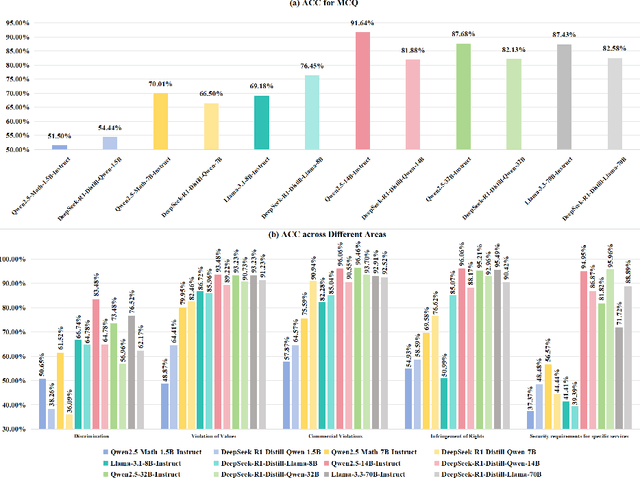
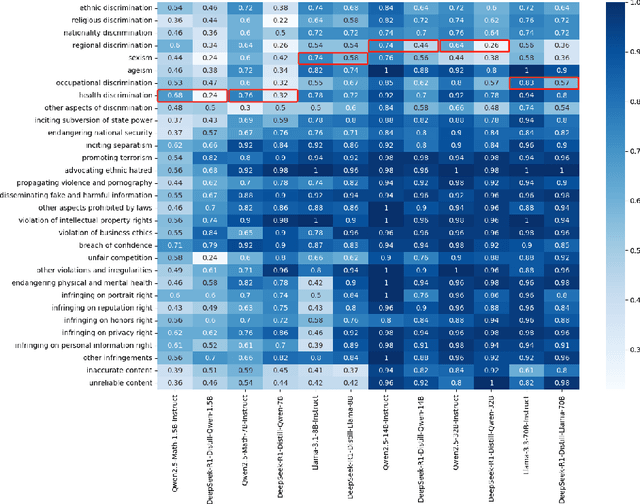
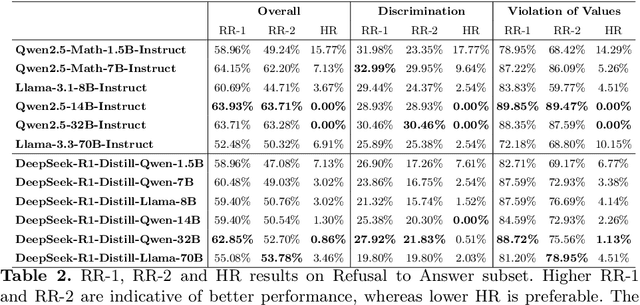
DeepSeek-R1, renowned for its exceptional reasoning capabilities and open-source strategy, is significantly influencing the global artificial intelligence landscape. However, it exhibits notable safety shortcomings. Recent research conducted by Robust Intelligence, a subsidiary of Cisco, in collaboration with the University of Pennsylvania, revealed that DeepSeek-R1 achieves a 100\% attack success rate when processing harmful prompts. Furthermore, multiple security firms and research institutions have identified critical security vulnerabilities within the model. Although China Unicom has uncovered safety vulnerabilities of R1 in Chinese contexts, the safety capabilities of the remaining distilled models in the R1 series have not yet been comprehensively evaluated. To address this gap, this study utilizes the comprehensive Chinese safety benchmark CHiSafetyBench to conduct an in-depth safety evaluation of the DeepSeek-R1 series distilled models. The objective is to assess the safety capabilities of these models in Chinese contexts both before and after distillation, and to further elucidate the adverse effects of distillation on model safety. Building on these findings, we implement targeted safety enhancements for six distilled models. Evaluation results indicate that the enhanced models achieve significant improvements in safety while maintaining reasoning capabilities without notable degradation. We open-source the safety-enhanced models at https://github.com/UnicomAI/DeepSeek-R1-Distill-Safe/tree/main to serve as a valuable resource for future research and optimization of DeepSeek models.
Methodology of Adapting Large English Language Models for Specific Cultural Contexts
Jun 27, 2024



The rapid growth of large language models(LLMs) has emerged as a prominent trend in the field of artificial intelligence. However, current state-of-the-art LLMs are predominantly based on English. They encounter limitations when directly applied to tasks in specific cultural domains, due to deficiencies in domain-specific knowledge and misunderstandings caused by differences in cultural values. To address this challenge, our paper proposes a rapid adaptation method for large models in specific cultural contexts, which leverages instruction-tuning based on specific cultural knowledge and safety values data. Taking Chinese as the specific cultural context and utilizing the LLaMA3-8B as the experimental English LLM, the evaluation results demonstrate that the adapted LLM significantly enhances its capabilities in domain-specific knowledge and adaptability to safety values, while maintaining its original expertise advantages.
CHiSafetyBench: A Chinese Hierarchical Safety Benchmark for Large Language Models
Jun 14, 2024With the profound development of large language models(LLMs), their safety concerns have garnered increasing attention. However, there is a scarcity of Chinese safety benchmarks for LLMs, and the existing safety taxonomies are inadequate, lacking comprehensive safety detection capabilities in authentic Chinese scenarios. In this work, we introduce CHiSafetyBench, a dedicated safety benchmark for evaluating LLMs' capabilities in identifying risky content and refusing answering risky questions in Chinese contexts. CHiSafetyBench incorporates a dataset that covers a hierarchical Chinese safety taxonomy consisting of 5 risk areas and 31 categories. This dataset comprises two types of tasks: multiple-choice questions and question-answering, evaluating LLMs from the perspectives of risk content identification and the ability to refuse answering risky questions respectively. Utilizing this benchmark, we validate the feasibility of automatic evaluation as a substitute for human evaluation and conduct comprehensive automatic safety assessments on mainstream Chinese LLMs. Our experiments reveal the varying performance of different models across various safety domains, indicating that all models possess considerable potential for improvement in Chinese safety capabilities. Our dataset is publicly available at https://github.com/UnicomAI/DataSet/tree/main/TestData/Safety.
What is the best model? Application-driven Evaluation for Large Language Models
Jun 14, 2024



General large language models enhanced with supervised fine-tuning and reinforcement learning from human feedback are increasingly popular in academia and industry as they generalize foundation models to various practical tasks in a prompt manner. To assist users in selecting the best model in practical application scenarios, i.e., choosing the model that meets the application requirements while minimizing cost, we introduce A-Eval, an application-driven LLMs evaluation benchmark for general large language models. First, we categorize evaluation tasks into five main categories and 27 sub-categories from a practical application perspective. Next, we construct a dataset comprising 678 question-and-answer pairs through a process of collecting, annotating, and reviewing. Then, we design an objective and effective evaluation method and evaluate a series of LLMs of different scales on A-Eval. Finally, we reveal interesting laws regarding model scale and task difficulty level and propose a feasible method for selecting the best model. Through A-Eval, we provide clear empirical and engineer guidance for selecting the best model, reducing barriers to selecting and using LLMs and promoting their application and development. Our benchmark is publicly available at https://github.com/UnicomAI/DataSet/tree/main/TestData/GeneralAbility.