 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Operations-Oriented Inference Optimization Techniques for Large Models
Jun 18, 2026Large model inference optimization serves as a key foundation for supporting the scalable, low-cost, and highly stable operation of large model services. Centered on token-oriented inference optimization technology, this paper proposes for the first time a four-layer technical architecture consisting of Multi-model Fusion, Model Optimization, Compute-Model Fusion, and Compute-Network-Model Fusion. It systematically reviews the key technologies and current industry status across these four levels and analyzes the application value of related technologies in real-world business scenarios. This paper provides a practical technical path for reducing token production costs, improving token service efficiency, ensuring the stability of token supply, and driving the transition of large model services from being merely callable to being operable.
KAConvNet: Kolmogorov-Arnold Convolutional Networks for Vision Recognition
Apr 25, 2026The Convolutional Neural Networks (CNNs) have been the dominant and effective approach for general computer vision tasks. Recently, Kolmogorov-Arnold neural networks (KANs), based on the Kolmogorov-Arnold representation theorem, have shown potential to replace Multi-Layer Perceptrons (MLPs) in deep learning. KANs, which use learnable nonlinear activations on edges and simple summation on nodes, offer fewer parameters and greater explainability compared to MLPs. However, there has been limited exploration of integrating the Kolmogorov-Arnold representation theorem with convolutional methods for computer vision tasks. Existing attempts have merely replaced learnable activation functions with weights, undermining KANs' theoretical foundation and limiting their potential effectiveness. Additionally, the B-spline curves used in KANs suffer from computational inefficiency and a tendency to overfit. In this paper, we propose a novel Kolmogorov-Arnold Convolutional Layer that deeply integrates the Kolmogorov-Arnold representation theorem with convolution. This layer provides stronger method interpretability because it is based on established mathematical theorems and its design has theoretical alignment. Building on the Kolmogorov-Arnold Convolutional Layer, we design an efficient network architecture called KAConvNet, which outperforms existing methods combining KAN and convolution, and achieves competitive performance compared to mainstream ViTs and CNNs. We believe that our work offers valuable insight into the field of artificial intelligence and will inspire the development of more innovative CNNs in the 2020s. The code is publicly available at https://github.com/UnicomAI/KAConvNet.
TIR-Agent: Training an Explorative and Efficient Agent for Image Restoration
Mar 29, 2026Vision-language agents that orchestrate specialized tools for image restoration (IR) have emerged as a promising method, yet most existing frameworks operate in a training-free manner. They rely on heuristic task scheduling and exhaustive tool traversal, resulting in sub-optimal restoration paths and prohibitive computational cost. We argue that the core bottleneck lies in the absence of a learned policy to make decision, as a vision-language model cannot efficiently handle degradation-aware task ordering and tool composition. To this end, we propose TIR-Agent, a trainable image restoration agent that performs a direct tool-calling policy through a two-stage training pipeline of supervised fine-tuning (SFT) followed by reinforcement learning (RL). Two key designs underpin effective RL training: (i) a random perturbation strategy applied to the SFT data, which broadens the policy's exploration over task schedules and tool compositions, and (ii) a multi-dimensional adaptive reward mechanism that dynamically re-weights heterogeneous image quality metrics to mitigate reward hacking. To support high-throughput, asynchronous GPU-based tool invocation during training, we further develop a globally shared model-call pool. Experiments on both in-domain and out-of-domain degradations show that TIR-Agent outperforms 12 baselines, including 6 all-in-one models, 3 training-free agents, and 3 proprietary models, and achieves over 2.5$\times$ inference speedup by eliminating redundant tool executions.
What is the best model? Application-driven Evaluation for Large Language Models
Jun 14, 2024



General large language models enhanced with supervised fine-tuning and reinforcement learning from human feedback are increasingly popular in academia and industry as they generalize foundation models to various practical tasks in a prompt manner. To assist users in selecting the best model in practical application scenarios, i.e., choosing the model that meets the application requirements while minimizing cost, we introduce A-Eval, an application-driven LLMs evaluation benchmark for general large language models. First, we categorize evaluation tasks into five main categories and 27 sub-categories from a practical application perspective. Next, we construct a dataset comprising 678 question-and-answer pairs through a process of collecting, annotating, and reviewing. Then, we design an objective and effective evaluation method and evaluate a series of LLMs of different scales on A-Eval. Finally, we reveal interesting laws regarding model scale and task difficulty level and propose a feasible method for selecting the best model. Through A-Eval, we provide clear empirical and engineer guidance for selecting the best model, reducing barriers to selecting and using LLMs and promoting their application and development. Our benchmark is publicly available at https://github.com/UnicomAI/DataSet/tree/main/TestData/GeneralAbility.
KS-DETR: Knowledge Sharing in Attention Learning for Detection Transformer
Feb 22, 2023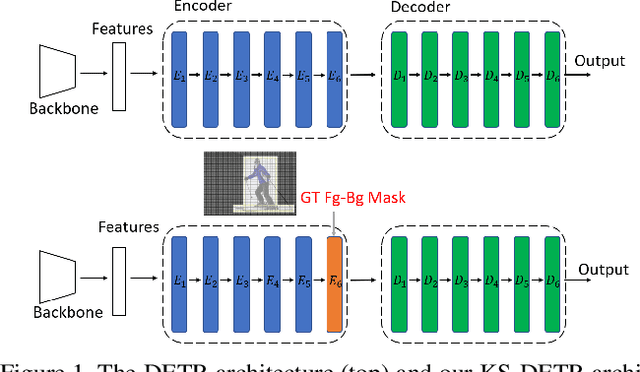

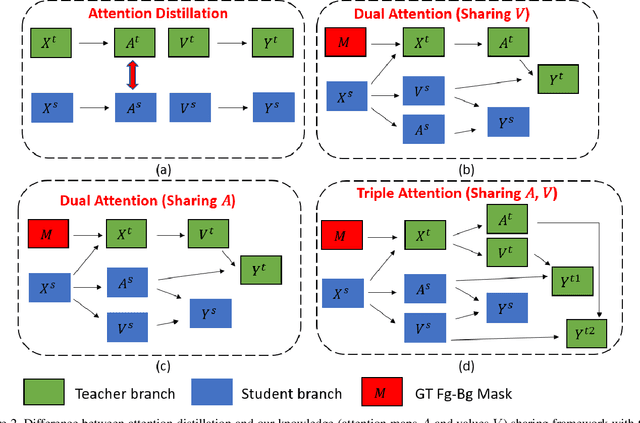
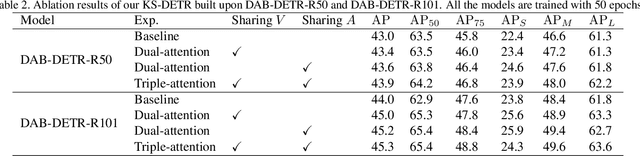
Scaled dot-product attention applies a softmax function on the scaled dot-product of queries and keys to calculate weights and then multiplies the weights and values. In this work, we study how to improve the learning of scaled dot-product attention to improve the accuracy of DETR. Our method is based on the following observations: using ground truth foreground-background mask (GT Fg-Bg Mask) as additional cues in the weights/values learning enables learning much better weights/values; with better weights/values, better values/weights can be learned. We propose a triple-attention module in which the first attention is a plain scaled dot-product attention, the second/third attention generates high-quality weights/values (with the assistance of GT Fg-Bg Mask) and shares the values/weights with the first attention to improve the quality of values/weights. The second and third attentions are removed during inference. We call our method knowledge-sharing DETR (KS-DETR), which is an extension of knowledge distillation (KD) in the way that the improved weights and values of the teachers (the second and third attentions) are directly shared, instead of mimicked, by the student (the first attention) to enable more efficient knowledge transfer from the teachers to the student. Experiments on various DETR-like methods show consistent improvements over the baseline methods on the MS COCO benchmark. Code is available at https://github.com/edocanonymous/KS-DETR.
Application-Driven AI Paradigm for Human Action Recognition
Sep 30, 2022
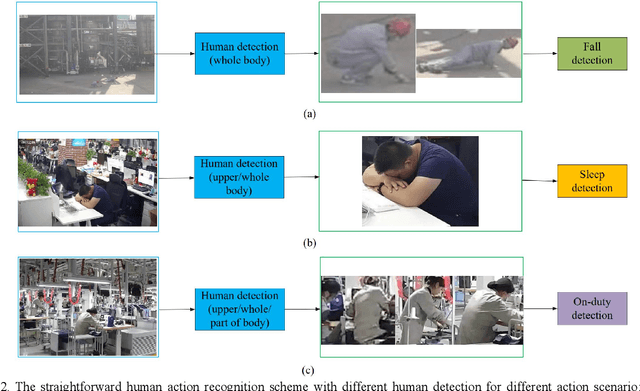
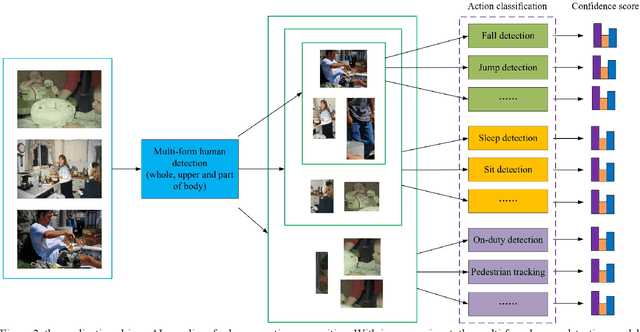

Human action recognition in computer vision has been widely studied in recent years. However, most algorithms consider only certain action specially with even high computational cost. That is not suitable for practical applications with multiple actions to be identified with low computational cost. To meet various application scenarios, this paper presents a unified human action recognition framework composed of two modules, i.e., multi-form human detection and corresponding action classification. Among them, an open-source dataset is constructed to train a multi-form human detection model that distinguishes a human being's whole body, upper body or part body, and the followed action classification model is adopted to recognize such action as falling, sleeping or on-duty, etc. Some experimental results show that the unified framework is effective for various application scenarios. It is expected to be a new application-driven AI paradigm for human action recognition.
A Waste Copper Granules Rating System Based on Machine Vision
Jul 14, 2022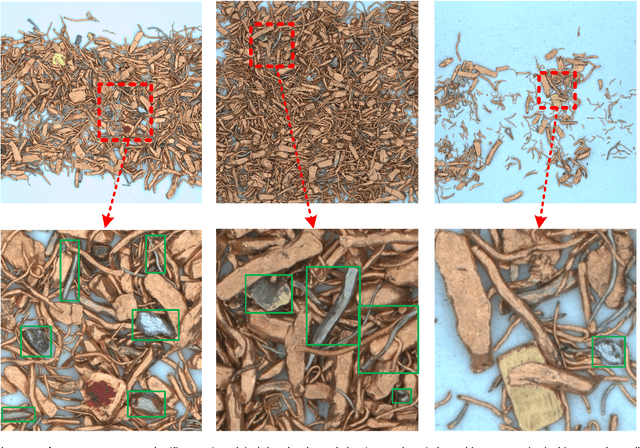
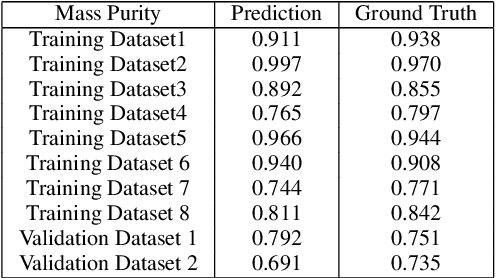


In the field of waste copper granules recycling, engineers should be able to identify all different sorts of impurities in waste copper granules and estimate their mass proportion relying on experience before rating. This manual rating method is costly, lacking in objectivity and comprehensiveness. To tackle this problem, we propose a waste copper granules rating system based on machine vision and deep learning. We firstly formulate the rating task into a 2D image recognition and purity regression task. Then we design a two-stage convolutional rating network to compute the mass purity and rating level of waste copper granules. Our rating network includes a segmentation network and a purity regression network, which respectively calculate the semantic segmentation heatmaps and purity results of the waste copper granules. After training the rating network on the augmented datasets, experiments on real waste copper granules demonstrate the effectiveness and superiority of the proposed network. Specifically, our system is superior to the manual method in terms of accuracy, effectiveness, robustness, and objectivity.
ESmodels: An Epistemic Specification Solver
May 14, 2014(To appear in Theory and Practice of Logic Programming (TPLP)) ESmodels is designed and implemented as an experiment platform to investigate the semantics, language, related reasoning algorithms, and possible applications of epistemic specifications.We first give the epistemic specification language of ESmodels and its semantics. The language employs only one modal operator K but we prove that it is able to represent luxuriant modal operators by presenting transformation rules. Then, we describe basic algorithms and optimization approaches used in ESmodels. After that, we discuss possible applications of ESmodels in conformant planning and constraint satisfaction. Finally, we conclude with perspectives.