 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-in-the-loop Adaptation in Group Activity Feature Learning for Team Sports Video Retrieval
Feb 03, 2026This paper proposes human-in-the-loop adaptation for Group Activity Feature Learning (GAFL) without group activity annotations. This human-in-the-loop adaptation is employed in a group-activity video retrieval framework to improve its retrieval performance. Our method initially pre-trains the GAF space based on the similarity of group activities in a self-supervised manner, unlike prior work that classifies videos into pre-defined group activity classes in a supervised learning manner. Our interactive fine-tuning process updates the GAF space to allow a user to better retrieve videos similar to query videos given by the user. In this fine-tuning, our proposed data-efficient video selection process provides several videos, which are selected from a video database, to the user in order to manually label these videos as positive or negative. These labeled videos are used to update (i.e., fine-tune) the GAF space, so that the positive and negative videos move closer to and farther away from the query videos through contrastive learning. Our comprehensive experimental results on two team sports datasets validate that our method significantly improves the retrieval performance. Ablation studies also demonstrate that several components in our human-in-the-loop adaptation contribute to the improvement of the retrieval performance. Code: https://github.com/chihina/GAFL-FINE-CVIU.
* Accepted to Computer Vision and Image Understanding (CVIU)
MMCM: Multimodality-aware Metric using Clustering-based Modes for Probabilistic Human Motion Prediction
Nov 19, 2025



This paper proposes a novel metric for Human Motion Prediction (HMP). Since a single past sequence can lead to multiple possible futures, a probabilistic HMP method predicts such multiple motions. While a single motion predicted by a deterministic method is evaluated only with the difference from its ground truth motion, multiple predicted motions should also be evaluated based on their distribution. For this evaluation, this paper focuses on the following two criteria. \textbf{(a) Coverage}: motions should be distributed among multiple motion modes to cover diverse possibilities. \textbf{(b) Validity}: motions should be kinematically valid as future motions observable from a given past motion. However, existing metrics simply appreciate widely distributed motions even if these motions are observed in a single mode and kinematically invalid. To resolve these disadvantages, this paper proposes a Multimodality-aware Metric using Clustering-based Modes (MMCM). For (a) coverage, MMCM divides a motion space into several clusters, each of which is regarded as a mode. These modes are used to explicitly evaluate whether predicted motions are distributed among multiple modes. For (b) validity, MMCM identifies valid modes by collecting possible future motions from a motion dataset. Our experiments validate that our clustering yields sensible mode definitions and that MMCM accurately scores multimodal predictions. Code: https://github.com/placerkyo/MMCM
Dynamic Group Detection using VLM-augmented Temporal Groupness Graph
Sep 05, 2025This paper proposes dynamic human group detection in videos. For detecting complex groups, not only the local appearance features of in-group members but also the global context of the scene are important. Such local and global appearance features in each frame are extracted using a Vision-Language Model (VLM) augmented for group detection in our method. For further improvement, the group structure should be consistent over time. While previous methods are stabilized on the assumption that groups are not changed in a video, our method detects dynamically changing groups by global optimization using a graph with all frames' groupness probabilities estimated by our groupness-augmented CLIP features. Our experimental results demonstrate that our method outperforms state-of-the-art group detection methods on public datasets. Code: https://github.com/irajisamurai/VLM-GroupDetection.git
CacheFlow: Fast Human Motion Prediction by Cached Normalizing Flow
May 19, 2025Many density estimation techniques for 3D human motion prediction require a significant amount of inference time, often exceeding the duration of the predicted time horizon. To address the need for faster density estimation for 3D human motion prediction, we introduce a novel flow-based method for human motion prediction called CacheFlow. Unlike previous conditional generative models that suffer from time efficiency, CacheFlow takes advantage of an unconditional flow-based generative model that transforms a Gaussian mixture into the density of future motions. The results of the computation of the flow-based generative model can be precomputed and cached. Then, for conditional prediction, we seek a mapping from historical trajectories to samples in the Gaussian mixture. This mapping can be done by a much more lightweight model, thus saving significant computation overhead compared to a typical conditional flow model. In such a two-stage fashion and by caching results from the slow flow model computation, we build our CacheFlow without loss of prediction accuracy and model expressiveness. This inference process is completed in approximately one millisecond, making it 4 times faster than previous VAE methods and 30 times faster than previous diffusion-based methods on standard benchmarks such as Human3.6M and AMASS datasets. Furthermore, our method demonstrates improved density estimation accuracy and comparable prediction accuracy to a SOTA method on Human3.6M. Our code and models will be publicly available.
Human Motion Prediction via Test-domain-aware Adaptation with Easily-available Human Motions Estimated from Videos
May 13, 2025In 3D Human Motion Prediction (HMP), conventional methods train HMP models with expensive motion capture data. However, the data collection cost of such motion capture data limits the data diversity, which leads to poor generalizability to unseen motions or subjects. To address this issue, this paper proposes to enhance HMP with additional learning using estimated poses from easily available videos. The 2D poses estimated from the monocular videos are carefully transformed into motion capture-style 3D motions through our pipeline. By additional learning with the obtained motions, the HMP model is adapted to the test domain. The experimental results demonstrate the quantitative and qualitative impact of our method.
Robot Motion Planning using One-Step Diffusion with Noise-Optimized Approximate Motions
Apr 28, 2025This paper proposes an image-based robot motion planning method using a one-step diffusion model. While the diffusion model allows for high-quality motion generation, its computational cost is too expensive to control a robot in real time. To achieve high quality and efficiency simultaneously, our one-step diffusion model takes an approximately generated motion, which is predicted directly from input images. This approximate motion is optimized by additive noise provided by our novel noise optimizer. Unlike general isotropic noise, our noise optimizer adjusts noise anisotropically depending on the uncertainty of each motion element. Our experimental results demonstrate that our method outperforms state-of-the-art methods while maintaining its efficiency by one-step diffusion.
Physical Plausibility-aware Trajectory Prediction via Locomotion Embodiment
Mar 21, 2025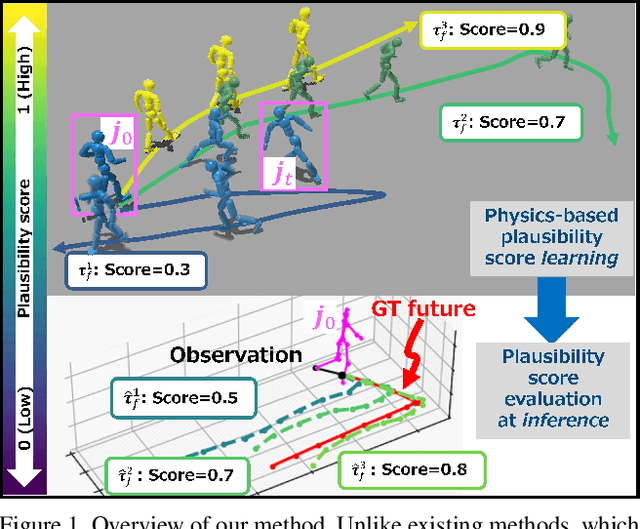
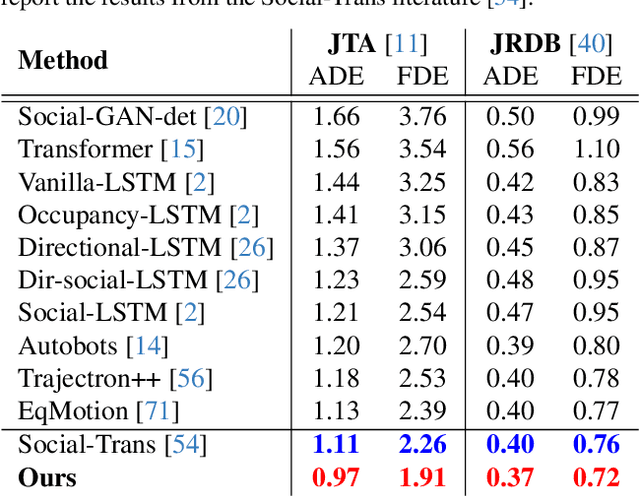
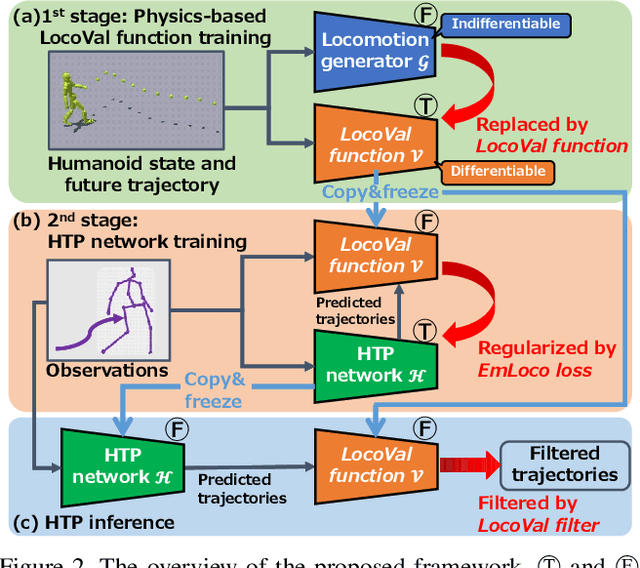

Humans can predict future human trajectories even from momentary observations by using human pose-related cues. However, previous Human Trajectory Prediction (HTP) methods leverage the pose cues implicitly, resulting in implausible predictions. To address this, we propose Locomotion Embodiment, a framework that explicitly evaluates the physical plausibility of the predicted trajectory by locomotion generation under the laws of physics. While the plausibility of locomotion is learned with an indifferentiable physics simulator, it is replaced by our differentiable Locomotion Value function to train an HTP network in a data-driven manner. In particular, our proposed Embodied Locomotion loss is beneficial for efficiently training a stochastic HTP network using multiple heads. Furthermore, the Locomotion Value filter is proposed to filter out implausible trajectories at inference. Experiments demonstrate that our method enhances even the state-of-the-art HTP methods across diverse datasets and problem settings. Our code is available at: https://github.com/ImIntheMiddle/EmLoco.
Size-Variable Virtual Try-On with Physical Clothes Size
Dec 09, 2024



This paper addresses a new virtual try-on problem of fitting any size of clothes to a reference person in the image domain. While previous image-based virtual try-on methods can produce highly natural try-on images, these methods fit the clothes on the person without considering the relative relationship between the physical sizes of the clothes and the person. Different from these methods, our method achieves size-variable virtual try-on in which the image size of the try-on clothes is changed depending on this relative relationship of the physical sizes. To relieve the difficulty in maintaining the physical size of the closes while synthesizing the high-fidelity image of the whole clothes, our proposed method focuses on the residual between the silhouettes of the clothes in the reference and try-on images. We also develop a size-variable virtual try-on dataset consisting of 1,524 images provided by 26 subjects. Furthermore, we propose an evaluation metric for size-variable virtual-try-on. Quantitative and qualitative experimental results show that our method can achieve size-variable virtual try-on better than general virtual try-on methods.
Test-time Cost-and-Quality Controllable Arbitrary-Scale Super-Resolution with Variable Fourier Components
Dec 07, 2024



Super-resolution (SR) with arbitrary scale factor and cost-and-quality controllability at test time is essential for various applications. While several arbitrary-scale SR methods have been proposed, these methods require us to modify the model structure and retrain it to control the computational cost and SR quality. To address this limitation, we propose a novel SR method using a Recurrent Neural Network (RNN) with the Fourier representation. In our method, the RNN sequentially estimates Fourier components, each consisting of frequency and amplitude, and aggregates these components to reconstruct an SR image. Since the RNN can adjust the number of recurrences at test time, we can control the computational cost and SR quality in a single model: fewer recurrences (i.e., fewer Fourier components) lead to lower cost but lower quality, while more recurrences (i.e., more Fourier components) lead to better quality but more cost. Experimental results prove that more Fourier components improve the PSNR score. Furthermore, even with fewer Fourier components, our method achieves a lower PSNR drop than other state-of-the-art arbitrary-scale SR methods.
Burst Super-Resolution with Diffusion Models for Improving Perceptual Quality
Apr 08, 2024



While burst LR images are useful for improving the SR image quality compared with a single LR image, prior SR networks accepting the burst LR images are trained in a deterministic manner, which is known to produce a blurry SR image. In addition, it is difficult to perfectly align the burst LR images, making the SR image more blurry. Since such blurry images are perceptually degraded, we aim to reconstruct the sharp high-fidelity boundaries. Such high-fidelity images can be reconstructed by diffusion models. However, prior SR methods using the diffusion model are not properly optimized for the burst SR task. Specifically, the reverse process starting from a random sample is not optimized for image enhancement and restoration methods, including burst SR. In our proposed method, on the other hand, burst LR features are used to reconstruct the initial burst SR image that is fed into an intermediate step in the diffusion model. This reverse process from the intermediate step 1) skips diffusion steps for reconstructing the global structure of the image and 2) focuses on steps for refining detailed textures. Our experimental results demonstrate that our method can improve the scores of the perceptual quality metrics. Code: https://github.com/placerkyo/BSRD