 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-in-the-loop Adaptation in Group Activity Feature Learning for Team Sports Video Retrieval
Feb 03, 2026This paper proposes human-in-the-loop adaptation for Group Activity Feature Learning (GAFL) without group activity annotations. This human-in-the-loop adaptation is employed in a group-activity video retrieval framework to improve its retrieval performance. Our method initially pre-trains the GAF space based on the similarity of group activities in a self-supervised manner, unlike prior work that classifies videos into pre-defined group activity classes in a supervised learning manner. Our interactive fine-tuning process updates the GAF space to allow a user to better retrieve videos similar to query videos given by the user. In this fine-tuning, our proposed data-efficient video selection process provides several videos, which are selected from a video database, to the user in order to manually label these videos as positive or negative. These labeled videos are used to update (i.e., fine-tune) the GAF space, so that the positive and negative videos move closer to and farther away from the query videos through contrastive learning. Our comprehensive experimental results on two team sports datasets validate that our method significantly improves the retrieval performance. Ablation studies also demonstrate that several components in our human-in-the-loop adaptation contribute to the improvement of the retrieval performance. Code: https://github.com/chihina/GAFL-FINE-CVIU.
* Accepted to Computer Vision and Image Understanding (CVIU)
Dynamic Group Detection using VLM-augmented Temporal Groupness Graph
Sep 05, 2025This paper proposes dynamic human group detection in videos. For detecting complex groups, not only the local appearance features of in-group members but also the global context of the scene are important. Such local and global appearance features in each frame are extracted using a Vision-Language Model (VLM) augmented for group detection in our method. For further improvement, the group structure should be consistent over time. While previous methods are stabilized on the assumption that groups are not changed in a video, our method detects dynamically changing groups by global optimization using a graph with all frames' groupness probabilities estimated by our groupness-augmented CLIP features. Our experimental results demonstrate that our method outperforms state-of-the-art group detection methods on public datasets. Code: https://github.com/irajisamurai/VLM-GroupDetection.git
Size-Variable Virtual Try-On with Physical Clothes Size
Dec 09, 2024



This paper addresses a new virtual try-on problem of fitting any size of clothes to a reference person in the image domain. While previous image-based virtual try-on methods can produce highly natural try-on images, these methods fit the clothes on the person without considering the relative relationship between the physical sizes of the clothes and the person. Different from these methods, our method achieves size-variable virtual try-on in which the image size of the try-on clothes is changed depending on this relative relationship of the physical sizes. To relieve the difficulty in maintaining the physical size of the closes while synthesizing the high-fidelity image of the whole clothes, our proposed method focuses on the residual between the silhouettes of the clothes in the reference and try-on images. We also develop a size-variable virtual try-on dataset consisting of 1,524 images provided by 26 subjects. Furthermore, we propose an evaluation metric for size-variable virtual-try-on. Quantitative and qualitative experimental results show that our method can achieve size-variable virtual try-on better than general virtual try-on methods.
Learning Group Activity Features Through Person Attribute Prediction
Mar 11, 2024This paper proposes Group Activity Feature (GAF) learning in which features of multi-person activity are learned as a compact latent vector. Unlike prior work in which the manual annotation of group activities is required for supervised learning, our method learns the GAF through person attribute prediction without group activity annotations. By learning the whole network in an end-to-end manner so that the GAF is required for predicting the person attributes of people in a group, the GAF is trained as the features of multi-person activity. As a person attribute, we propose to use a person's action class and appearance features because the former is easy to annotate due to its simpleness, and the latter requires no manual annotation. In addition, we introduce a location-guided attribute prediction to disentangle the complex GAF for extracting the features of each target person properly. Various experimental results validate that our method outperforms SOTA methods quantitatively and qualitatively on two public datasets. Visualization of our GAF also demonstrates that our method learns the GAF representing fined-grained group activity classes. Code: https://github.com/chihina/GAFL-CVPR2024.
Interaction-aware Joint Attention Estimation Using People Attributes
Aug 10, 2023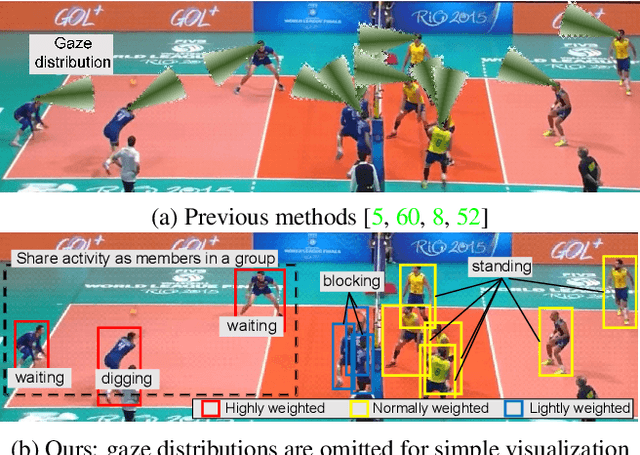

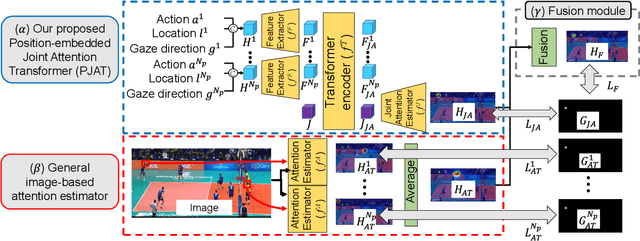
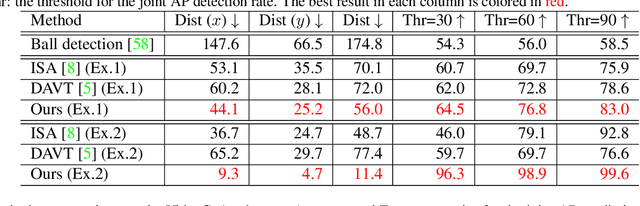
This paper proposes joint attention estimation in a single image. Different from related work in which only the gaze-related attributes of people are independently employed, (I) their locations and actions are also employed as contextual cues for weighting their attributes, and (ii) interactions among all of these attributes are explicitly modeled in our method. For the interaction modeling, we propose a novel Transformer-based attention network to encode joint attention as low-dimensional features. We introduce a specialized MLP head with positional embedding to the Transformer so that it predicts pixelwise confidence of joint attention for generating the confidence heatmap. This pixelwise prediction improves the heatmap accuracy by avoiding the ill-posed problem in which the high-dimensional heatmap is predicted from the low-dimensional features. The estimated joint attention is further improved by being integrated with general image-based attention estimation. Our method outperforms SOTA methods quantitatively in comparative experiments. Code: https://anonymous.4open.science/r/anonymized_codes-ECA4.