 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Fish Schools via Reinforcement Learning of Virtual Fish Movement
Mar 17, 2026This study investigates a method to guide and control fish schools using virtual fish trained with reinforcement learning. We utilize 2D virtual fish displayed on a screen to overcome technical challenges such as durability and movement constraints inherent in physical robotic agents. To address the lack of detailed behavioral models for real fish, we adopt a model-free reinforcement learning approach. First, simulation results show that reinforcement learning can acquire effective movement policies even when simulated real fish frequently ignore the virtual stimulus. Second, real-world experiments with live fish confirm that the learned policy successfully guides fish schools toward specified target directions. Statistical analysis reveals that the proposed method significantly outperforms baseline conditions, including the absence of stimulus and a heuristic "stay-at-edge" strategy. This study provides an early demonstration of how reinforcement learning can be used to influence collective animal behavior through artificial agents.
Adaptive Policy Switching of Two-Wheeled Differential Robots for Traversing over Diverse Terrains
Mar 05, 2026Exploring lunar lava tubes requires robots to traverse without human intervention. Because pre-trained policies cannot fully cover all possible terrain conditions, our goal is to enable adaptive policy switching, where the robot selects an appropriate terrain-specialized model based on its current terrain features. This study investigates whether terrain types can be estimated effectively using posture-related observations collected during navigation. We fine-tuned a pre-trained policy using Proximal Policy Optimization (PPO), and then collected the robot's 3D orientation data as it moved across flat and rough terrain in a simulated lava-tube environment. Our analysis revealed that the standard deviation of the robot's pitch data shows a clear difference between these two terrain types. Using Gaussian mixture models (GMM), we evaluated terrain classification across various window sizes. An accuracy of more than 98% was achieved when using a 70-step window. The result suggests that short-term orientation data are sufficient for reliable terrain estimation, providing a foundation for adaptive policy switching.
* Author's version of the paper presented at AROB-ISBC 2026
Data-Driven Control of a Magnetically Actuated Fish-Like Robot
Mar 05, 2026Magnetically actuated fish-like robots offer promising solutions for underwater exploration due to their miniaturization and agility; however, precise control remains a significant challenge because of nonlinear fluid dynamics, flexible fin hysteresis, and the variable-duration control steps inherent to the actuation mechanism. This paper proposes a comprehensive data-driven control framework to address these complexities without relying on analytical modeling. Our methodology comprises three core components: 1) developing a forward dynamics model (FDM) using a neural network trained on real-world experimental data to capture state transitions under varying time steps; 2) integrating this FDM into a gradient-based model predictive control (G-MPC) architecture to optimize control inputs for path following; and 3) applying imitation learning to approximate the G-MPC policy, thereby reducing the computational cost for real-time implementation. We validate the approach through simulations utilizing the identified dynamics model. The results demonstrate that the G-MPC framework achieves accurate path convergence with minimal root mean square error (RMSE), and the imitation learning controller (ILC) effectively replicates this performance. This study highlights the potential of data-driven control strategies for the precise navigation of miniature, fish-like soft robots.
* Author's version of the paper presented at AROB-ISBC 2026
LLM-Guided Decentralized Exploration with Self-Organizing Robot Teams
Mar 05, 2026When individual robots have limited sensing capabilities or insufficient fault tolerance, it becomes necessary for multiple robots to form teams during exploration, thereby increasing the collective observation range and reliability. Traditionally, swarm formation has often been managed by a central controller; however, from the perspectives of robustness and flexibility, it is preferable for the swarm to operate autonomously even in the absence of centralized control. In addition, the determination of exploration targets for each team is crucial for efficient exploration in such multi-team exploration scenarios. This study therefore proposes an exploration method that combines (1) an algorithm for self-organization, enabling the autonomous and dynamic formation of multiple teams, and (2) an algorithm that allows each team to autonomously determine its next exploration target (destination). In particular, for (2), this study explores a novel strategy based on large language models (LLMs), while classical frontier-based methods and deep reinforcement learning approaches have been widely studied. The effectiveness of the proposed method was validated through simulations involving tens to hundreds of robots.
* Author's version of the paper presented at AROB-ISBC 2026
Tracking Feral Horses in Aerial Video Using Oriented Bounding Boxes
Mar 04, 2026The social structures of group-living animals such as feral horses are diverse and remain insufficiently understood, even within a single species. To investigate group dynamics, aerial videos are often utilized to track individuals and analyze their movement trajectories, which are essential for evaluating inter-individual interactions and comparing social behaviors. Accurate individual tracking is therefore crucial. In multi-animal tracking, axis-aligned bounding boxes (bboxes) are widely used; however, for aerial top-view footage of entire groups, their performance degrades due to complex backgrounds, small target sizes, high animal density, and varying body orientations. To address this issue, we employ oriented bounding boxes (OBBs), which include rotation angles and reduce unnecessary background. Nevertheless, current OBB detectors such as YOLO-OBB restrict angles within a 180$^{\circ}$ range, making it impossible to distinguish head from tail and often causing sudden 180$^{\circ}$ flips across frames, which severely disrupts continuous tracking. To overcome this limitation, we propose a head-orientation estimation method that crops OBB-centered patches, applies three detectors (head, tail, and head-tail), and determines the final label through IoU-based majority voting. Experiments using 299 test images show that our method achieves 99.3% accuracy, outperforming individual models, demonstrating its effectiveness for robust OBB-based tracking.
* Author's version of the paper presented at AROB-ISBC 2026
Detection and Identification of Penguins Using Appearance and Motion Features
Mar 04, 2026In animal facilities, continuous surveillance of penguins is essential yet technically challenging due to their homogeneous visual characteristics, rapid and frequent posture changes, and substantial environmental noise such as water reflections. In this study, we propose a framework that enhances both detection and identification performance by integrating appearance and motion features. For detection, we adapted YOLO11 to process consecutive frames to overcome the lack of temporal consistency in single-frame detectors. This approach leverages motion cues to detect targets even when distinct visual features are obscured. Our evaluation shows that fine-tuning the model with two-frame inputs improves mAP@0.5 from 0.922 to 0.933, outperforming the baseline, and successfully recovers individuals that are indistinguishable in static images. For identification, we introduce a tracklet-based contrastive learning approach applied after tracking. Through qualitative visualization, we demonstrate that the method produces coherent feature embeddings, bringing samples from the same individual closer in the feature space, suggesting the potential for mitigating ID switching.
* Author's version of the paper presented at AROB-ISBC 2026
Human-in-the-loop Adaptation in Group Activity Feature Learning for Team Sports Video Retrieval
Feb 03, 2026This paper proposes human-in-the-loop adaptation for Group Activity Feature Learning (GAFL) without group activity annotations. This human-in-the-loop adaptation is employed in a group-activity video retrieval framework to improve its retrieval performance. Our method initially pre-trains the GAF space based on the similarity of group activities in a self-supervised manner, unlike prior work that classifies videos into pre-defined group activity classes in a supervised learning manner. Our interactive fine-tuning process updates the GAF space to allow a user to better retrieve videos similar to query videos given by the user. In this fine-tuning, our proposed data-efficient video selection process provides several videos, which are selected from a video database, to the user in order to manually label these videos as positive or negative. These labeled videos are used to update (i.e., fine-tune) the GAF space, so that the positive and negative videos move closer to and farther away from the query videos through contrastive learning. Our comprehensive experimental results on two team sports datasets validate that our method significantly improves the retrieval performance. Ablation studies also demonstrate that several components in our human-in-the-loop adaptation contribute to the improvement of the retrieval performance. Code: https://github.com/chihina/GAFL-FINE-CVIU.
* Accepted to Computer Vision and Image Understanding (CVIU)
Fish Tracking Challenge 2024: A Multi-Object Tracking Competition with Sweetfish Schooling Data
Aug 31, 2024The study of collective animal behavior, especially in aquatic environments, presents unique challenges and opportunities for understanding movement and interaction patterns in the field of ethology, ecology, and bio-navigation. The Fish Tracking Challenge 2024 (https://ftc-2024.github.io/) introduces a multi-object tracking competition focused on the intricate behaviors of schooling sweetfish. Using the SweetFish dataset, participants are tasked with developing advanced tracking models to accurately monitor the locations of 10 sweetfishes simultaneously. This paper introduces the competition's background, objectives, the SweetFish dataset, and the appraoches of the 1st to 3rd winners and our baseline. By leveraging video data and bounding box annotations, the competition aims to foster innovation in automatic detection and tracking algorithms, addressing the complexities of aquatic animal movements. The challenge provides the importance of multi-object tracking for discovering the dynamics of collective animal behavior, with the potential to significantly advance scientific understanding in the above fields.
Learning Group Activity Features Through Person Attribute Prediction
Mar 11, 2024This paper proposes Group Activity Feature (GAF) learning in which features of multi-person activity are learned as a compact latent vector. Unlike prior work in which the manual annotation of group activities is required for supervised learning, our method learns the GAF through person attribute prediction without group activity annotations. By learning the whole network in an end-to-end manner so that the GAF is required for predicting the person attributes of people in a group, the GAF is trained as the features of multi-person activity. As a person attribute, we propose to use a person's action class and appearance features because the former is easy to annotate due to its simpleness, and the latter requires no manual annotation. In addition, we introduce a location-guided attribute prediction to disentangle the complex GAF for extracting the features of each target person properly. Various experimental results validate that our method outperforms SOTA methods quantitatively and qualitatively on two public datasets. Visualization of our GAF also demonstrates that our method learns the GAF representing fined-grained group activity classes. Code: https://github.com/chihina/GAFL-CVPR2024.
Interaction-aware Joint Attention Estimation Using People Attributes
Aug 10, 2023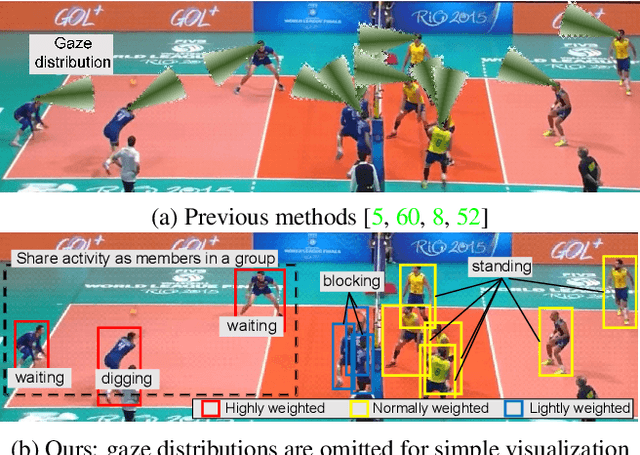

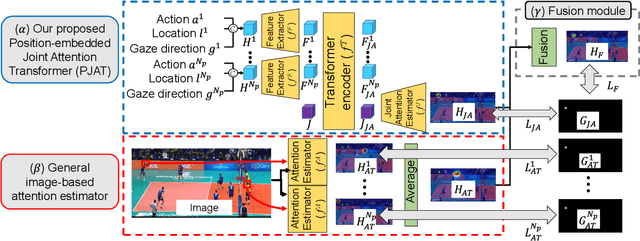
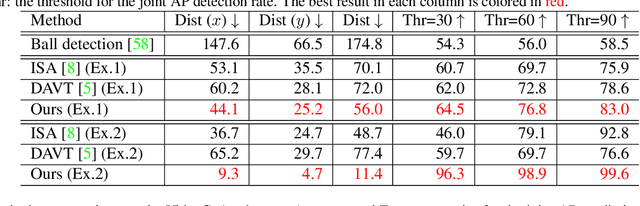
This paper proposes joint attention estimation in a single image. Different from related work in which only the gaze-related attributes of people are independently employed, (I) their locations and actions are also employed as contextual cues for weighting their attributes, and (ii) interactions among all of these attributes are explicitly modeled in our method. For the interaction modeling, we propose a novel Transformer-based attention network to encode joint attention as low-dimensional features. We introduce a specialized MLP head with positional embedding to the Transformer so that it predicts pixelwise confidence of joint attention for generating the confidence heatmap. This pixelwise prediction improves the heatmap accuracy by avoiding the ill-posed problem in which the high-dimensional heatmap is predicted from the low-dimensional features. The estimated joint attention is further improved by being integrated with general image-based attention estimation. Our method outperforms SOTA methods quantitatively in comparative experiments. Code: https://anonymous.4open.science/r/anonymized_codes-ECA4.