 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Plausibility-aware Trajectory Prediction via Locomotion Embodiment
Mar 21, 2025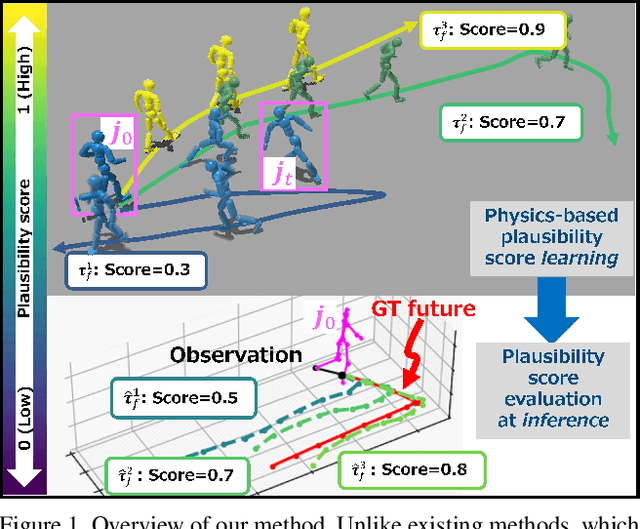
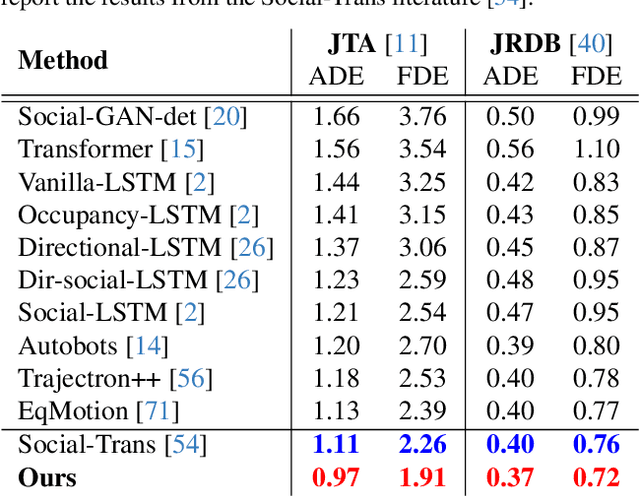
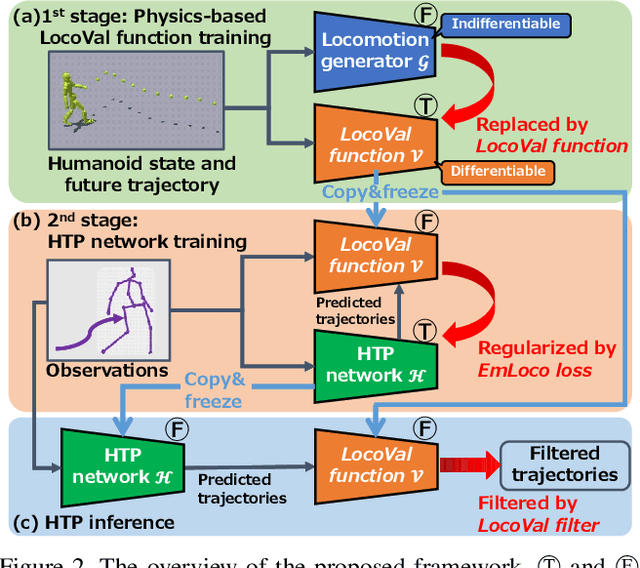

Humans can predict future human trajectories even from momentary observations by using human pose-related cues. However, previous Human Trajectory Prediction (HTP) methods leverage the pose cues implicitly, resulting in implausible predictions. To address this, we propose Locomotion Embodiment, a framework that explicitly evaluates the physical plausibility of the predicted trajectory by locomotion generation under the laws of physics. While the plausibility of locomotion is learned with an indifferentiable physics simulator, it is replaced by our differentiable Locomotion Value function to train an HTP network in a data-driven manner. In particular, our proposed Embodied Locomotion loss is beneficial for efficiently training a stochastic HTP network using multiple heads. Furthermore, the Locomotion Value filter is proposed to filter out implausible trajectories at inference. Experiments demonstrate that our method enhances even the state-of-the-art HTP methods across diverse datasets and problem settings. Our code is available at: https://github.com/ImIntheMiddle/EmLoco.
Spatiotemporal Multi-Camera Calibration using Freely Moving People
Feb 18, 2025



We propose a novel method for spatiotemporal multi-camera calibration using freely moving people in multiview videos. Since calibrating multiple cameras and finding matches across their views are inherently interdependent, performing both in a unified framework poses a significant challenge. We address these issues as a single registration problem of matching two sets of 3D points, leveraging human motion in dynamic multi-person scenes. To this end, we utilize 3D human poses obtained from an off-the-shelf monocular 3D human pose estimator and transform them into 3D points on a unit sphere, to solve the rotation, time offset, and the association alternatingly. We employ a probabilistic approach that can jointly solve both problems of aligning spatiotemporal data and establishing correspondences through soft assignment between two views. The translation is determined by applying coplanarity constraints. The pairwise registration results are integrated into a multiview setup, and then a nonlinear optimization method is used to improve the accuracy of the camera poses, temporal offsets, and multi-person associations. Extensive experiments on synthetic and real data demonstrate the effectiveness and flexibility of the proposed method as a practical marker-free calibration tool.
RatBodyFormer: Rodent Body Surface from Keypoints
Dec 12, 2024


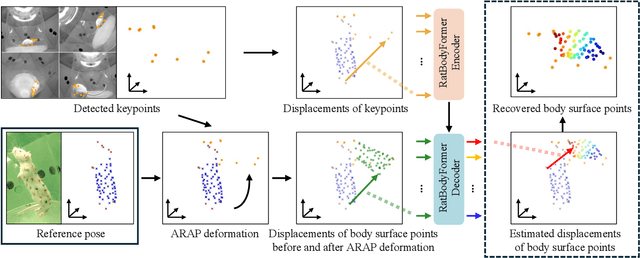
Rat behavior modeling goes to the heart of many scientific studies, yet the textureless body surface evades automatic analysis as it literally has no keypoints that detectors can find. The movement of the body surface, however, is a rich source of information for deciphering the rat behavior. We introduce two key contributions to automatically recover densely 3D sampled rat body surface points, passively. The first is RatDome, a novel multi-camera system for rat behavior capture, and a large-scale dataset captured with it that consists of pairs of 3D keypoints and 3D body surface points. The second is RatBodyFormer, a novel network to transform detected keypoints to 3D body surface points. RatBodyFormer is agnostic to the exact locations of the 3D body surface points in the training data and is trained with masked-learning. We experimentally validate our framework with a number of real-world experiments. Our results collectively serve as a novel foundation for automated rat behavior analysis and will likely have far-reaching implications for biomedical and neuroscientific research.
KFD-NeRF: Rethinking Dynamic NeRF with Kalman Filter
Jul 18, 2024
We introduce KFD-NeRF, a novel dynamic neural radiance field integrated with an efficient and high-quality motion reconstruction framework based on Kalman filtering. Our key idea is to model the dynamic radiance field as a dynamic system whose temporally varying states are estimated based on two sources of knowledge: observations and predictions. We introduce a novel plug-in Kalman filter guided deformation field that enables accurate deformation estimation from scene observations and predictions. We use a shallow Multi-Layer Perceptron (MLP) for observations and model the motion as locally linear to calculate predictions with motion equations. To further enhance the performance of the observation MLP, we introduce regularization in the canonical space to facilitate the network's ability to learn warping for different frames. Additionally, we employ an efficient tri-plane representation for encoding the canonical space, which has been experimentally demonstrated to converge quickly with high quality. This enables us to use a shallower observation MLP, consisting of just two layers in our implementation. We conduct experiments on synthetic and real data and compare with past dynamic NeRF methods. Our KFD-NeRF demonstrates similar or even superior rendering performance within comparable computational time and achieves state-of-the-art view synthesis performance with thorough training.
SPIDeRS: Structured Polarization for Invisible Depth and Reflectance Sensing
Dec 07, 2023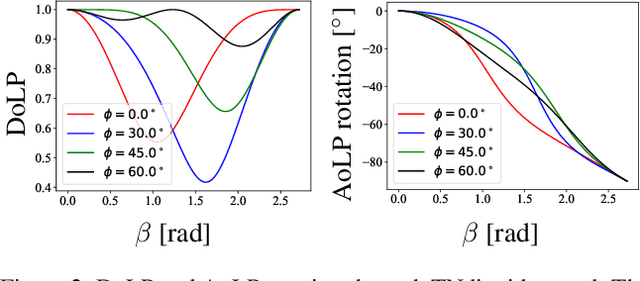

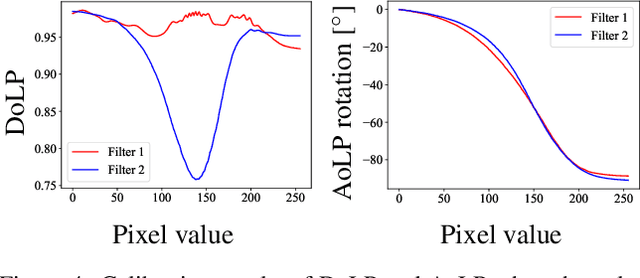

Can we capture shape and reflectance in stealth? Such capability would be valuable for many application domains in vision, xR, robotics, and HCI. We introduce Structured Polarization, the first depth and reflectance sensing method using patterns of polarized light (SPIDeRS). The key idea is to modulate the angle of linear polarization (AoLP) of projected light at each pixel. The use of polarization makes it invisible and lets us recover not only depth but also directly surface normals and even reflectance. We implement SPIDeRS with a liquid crystal spatial light modulator (SLM) and a polarimetric camera. We derive a novel method for robustly extracting the projected structured polarization pattern from the polarimetric object appearance. We evaluate the effectiveness of SPIDeRS by applying it to a number of real-world objects. The results show that our method successfully reconstructs object shapes of various materials and is robust to diffuse reflection and ambient light. We also demonstrate relighting using recovered surface normals and reflectance. We believe SPIDeRS opens a new avenue of polarization use in visual sensing.
DeepShaRM: Multi-View Shape and Reflectance Map Recovery Under Unknown Lighting
Oct 26, 2023



Geometry reconstruction of textureless, non-Lambertian objects under unknown natural illumination (i.e., in the wild) remains challenging as correspondences cannot be established and the reflectance cannot be expressed in simple analytical forms. We derive a novel multi-view method, DeepShaRM, that achieves state-of-the-art accuracy on this challenging task. Unlike past methods that formulate this as inverse-rendering, i.e., estimation of reflectance, illumination, and geometry from images, our key idea is to realize that reflectance and illumination need not be disentangled and instead estimated as a compound reflectance map. We introduce a novel deep reflectance map estimation network that recovers the camera-view reflectance maps from the surface normals of the current geometry estimate and the input multi-view images. The network also explicitly estimates per-pixel confidence scores to handle global light transport effects. A deep shape-from-shading network then updates the geometry estimate expressed with a signed distance function using the recovered reflectance maps. By alternating between these two, and, most important, by bypassing the ill-posed problem of reflectance and illumination decomposition, the method accurately recovers object geometry in these challenging settings. Extensive experiments on both synthetic and real-world data clearly demonstrate its state-of-the-art accuracy.
DeePoint: Pointing Recognition and Direction Estimation From A Fixed View
Apr 14, 2023In this paper, we realize automatic visual recognition and direction estimation of pointing. We introduce the first neural pointing understanding method based on two key contributions. The first is the introduction of a first-of-its-kind large-scale dataset for pointing recognition and direction estimation, which we refer to as the DP Dataset. DP Dataset consists of more than 2 million frames of over 33 people pointing in various styles annotated for each frame with pointing timings and 3D directions. The second is DeePoint, a novel deep network model for joint recognition and 3D direction estimation of pointing. DeePoint is a Transformer-based network which fully leverages the spatio-temporal coordination of the body parts, not just the hands. Through extensive experiments, we demonstrate the accuracy and efficiency of DeePoint. We believe DP Dataset and DeePoint will serve as a sound foundation for visual human intention understanding.
Fooling Polarization-based Vision using Locally Controllable Polarizing Projection
Mar 31, 2023



Polarization is a fundamental property of light that encodes abundant information regarding surface shape, material, illumination and viewing geometry. The computer vision community has witnessed a blossom of polarization-based vision applications, such as reflection removal, shape-from-polarization, transparent object segmentation and color constancy, partially due to the emergence of single-chip mono/color polarization sensors that make polarization data acquisition easier than ever. However, is polarization-based vision vulnerable to adversarial attacks? If so, is that possible to realize these adversarial attacks in the physical world, without being perceived by human eyes? In this paper, we warn the community of the vulnerability of polarization-based vision, which can be more serious than RGB-based vision. By adapting a commercial LCD projector, we achieve locally controllable polarizing projection, which is successfully utilized to fool state-of-the-art polarization-based vision algorithms for glass segmentation and color constancy. Compared with existing physical attacks on RGB-based vision, which always suffer from the trade-off between attack efficacy and eye conceivability, the adversarial attackers based on polarizing projection are contact-free and visually imperceptible, since naked human eyes can rarely perceive the difference of viciously manipulated polarizing light and ordinary illumination. This poses unprecedented risks on polarization-based vision, both in the monochromatic and trichromatic domain, for which due attentions should be paid and counter measures be considered.
TransPoser: Transformer as an Optimizer for Joint Object Shape and Pose Estimation
Mar 23, 2023



We propose a novel method for joint estimation of shape and pose of rigid objects from their sequentially observed RGB-D images. In sharp contrast to past approaches that rely on complex non-linear optimization, we propose to formulate it as a neural optimization that learns to efficiently estimate the shape and pose. We introduce Deep Directional Distance Function (DeepDDF), a neural network that directly outputs the depth image of an object given the camera viewpoint and viewing direction, for efficient error computation in 2D image space. We formulate the joint estimation itself as a Transformer which we refer to as TransPoser. We fully leverage the tokenization and multi-head attention to sequentially process the growing set of observations and to efficiently update the shape and pose with a learned momentum, respectively. Experimental results on synthetic and real data show that DeepDDF achieves high accuracy as a category-level object shape representation and TransPoser achieves state-of-the-art accuracy efficiently for joint shape and pose estimation.
InCrowdFormer: On-Ground Pedestrian World Model From Egocentric Views
Mar 16, 2023We introduce an on-ground Pedestrian World Model, a computational model that can predict how pedestrians move around an observer in the crowd on the ground plane, but from just the egocentric-views of the observer. Our model, InCrowdFormer, fully leverages the Transformer architecture by modeling pedestrian interaction and egocentric to top-down view transformation with attention, and autoregressively predicts on-ground positions of a variable number of people with an encoder-decoder architecture. We encode the uncertainties arising from unknown pedestrian heights with latent codes to predict the posterior distributions of pedestrian positions. We validate the effectiveness of InCrowdFormer on a novel prediction benchmark of real movements. The results show that InCrowdFormer accurately predicts the future coordination of pedestrians. To the best of our knowledge, InCrowdFormer is the first-of-its-kind pedestrian world model which we believe will benefit a wide range of egocentric-view applications including crowd navigation, tracking, and synthesis.