 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetailed Geometry and Appearance from Opportunistic Motion
Mar 27, 2026Reconstructing 3D geometry and appearance from a sparse set of fixed cameras is a foundational task with broad applications, yet it remains fundamentally constrained by the limited viewpoints. We show that this bound can be broken by exploiting opportunistic object motion: as a person manipulates an object~(e.g., moving a chair or lifting a mug), the static cameras effectively ``orbit'' the object in its local coordinate frame, providing additional virtual viewpoints. Harnessing this object motion, however, poses two challenges: the tight coupling of object pose and geometry estimation and the complex appearance variations of a moving object under static illumination. We address these by formulating a joint pose and shape optimization using 2D Gaussian splatting with alternating minimization of 6DoF trajectories and primitive parameters, and by introducing a novel appearance model that factorizes diffuse and specular components with reflected directional probing within the spherical harmonics space. Extensive experiments on synthetic and real-world datasets with extremely sparse viewpoints demonstrate that our method recovers significantly more accurate geometry and appearance than state-of-the-art baselines.
Restoration-Guided Kuzushiji Character Recognition Framework under Seal Interference
Feb 22, 2026Kuzushiji was one of the most popular writing styles in pre-modern Japan and was widely used in both personal letters and official documents. However, due to its highly cursive forms and extensive glyph variations, most modern Japanese readers cannot directly interpret Kuzushiji characters. Therefore, recent research has focused on developing automated Kuzushiji character recognition methods, which have achieved satisfactory performance on relatively clean Kuzushiji document images. However, existing methods struggle to maintain recognition accuracy under seal interference (e.g., when seals overlap characters), despite the frequent occurrence of seals in pre-modern Japanese documents. To address this challenge, we propose a three-stage restoration-guided Kuzushiji character recognition (RG-KCR) framework specifically designed to mitigate seal interference. We construct datasets for evaluating Kuzushiji character detection (Stage 1) and classification (Stage 3). Experimental results show that the YOLOv12-medium model achieves a precision of 98.0% and a recall of 93.3% on the constructed test set. We quantitatively evaluate the restoration performance of Stage 2 using PSNR and SSIM. In addition, we conduct an ablation study to demonstrate that Stage 2 improves the Top-1 accuracy of Metom, a Vision Transformer (ViT)-based Kuzushiji classifier employed in Stage 3, from 93.45% to 95.33%. The implementation code of this work is available at https://ruiyangju.github.io/RG-KCR.
M-PhyGs: Multi-Material Object Dynamics from Video
Dec 18, 2025Knowledge of the physical material properties governing the dynamics of a real-world object becomes necessary to accurately anticipate its response to unseen interactions. Existing methods for estimating such physical material parameters from visual data assume homogeneous single-material objects, pre-learned dynamics, or simplistic topologies. Real-world objects, however, are often complex in material composition and geometry lying outside the realm of these assumptions. In this paper, we particularly focus on flowers as a representative common object. We introduce Multi-material Physical Gaussians (M-PhyGs) to estimate the material composition and parameters of such multi-material complex natural objects from video. From a short video captured in a natural setting, M-PhyGs jointly segments the object into similar materials and recovers their continuum mechanical parameters while accounting for gravity. M-PhyGs achieves this efficiently with newly introduced cascaded 3D and 2D losses, and by leveraging temporal mini-batching. We introduce a dataset, Phlowers, of people interacting with flowers as a novel platform to evaluate the accuracy of this challenging task of multi-material physical parameter estimation. Experimental results on Phlowers dataset demonstrate the accuracy and effectiveness of M-PhyGs and its components.
DKDS: A Benchmark Dataset of Degraded Kuzushiji Documents with Seals for Detection and Binarization
Nov 12, 2025Kuzushiji, a pre-modern Japanese cursive script, can currently be read and understood by only a few thousand trained experts in Japan. With the rapid development of deep learning, researchers have begun applying Optical Character Recognition (OCR) techniques to transcribe Kuzushiji into modern Japanese. Although existing OCR methods perform well on clean pre-modern Japanese documents written in Kuzushiji, they often fail to consider various types of noise, such as document degradation and seals, which significantly affect recognition accuracy. To the best of our knowledge, no existing dataset specifically addresses these challenges. To address this gap, we introduce the Degraded Kuzushiji Documents with Seals (DKDS) dataset as a new benchmark for related tasks. We describe the dataset construction process, which required the assistance of a trained Kuzushiji expert, and define two benchmark tracks: (1) text and seal detection and (2) document binarization. For the text and seal detection track, we provide baseline results using multiple versions of the You Only Look Once (YOLO) models for detecting Kuzushiji characters and seals. For the document binarization track, we present baseline results from traditional binarization algorithms, traditional algorithms combined with K-means clustering, and Generative Adversarial Network (GAN)-based methods. The DKDS dataset and the implementation code for baseline methods are available at https://ruiyangju.github.io/DKDS.
MAtCha Gaussians: Atlas of Charts for High-Quality Geometry and Photorealism From Sparse Views
Dec 09, 2024



We present a novel appearance model that simultaneously realizes explicit high-quality 3D surface mesh recovery and photorealistic novel view synthesis from sparse view samples. Our key idea is to model the underlying scene geometry Mesh as an Atlas of Charts which we render with 2D Gaussian surfels (MAtCha Gaussians). MAtCha distills high-frequency scene surface details from an off-the-shelf monocular depth estimator and refines it through Gaussian surfel rendering. The Gaussian surfels are attached to the charts on the fly, satisfying photorealism of neural volumetric rendering and crisp geometry of a mesh model, i.e., two seemingly contradicting goals in a single model. At the core of MAtCha lies a novel neural deformation model and a structure loss that preserve the fine surface details distilled from learned monocular depths while addressing their fundamental scale ambiguities. Results of extensive experimental validation demonstrate MAtCha's state-of-the-art quality of surface reconstruction and photorealism on-par with top contenders but with dramatic reduction in the number of input views and computational time. We believe MAtCha will serve as a foundational tool for any visual application in vision, graphics, and robotics that require explicit geometry in addition to photorealism. Our project page is the following: https://anttwo.github.io/matcha/
Correspondences of the Third Kind: Camera Pose Estimation from Object Reflection
Dec 07, 2023Computer vision has long relied on two kinds of correspondences: pixel correspondences in images and 3D correspondences on object surfaces. Is there another kind, and if there is, what can they do for us? In this paper, we introduce correspondences of the third kind we call reflection correspondences and show that they can help estimate camera pose by just looking at objects without relying on the background. Reflection correspondences are point correspondences in the reflected world, i.e., the scene reflected by the object surface. The object geometry and reflectance alters the scene geometrically and radiometrically, respectively, causing incorrect pixel correspondences. Geometry recovered from each image is also hampered by distortions, namely generalized bas-relief ambiguity, leading to erroneous 3D correspondences. We show that reflection correspondences can resolve the ambiguities arising from these distortions. We introduce a neural correspondence estimator and a RANSAC algorithm that fully leverages all three kinds of correspondences for robust and accurate joint camera pose and object shape estimation just from the object appearance. The method expands the horizon of numerous downstream tasks, including camera pose estimation for appearance modeling (e.g., NeRF) and motion estimation of reflective objects (e.g., cars on the road), to name a few, as it relieves the requirement of overlapping background.
DeepShaRM: Multi-View Shape and Reflectance Map Recovery Under Unknown Lighting
Oct 26, 2023



Geometry reconstruction of textureless, non-Lambertian objects under unknown natural illumination (i.e., in the wild) remains challenging as correspondences cannot be established and the reflectance cannot be expressed in simple analytical forms. We derive a novel multi-view method, DeepShaRM, that achieves state-of-the-art accuracy on this challenging task. Unlike past methods that formulate this as inverse-rendering, i.e., estimation of reflectance, illumination, and geometry from images, our key idea is to realize that reflectance and illumination need not be disentangled and instead estimated as a compound reflectance map. We introduce a novel deep reflectance map estimation network that recovers the camera-view reflectance maps from the surface normals of the current geometry estimate and the input multi-view images. The network also explicitly estimates per-pixel confidence scores to handle global light transport effects. A deep shape-from-shading network then updates the geometry estimate expressed with a signed distance function using the recovered reflectance maps. By alternating between these two, and, most important, by bypassing the ill-posed problem of reflectance and illumination decomposition, the method accurately recovers object geometry in these challenging settings. Extensive experiments on both synthetic and real-world data clearly demonstrate its state-of-the-art accuracy.
nLMVS-Net: Deep Non-Lambertian Multi-View Stereo
Jul 25, 2022
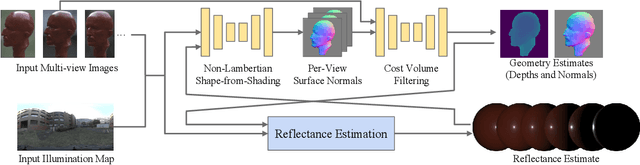

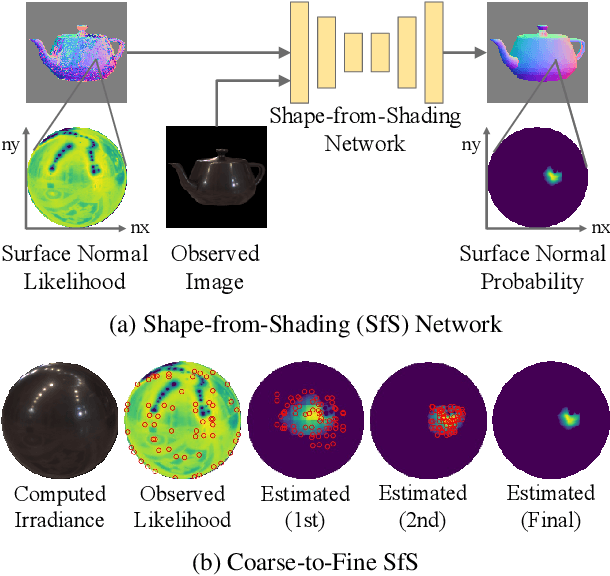
We introduce a novel multi-view stereo (MVS) method that can simultaneously recover not just per-pixel depth but also surface normals, together with the reflectance of textureless, complex non-Lambertian surfaces captured under known but natural illumination. Our key idea is to formulate MVS as an end-to-end learnable network, which we refer to as nLMVS-Net, that seamlessly integrates radiometric cues to leverage surface normals as view-independent surface features for learned cost volume construction and filtering. It first estimates surface normals as pixel-wise probability densities for each view with a novel shape-from-shading network. These per-pixel surface normal densities and the input multi-view images are then input to a novel cost volume filtering network that learns to recover per-pixel depth and surface normal. The reflectance is also explicitly estimated by alternating with geometry reconstruction. Extensive quantitative evaluations on newly established synthetic and real-world datasets show that nLMVS-Net can robustly and accurately recover the shape and reflectance of complex objects in natural settings.
3D-GMNet: Learning to Estimate 3D Shape from A Single Image As A Gaussian Mixture
Dec 10, 2019

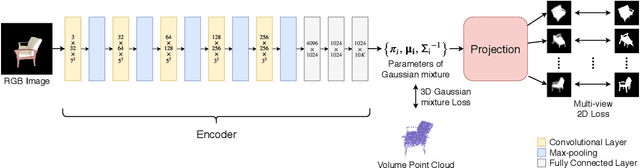

In this paper, we introduce 3D-GMNet, a deep neural network for single-image 3D shape recovery. As the name suggests, 3D-GMNet recovers 3D shape as a Gaussian mixture model. In contrast to voxels, point clouds, or meshes, a Gaussian mixture representation requires a much smaller footprint for representing 3D shapes and, at the same time, offers a number of additional advantages including instant pose estimation, automatic level-of-detail computation, and a distance measure. The proposed 3D-GMNet is trained end-to-end with single input images and corresponding 3D models by using two novel loss functions: a 3D Gaussian mixture loss and a multi-view 2D loss. The first maximizes the likelihood of the Gaussian mixture shape representation by considering the target point cloud as samples from the true distribution, and the latter improves the consistency between the input silhouette and the projection of the Gaussian mixture shape model. Extensive quantitative evaluations with synthesized and real images demonstrate the effectiveness of the proposed method.