 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraRA: Trajectory-level Recognition Aggregation for Video Text Spotting in Urban Surveillance
Jun 05, 2026Video Text Spotting (VTS) is essential for urban surveillance and intelligent transportation systems, enabling automated reading of street signs, vehicle markings, and scene text in video streams. However, reliable recognition remains challenging due to dynamic video factors common in surveillance scenarios, including motion blur, occlusion, and scale variation, which degrade frame-level recognition. Existing VTS methods typically perform recognition independently on each frame, leading to inconsistent and inaccurate results across sequences. To address these limitations, we propose TraRA (Trajectory-level Recognition Aggregation for VTS), a plug-and-play method that performs trajectory-level text recognition by leveraging temporal and multimodal consistency. TraRA integrates two key modules: (1) the Temporal Clustering and (2) the Vision-Language Aggregation. The former refines noisy trajectories by grouping temporally and visually coherent text instances, while the latter employs a Low-Rank Adaptation-enhanced Vision-Language model to fuse visual cues with linguistic context across frames. By aggregating information over entire text trajectories, TraRA achieves robust text recognition even under challenging surveillance conditions. Extensive experiments on four public benchmarks, including road and urban scene datasets (RoadText, BOVText, ArTVideo, and ICDAR15), demonstrate that TraRA consistently improves tracking and recognition performance over state-of-the-art VTS methods. The source code is available at https://github.com/trid2912/TraRA.
ForestMamba: Sparse Mamba with Geometry-guided Queries for 3D Forest Point Cloud Segmentation
Jun 01, 2026AI-based semantic and instance segmentation of terrestrial and drone LiDAR point clouds is emerging as a transformative approach for converting the complex 3D structure of forests into actionable information for forest monitoring and biodiversity assessment. However, forest LiDAR scenes remain highly challenging due to their large data volumes, irregular sampling density, overlapping and complex canopy structure, and geographic variability. Existing methods based on sparse convolutions or Transformers achieve promising results, but suffer from two key limitations: Quadratic complexity of attention scales poorly to large forest scenes, and Generic context modeling does not exploit forest structural priors, limiting tree separation in complex regions. To address these challenges, we propose ForestMamba, a structure-aware method that incorporates forest-specific priors into feature encoding, query generation, and query refinement, while replacing quadratic attention with linear-time state-space modeling. First, we introduce a sparse encoder with vertical-priority slab serialization that organizes sparse voxels into vertically coherent sequences for efficient long-range context modeling. Second, we propose a geometry-guided query initialization strategy based on an on-the-fly multi-scale Canopy Height Model (CHM), where canopy maxima provide ecologically meaningful query seeds, supplemented by Farthest Point Sampling (FPS) to cover understory trees. Third, we design a Mamba-based query decoder that combines local kNN voxel aggregation with a spatial dual-path Mamba for query refinement with linear computational complexity. Extensive experiments across seven forest regions demonstrate that ForestMamba consistently outperforms existing baselines in both segmentation tasks, while achieving 3 times faster inference and 2.3 times lower GPU memory than Transformer-based methods.
REACH: Hand Pose Estimation from Room Corners
May 21, 2026We introduce a novel 3D hand pose estimator that can accurately recover the shape and pose of people's hands in a room from afar, typically from fixed cameras at room corners, in extremely low-resolution and frequently occluded views. Our key idea is to fully leverage hand-body coordination, its temporal progression, and multiview observations. We achieve this with a novel Transformer-based model, in which hand and body configurations are modeled through correlations between their visual features expressed as per-view tokens, and their temporal coordination is exploited in an autoregressive manner. We introduce a novel dataset, which we refer to as REACH, Room-Environment dataset Annotated with Chest cameras for Hand pose estimation, to train and test our method. REACH is a first-of-its-kind large-scale hand pose dataset that captures accurate hand movements of 50 participants across a wide variety of daily activities. In order to avoid interfering with natural movements while annotating the hands with accurate shape and pose, we leverage concealed chest cameras. Through extensive experiments, including comparative studies with existing methods, we show that our model, REACH-Net, achieves highly accurate 3D hand pose estimation from afar. These results broaden the horizon of 3D hand pose estimation, especially towards "in-the-wild" continuous human behavior analysis.
View-aware Cross-modal Distillation for Multi-view Action Recognition
Nov 17, 2025The widespread use of multi-sensor systems has increased research in multi-view action recognition. While existing approaches in multi-view setups with fully overlapping sensors benefit from consistent view coverage, partially overlapping settings where actions are visible in only a subset of views remain underexplored. This challenge becomes more severe in real-world scenarios, as many systems provide only limited input modalities and rely on sequence-level annotations instead of dense frame-level labels. In this study, we propose View-aware Cross-modal Knowledge Distillation (ViCoKD), a framework that distills knowledge from a fully supervised multi-modal teacher to a modality- and annotation-limited student. ViCoKD employs a cross-modal adapter with cross-modal attention, allowing the student to exploit multi-modal correlations while operating with incomplete modalities. Moreover, we propose a View-aware Consistency module to address view misalignment, where the same action may appear differently or only partially across viewpoints. It enforces prediction alignment when the action is co-visible across views, guided by human-detection masks and confidence-weighted Jensen-Shannon divergence between their predicted class distributions. Experiments on the real-world MultiSensor-Home dataset show that ViCoKD consistently outperforms competitive distillation methods across multiple backbones and environments, delivering significant gains and surpassing the teacher model under limited conditions.
MultiTSF: Transformer-based Sensor Fusion for Human-Centric Multi-view and Multi-modal Action Recognition
Apr 03, 2025

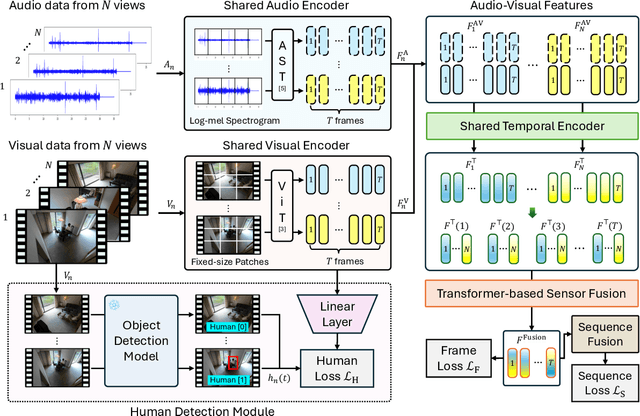
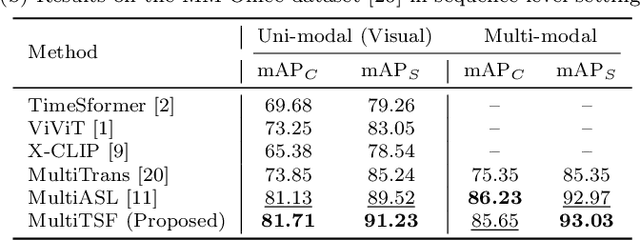
Action recognition from multi-modal and multi-view observations holds significant potential for applications in surveillance, robotics, and smart environments. However, existing methods often fall short of addressing real-world challenges such as diverse environmental conditions, strict sensor synchronization, and the need for fine-grained annotations. In this study, we propose the Multi-modal Multi-view Transformer-based Sensor Fusion (MultiTSF). The proposed method leverages a Transformer-based to dynamically model inter-view relationships and capture temporal dependencies across multiple views. Additionally, we introduce a Human Detection Module to generate pseudo-ground-truth labels, enabling the model to prioritize frames containing human activity and enhance spatial feature learning. Comprehensive experiments conducted on our in-house MultiSensor-Home dataset and the existing MM-Office dataset demonstrate that MultiTSF outperforms state-of-the-art methods in both video sequence-level and frame-level action recognition settings.
MultiSensor-Home: A Wide-area Multi-modal Multi-view Dataset for Action Recognition and Transformer-based Sensor Fusion
Apr 03, 2025
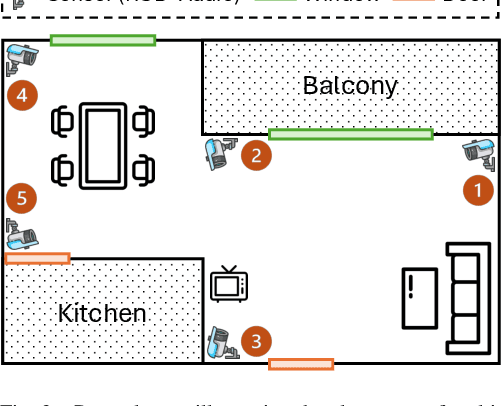

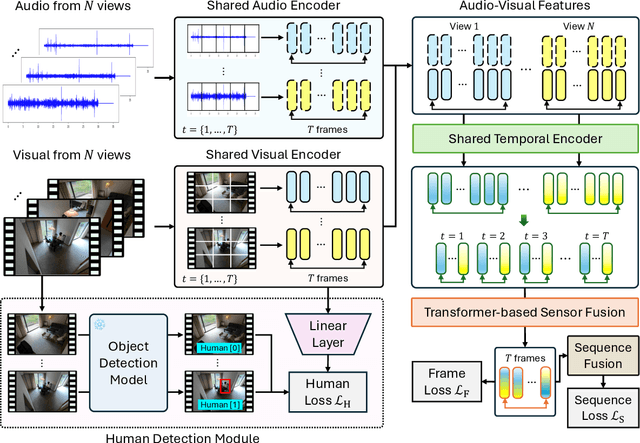
Multi-modal multi-view action recognition is a rapidly growing field in computer vision, offering significant potential for applications in surveillance. However, current datasets often fail to address real-world challenges such as wide-area environmental conditions, asynchronous data streams, and the lack of frame-level annotations. Furthermore, existing methods face difficulties in effectively modeling inter-view relationships and enhancing spatial feature learning. In this study, we propose the Multi-modal Multi-view Transformer-based Sensor Fusion (MultiTSF) method and introduce the MultiSensor-Home dataset, a novel benchmark designed for comprehensive action recognition in home environments. The MultiSensor-Home dataset features untrimmed videos captured by distributed sensors, providing high-resolution RGB and audio data along with detailed multi-view frame-level action labels. The proposed MultiTSF method leverages a Transformer-based fusion mechanism to dynamically model inter-view relationships. Furthermore, the method also integrates a external human detection module to enhance spatial feature learning. Experiments on MultiSensor-Home and MM-Office datasets demonstrate the superiority of MultiTSF over the state-of-the-art methods. The quantitative and qualitative results highlight the effectiveness of the proposed method in advancing real-world multi-modal multi-view action recognition.
Action Selection Learning for Multi-label Multi-view Action Recognition
Oct 04, 2024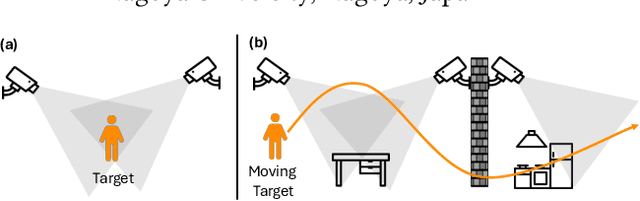
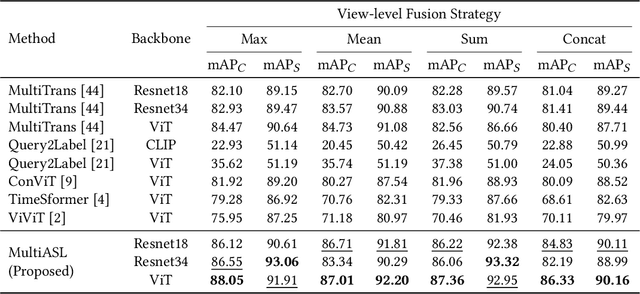
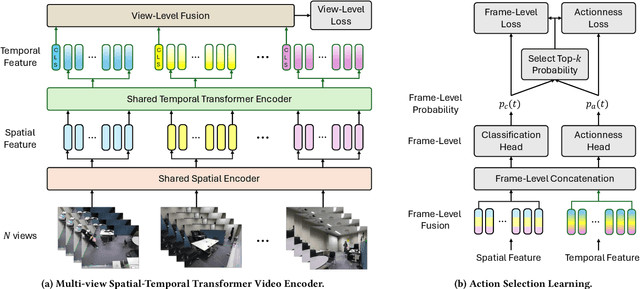

Multi-label multi-view action recognition aims to recognize multiple concurrent or sequential actions from untrimmed videos captured by multiple cameras. Existing work has focused on multi-view action recognition in a narrow area with strong labels available, where the onset and offset of each action are labeled at the frame-level. This study focuses on real-world scenarios where cameras are distributed to capture a wide-range area with only weak labels available at the video-level. We propose the method named MultiASL (Multi-view Action Selection Learning), which leverages action selection learning to enhance view fusion by selecting the most useful information from different viewpoints. The proposed method includes a Multi-view Spatial-Temporal Transformer video encoder to extract spatial and temporal features from multi-viewpoint videos. Action Selection Learning is employed at the frame-level, using pseudo ground-truth obtained from weak labels at the video-level, to identify the most relevant frames for action recognition. Experiments in a real-world office environment using the MM-Office dataset demonstrate the superior performance of the proposed method compared to existing methods.
Tracking Small Birds by Detection Candidate Region Filtering and Detection History-aware Association
May 27, 2024



This paper focuses on tracking birds that appear small in a panoramic video. When the size of the tracked object is small in the image (small object tracking) and move quickly, object detection and association suffers. To address these problems, we propose Adaptive Slicing Aided Hyper Inference (Adaptive SAHI), which reduces the candidate regions to apply detection, and Detection History-aware Similarity Criterion (DHSC), which accurately associates objects in consecutive frames based on the detection history. Experiments on the NUBird2022 dataset verifies the effectiveness of the proposed method by showing improvements in both accuracy and speed.
One-Stage Open-Vocabulary Temporal Action Detection Leveraging Temporal Multi-scale and Action Label Features
Apr 30, 2024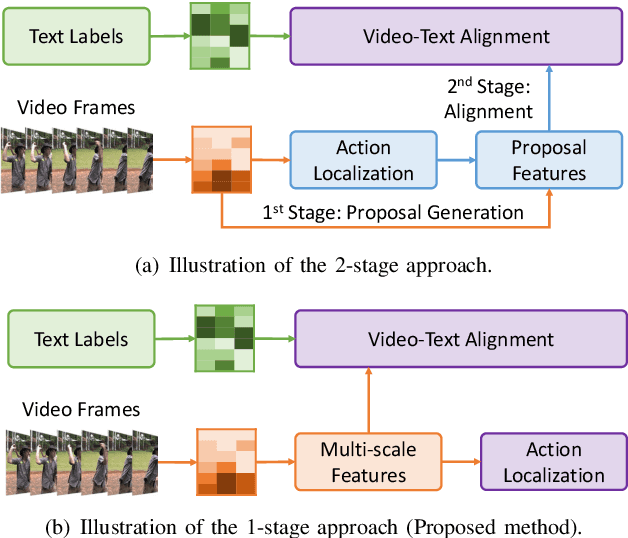
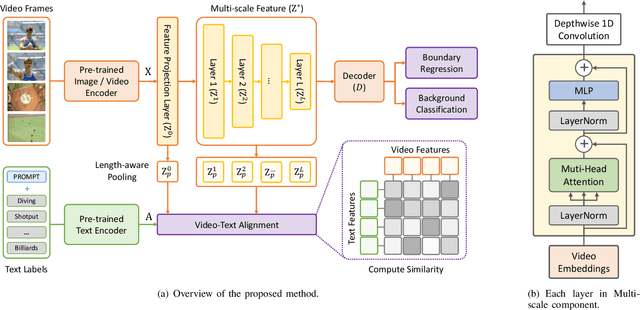
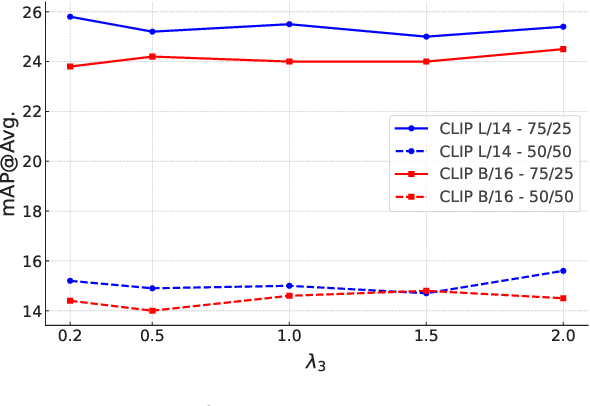
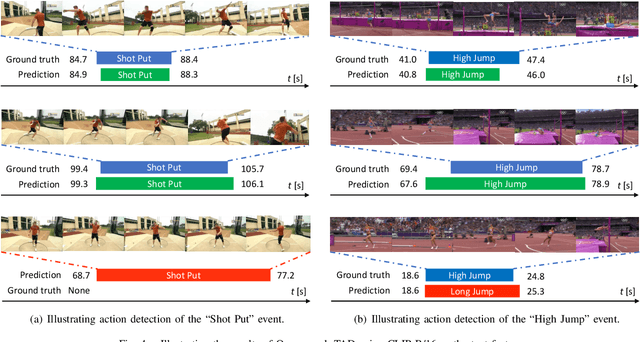
Open-vocabulary Temporal Action Detection (Open-vocab TAD) is an advanced video analysis approach that expands Closed-vocabulary Temporal Action Detection (Closed-vocab TAD) capabilities. Closed-vocab TAD is typically confined to localizing and classifying actions based on a predefined set of categories. In contrast, Open-vocab TAD goes further and is not limited to these predefined categories. This is particularly useful in real-world scenarios where the variety of actions in videos can be vast and not always predictable. The prevalent methods in Open-vocab TAD typically employ a 2-stage approach, which involves generating action proposals and then identifying those actions. However, errors made during the first stage can adversely affect the subsequent action identification accuracy. Additionally, existing studies face challenges in handling actions of different durations owing to the use of fixed temporal processing methods. Therefore, we propose a 1-stage approach consisting of two primary modules: Multi-scale Video Analysis (MVA) and Video-Text Alignment (VTA). The MVA module captures actions at varying temporal resolutions, overcoming the challenge of detecting actions with diverse durations. The VTA module leverages the synergy between visual and textual modalities to precisely align video segments with corresponding action labels, a critical step for accurate action identification in Open-vocab scenarios. Evaluations on widely recognized datasets THUMOS14 and ActivityNet-1.3, showed that the proposed method achieved superior results compared to the other methods in both Open-vocab and Closed-vocab settings. This serves as a strong demonstration of the effectiveness of the proposed method in the TAD task.
J-CRe3: A Japanese Conversation Dataset for Real-world Reference Resolution
Mar 28, 2024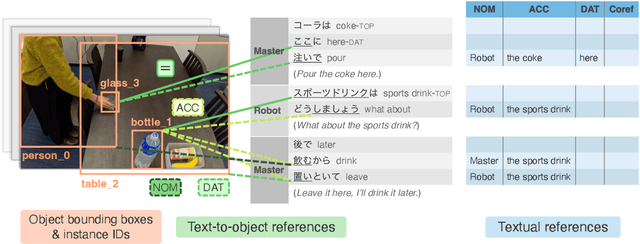
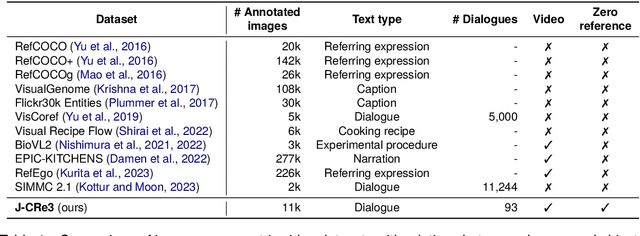

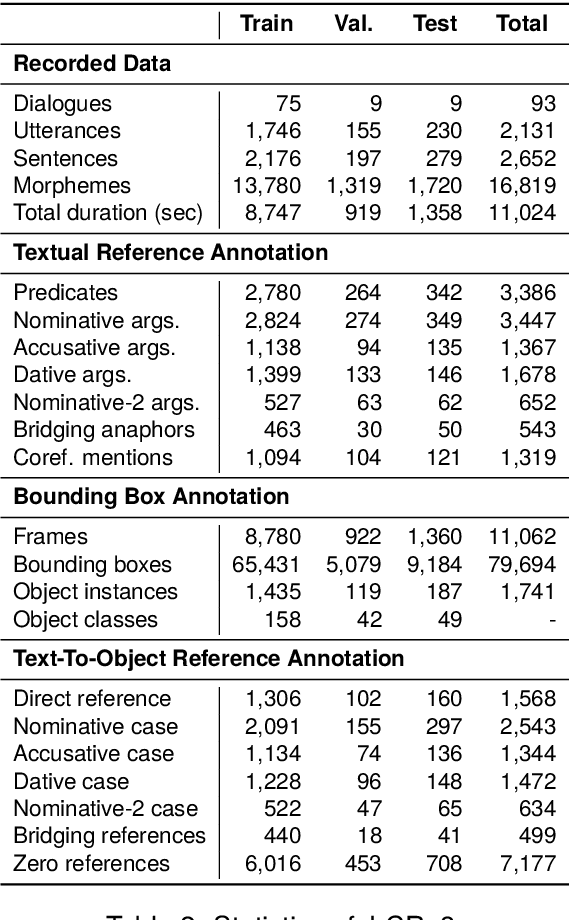
Understanding expressions that refer to the physical world is crucial for such human-assisting systems in the real world, as robots that must perform actions that are expected by users. In real-world reference resolution, a system must ground the verbal information that appears in user interactions to the visual information observed in egocentric views. To this end, we propose a multimodal reference resolution task and construct a Japanese Conversation dataset for Real-world Reference Resolution (J-CRe3). Our dataset contains egocentric video and dialogue audio of real-world conversations between two people acting as a master and an assistant robot at home. The dataset is annotated with crossmodal tags between phrases in the utterances and the object bounding boxes in the video frames. These tags include indirect reference relations, such as predicate-argument structures and bridging references as well as direct reference relations. We also constructed an experimental model and clarified the challenges in multimodal reference resolution tasks.