 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiSensor-Home: A Wide-area Multi-modal Multi-view Dataset for Action Recognition and Transformer-based Sensor Fusion
Paper and Code
Apr 03, 2025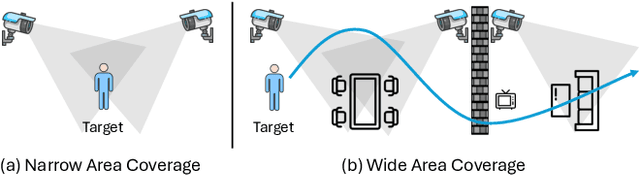
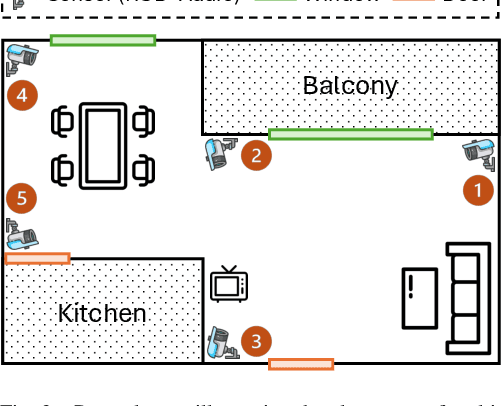

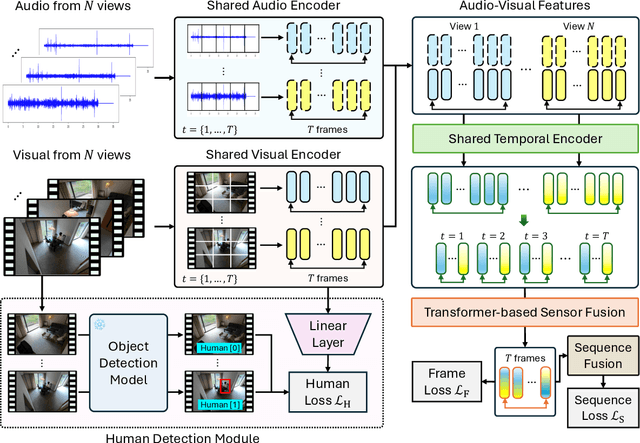
Multi-modal multi-view action recognition is a rapidly growing field in computer vision, offering significant potential for applications in surveillance. However, current datasets often fail to address real-world challenges such as wide-area environmental conditions, asynchronous data streams, and the lack of frame-level annotations. Furthermore, existing methods face difficulties in effectively modeling inter-view relationships and enhancing spatial feature learning. In this study, we propose the Multi-modal Multi-view Transformer-based Sensor Fusion (MultiTSF) method and introduce the MultiSensor-Home dataset, a novel benchmark designed for comprehensive action recognition in home environments. The MultiSensor-Home dataset features untrimmed videos captured by distributed sensors, providing high-resolution RGB and audio data along with detailed multi-view frame-level action labels. The proposed MultiTSF method leverages a Transformer-based fusion mechanism to dynamically model inter-view relationships. Furthermore, the method also integrates a external human detection module to enhance spatial feature learning. Experiments on MultiSensor-Home and MM-Office datasets demonstrate the superiority of MultiTSF over the state-of-the-art methods. The quantitative and qualitative results highlight the effectiveness of the proposed method in advancing real-world multi-modal multi-view action recognition.