 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-aware Cross-modal Distillation for Multi-view Action Recognition
Nov 17, 2025The widespread use of multi-sensor systems has increased research in multi-view action recognition. While existing approaches in multi-view setups with fully overlapping sensors benefit from consistent view coverage, partially overlapping settings where actions are visible in only a subset of views remain underexplored. This challenge becomes more severe in real-world scenarios, as many systems provide only limited input modalities and rely on sequence-level annotations instead of dense frame-level labels. In this study, we propose View-aware Cross-modal Knowledge Distillation (ViCoKD), a framework that distills knowledge from a fully supervised multi-modal teacher to a modality- and annotation-limited student. ViCoKD employs a cross-modal adapter with cross-modal attention, allowing the student to exploit multi-modal correlations while operating with incomplete modalities. Moreover, we propose a View-aware Consistency module to address view misalignment, where the same action may appear differently or only partially across viewpoints. It enforces prediction alignment when the action is co-visible across views, guided by human-detection masks and confidence-weighted Jensen-Shannon divergence between their predicted class distributions. Experiments on the real-world MultiSensor-Home dataset show that ViCoKD consistently outperforms competitive distillation methods across multiple backbones and environments, delivering significant gains and surpassing the teacher model under limited conditions.
PADM: A Physics-aware Diffusion Model for Attenuation Correction
Nov 10, 2025Attenuation artifacts remain a significant challenge in cardiac Myocardial Perfusion Imaging (MPI) using Single-Photon Emission Computed Tomography (SPECT), often compromising diagnostic accuracy and reducing clinical interpretability. While hybrid SPECT/CT systems mitigate these artifacts through CT-derived attenuation maps, their high cost, limited accessibility, and added radiation exposure hinder widespread clinical adoption. In this study, we propose a novel CT-free solution to attenuation correction in cardiac SPECT. Specifically, we introduce Physics-aware Attenuation Correction Diffusion Model (PADM), a diffusion-based generative method that incorporates explicit physics priors via a teacher--student distillation mechanism. This approach enables attenuation artifact correction using only Non-Attenuation-Corrected (NAC) input, while still benefiting from physics-informed supervision during training. To support this work, we also introduce CardiAC, a comprehensive dataset comprising 424 patient studies with paired NAC and Attenuation-Corrected (AC) reconstructions, alongside high-resolution CT-based attenuation maps. Extensive experiments demonstrate that PADM outperforms state-of-the-art generative models, delivering superior reconstruction fidelity across both quantitative metrics and visual assessment.
MultiSensor-Home: A Wide-area Multi-modal Multi-view Dataset for Action Recognition and Transformer-based Sensor Fusion
Apr 03, 2025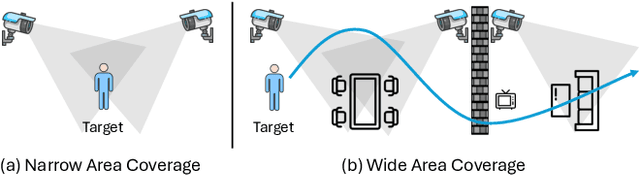
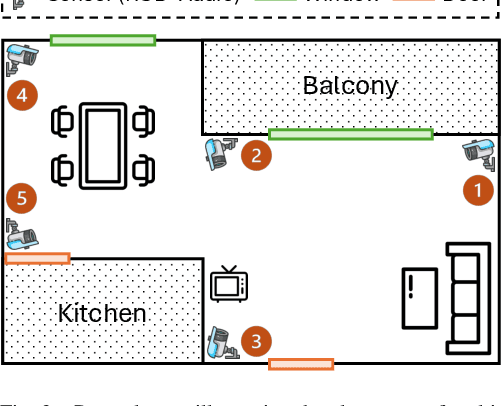

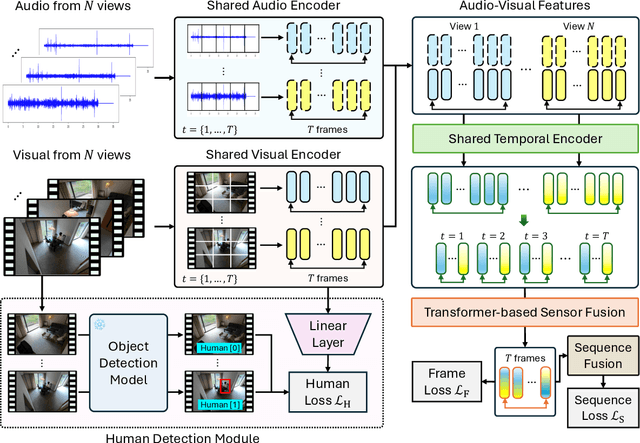
Multi-modal multi-view action recognition is a rapidly growing field in computer vision, offering significant potential for applications in surveillance. However, current datasets often fail to address real-world challenges such as wide-area environmental conditions, asynchronous data streams, and the lack of frame-level annotations. Furthermore, existing methods face difficulties in effectively modeling inter-view relationships and enhancing spatial feature learning. In this study, we propose the Multi-modal Multi-view Transformer-based Sensor Fusion (MultiTSF) method and introduce the MultiSensor-Home dataset, a novel benchmark designed for comprehensive action recognition in home environments. The MultiSensor-Home dataset features untrimmed videos captured by distributed sensors, providing high-resolution RGB and audio data along with detailed multi-view frame-level action labels. The proposed MultiTSF method leverages a Transformer-based fusion mechanism to dynamically model inter-view relationships. Furthermore, the method also integrates a external human detection module to enhance spatial feature learning. Experiments on MultiSensor-Home and MM-Office datasets demonstrate the superiority of MultiTSF over the state-of-the-art methods. The quantitative and qualitative results highlight the effectiveness of the proposed method in advancing real-world multi-modal multi-view action recognition.
MultiTSF: Transformer-based Sensor Fusion for Human-Centric Multi-view and Multi-modal Action Recognition
Apr 03, 2025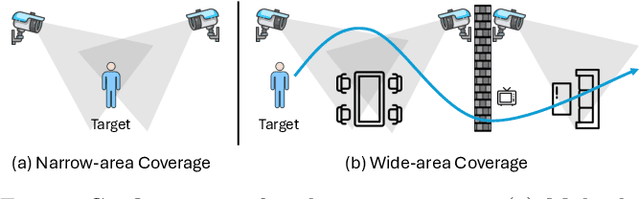

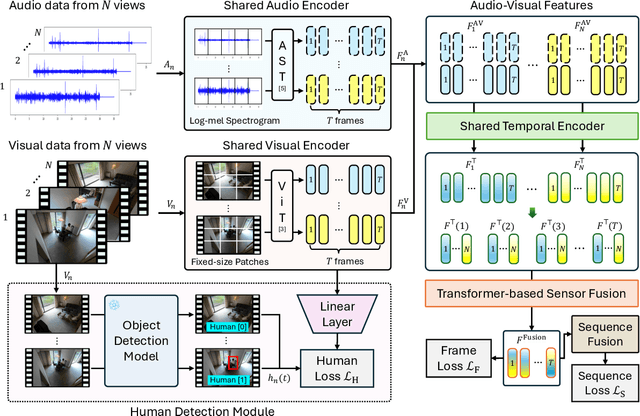
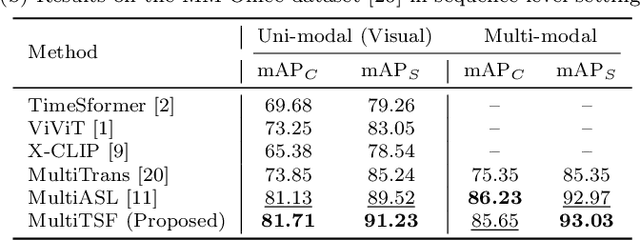
Action recognition from multi-modal and multi-view observations holds significant potential for applications in surveillance, robotics, and smart environments. However, existing methods often fall short of addressing real-world challenges such as diverse environmental conditions, strict sensor synchronization, and the need for fine-grained annotations. In this study, we propose the Multi-modal Multi-view Transformer-based Sensor Fusion (MultiTSF). The proposed method leverages a Transformer-based to dynamically model inter-view relationships and capture temporal dependencies across multiple views. Additionally, we introduce a Human Detection Module to generate pseudo-ground-truth labels, enabling the model to prioritize frames containing human activity and enhance spatial feature learning. Comprehensive experiments conducted on our in-house MultiSensor-Home dataset and the existing MM-Office dataset demonstrate that MultiTSF outperforms state-of-the-art methods in both video sequence-level and frame-level action recognition settings.
CT to PET Translation: A Large-scale Dataset and Domain-Knowledge-Guided Diffusion Approach
Oct 29, 2024



Positron Emission Tomography (PET) and Computed Tomography (CT) are essential for diagnosing, staging, and monitoring various diseases, particularly cancer. Despite their importance, the use of PET/CT systems is limited by the necessity for radioactive materials, the scarcity of PET scanners, and the high cost associated with PET imaging. In contrast, CT scanners are more widely available and significantly less expensive. In response to these challenges, our study addresses the issue of generating PET images from CT images, aiming to reduce both the medical examination cost and the associated health risks for patients. Our contributions are twofold: First, we introduce a conditional diffusion model named CPDM, which, to our knowledge, is one of the initial attempts to employ a diffusion model for translating from CT to PET images. Second, we provide the largest CT-PET dataset to date, comprising 2,028,628 paired CT-PET images, which facilitates the training and evaluation of CT-to-PET translation models. For the CPDM model, we incorporate domain knowledge to develop two conditional maps: the Attention map and the Attenuation map. The former helps the diffusion process focus on areas of interest, while the latter improves PET data correction and ensures accurate diagnostic information. Experimental evaluations across various benchmarks demonstrate that CPDM surpasses existing methods in generating high-quality PET images in terms of multiple metrics. The source code and data samples are available at https://github.com/thanhhff/CPDM.
FedMAC: Tackling Partial-Modality Missing in Federated Learning with Cross-Modal Aggregation and Contrastive Regularization
Oct 04, 2024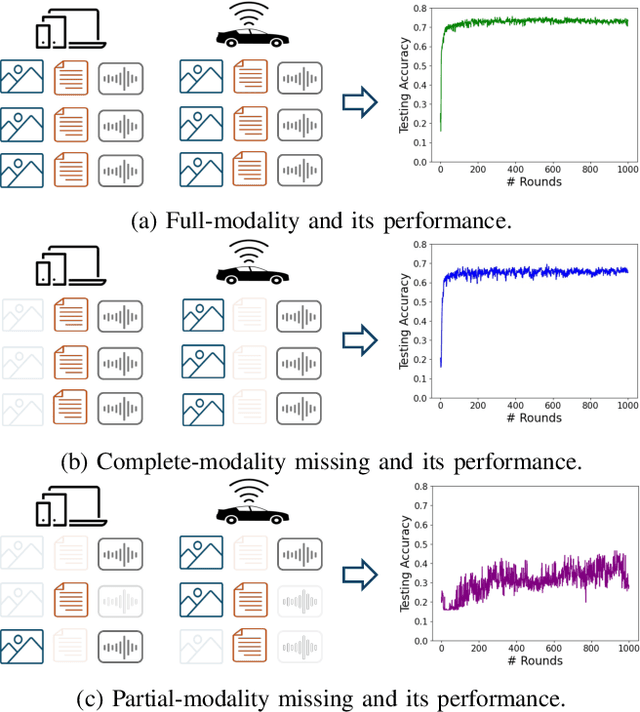
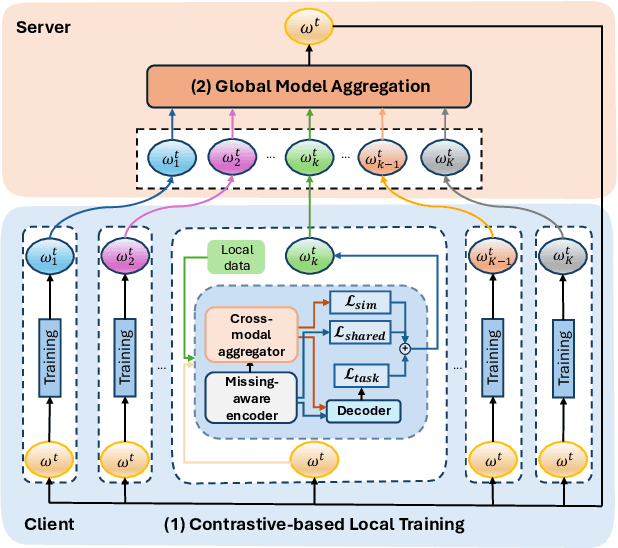
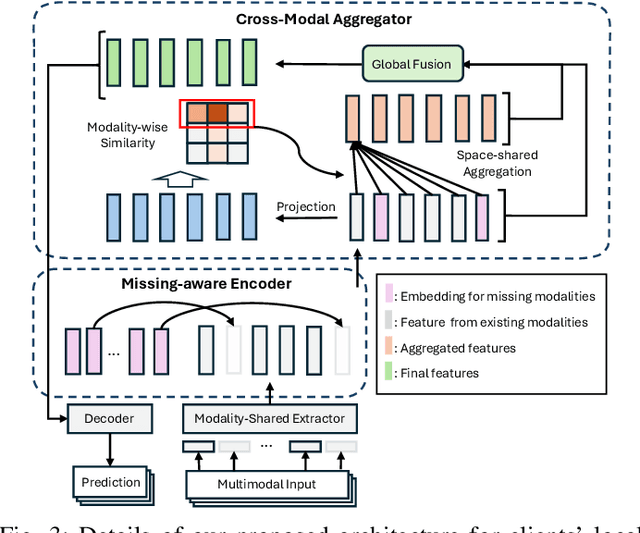
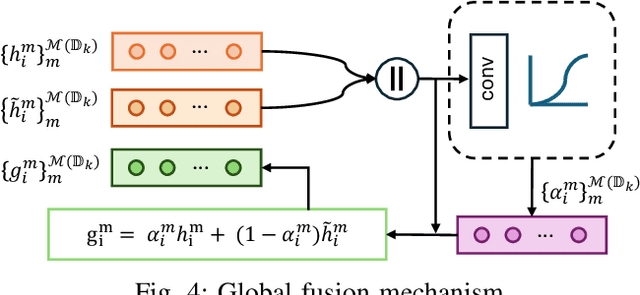
Federated Learning (FL) is a method for training machine learning models using distributed data sources. It ensures privacy by allowing clients to collaboratively learn a shared global model while storing their data locally. However, a significant challenge arises when dealing with missing modalities in clients' datasets, where certain features or modalities are unavailable or incomplete, leading to heterogeneous data distribution. While previous studies have addressed the issue of complete-modality missing, they fail to tackle partial-modality missing on account of severe heterogeneity among clients at an instance level, where the pattern of missing data can vary significantly from one sample to another. To tackle this challenge, this study proposes a novel framework named FedMAC, designed to address multi-modality missing under conditions of partial-modality missing in FL. Additionally, to avoid trivial aggregation of multi-modal features, we introduce contrastive-based regularization to impose additional constraints on the latent representation space. The experimental results demonstrate the effectiveness of FedMAC across various client configurations with statistical heterogeneity, outperforming baseline methods by up to 26% in severe missing scenarios, highlighting its potential as a solution for the challenge of partially missing modalities in federated systems.
FedCert: Federated Accuracy Certification
Oct 04, 2024



Federated Learning (FL) has emerged as a powerful paradigm for training machine learning models in a decentralized manner, preserving data privacy by keeping local data on clients. However, evaluating the robustness of these models against data perturbations on clients remains a significant challenge. Previous studies have assessed the effectiveness of models in centralized training based on certified accuracy, which guarantees that a certain percentage of the model's predictions will remain correct even if the input data is perturbed. However, the challenge of extending these evaluations to FL remains unresolved due to the unknown client's local data. To tackle this challenge, this study proposed a method named FedCert to take the first step toward evaluating the robustness of FL systems. The proposed method is designed to approximate the certified accuracy of a global model based on the certified accuracy and class distribution of each client. Additionally, considering the Non-Independent and Identically Distributed (Non-IID) nature of data in real-world scenarios, we introduce the client grouping algorithm to ensure reliable certified accuracy during the aggregation step of the approximation algorithm. Through theoretical analysis, we demonstrate the effectiveness of FedCert in assessing the robustness and reliability of FL systems. Moreover, experimental results on the CIFAR-10 and CIFAR-100 datasets under various scenarios show that FedCert consistently reduces the estimation error compared to baseline methods. This study offers a solution for evaluating the robustness of FL systems and lays the groundwork for future research to enhance the dependability of decentralized learning. The source code is available at https://github.com/thanhhff/FedCert/.
Action Selection Learning for Multi-label Multi-view Action Recognition
Oct 04, 2024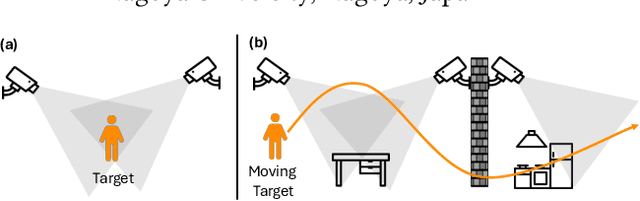
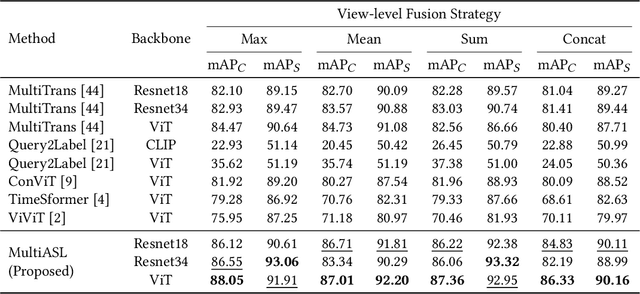
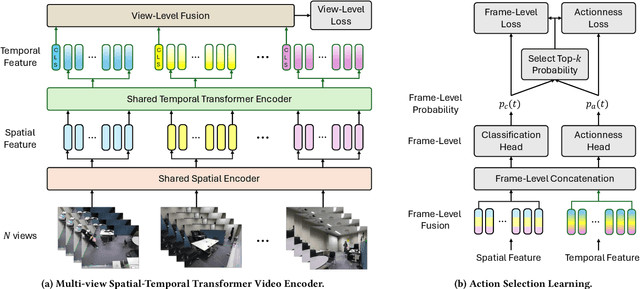

Multi-label multi-view action recognition aims to recognize multiple concurrent or sequential actions from untrimmed videos captured by multiple cameras. Existing work has focused on multi-view action recognition in a narrow area with strong labels available, where the onset and offset of each action are labeled at the frame-level. This study focuses on real-world scenarios where cameras are distributed to capture a wide-range area with only weak labels available at the video-level. We propose the method named MultiASL (Multi-view Action Selection Learning), which leverages action selection learning to enhance view fusion by selecting the most useful information from different viewpoints. The proposed method includes a Multi-view Spatial-Temporal Transformer video encoder to extract spatial and temporal features from multi-viewpoint videos. Action Selection Learning is employed at the frame-level, using pseudo ground-truth obtained from weak labels at the video-level, to identify the most relevant frames for action recognition. Experiments in a real-world office environment using the MM-Office dataset demonstrate the superior performance of the proposed method compared to existing methods.
One-Stage Open-Vocabulary Temporal Action Detection Leveraging Temporal Multi-scale and Action Label Features
Apr 30, 2024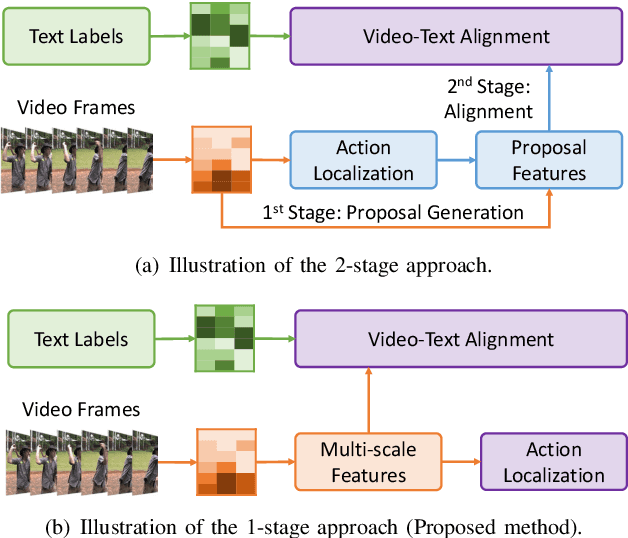
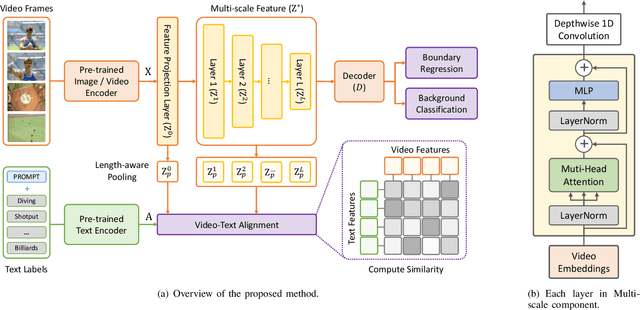
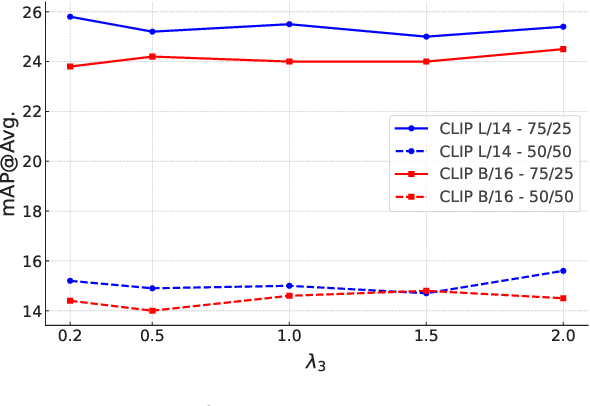
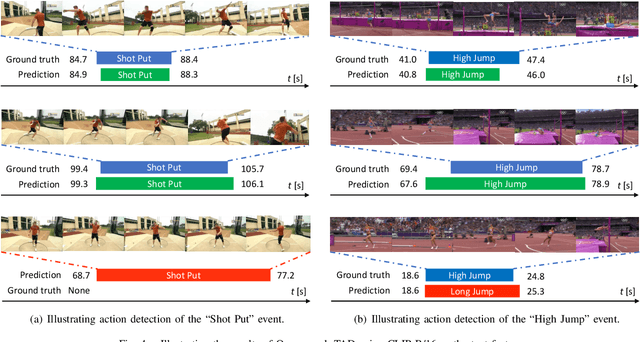
Open-vocabulary Temporal Action Detection (Open-vocab TAD) is an advanced video analysis approach that expands Closed-vocabulary Temporal Action Detection (Closed-vocab TAD) capabilities. Closed-vocab TAD is typically confined to localizing and classifying actions based on a predefined set of categories. In contrast, Open-vocab TAD goes further and is not limited to these predefined categories. This is particularly useful in real-world scenarios where the variety of actions in videos can be vast and not always predictable. The prevalent methods in Open-vocab TAD typically employ a 2-stage approach, which involves generating action proposals and then identifying those actions. However, errors made during the first stage can adversely affect the subsequent action identification accuracy. Additionally, existing studies face challenges in handling actions of different durations owing to the use of fixed temporal processing methods. Therefore, we propose a 1-stage approach consisting of two primary modules: Multi-scale Video Analysis (MVA) and Video-Text Alignment (VTA). The MVA module captures actions at varying temporal resolutions, overcoming the challenge of detecting actions with diverse durations. The VTA module leverages the synergy between visual and textual modalities to precisely align video segments with corresponding action labels, a critical step for accurate action identification in Open-vocab scenarios. Evaluations on widely recognized datasets THUMOS14 and ActivityNet-1.3, showed that the proposed method achieved superior results compared to the other methods in both Open-vocab and Closed-vocab settings. This serves as a strong demonstration of the effectiveness of the proposed method in the TAD task.
Evolutionary Dynamic Optimization Laboratory: A MATLAB Optimization Platform for Education and Experimentation in Dynamic Environments
Aug 24, 2023



Many real-world optimization problems possess dynamic characteristics. Evolutionary dynamic optimization algorithms (EDOAs) aim to tackle the challenges associated with dynamic optimization problems. Looking at the existing works, the results reported for a given EDOA can sometimes be considerably different. This issue occurs because the source codes of many EDOAs, which are usually very complex algorithms, have not been made publicly available. Indeed, the complexity of components and mechanisms used in many EDOAs makes their re-implementation error-prone. In this paper, to assist researchers in performing experiments and comparing their algorithms against several EDOAs, we develop an open-source MATLAB platform for EDOAs, called Evolutionary Dynamic Optimization LABoratory (EDOLAB). This platform also contains an education module that can be used for educational purposes. In the education module, the user can observe a) a 2-dimensional problem space and how its morphology changes after each environmental change, b) the behaviors of individuals over time, and c) how the EDOA reacts to environmental changes and tries to track the moving optimum. In addition to being useful for research and education purposes, EDOLAB can also be used by practitioners to solve their real-world problems. The current version of EDOLAB includes 25 EDOAs and three fully-parametric benchmark generators. The MATLAB source code for EDOLAB is publicly available and can be accessed from [https://github.com/EDOLAB-platform/EDOLAB-MATLAB].