 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Graph Learning via Distributional Invariance of Cause-Effect Relationship
Feb 03, 2026This paper introduces a new framework for recovering causal graphs from observational data, leveraging the observation that the distribution of an effect, conditioned on its causes, remains invariant to changes in the prior distribution of those causes. This insight enables a direct test for potential causal relationships by checking the variance of their corresponding effect-cause conditional distributions across multiple downsampled subsets of the data. These subsets are selected to reflect different prior cause distributions, while preserving the effect-cause conditional relationships. Using this invariance test and exploiting an (empirical) sparsity of most causal graphs, we develop an algorithm that efficiently uncovers causal relationships with quadratic complexity in the number of observational variables, reducing the processing time by up to 25x compared to state-of-the-art methods. Our empirical experiments on a varied benchmark of large-scale datasets show superior or equivalent performance compared to existing works, while achieving enhanced scalability.
CADIS: Handling Cluster-skewed Non-IID Data in Federated Learning with Clustered Aggregation and Knowledge DIStilled Regularization
Feb 21, 2023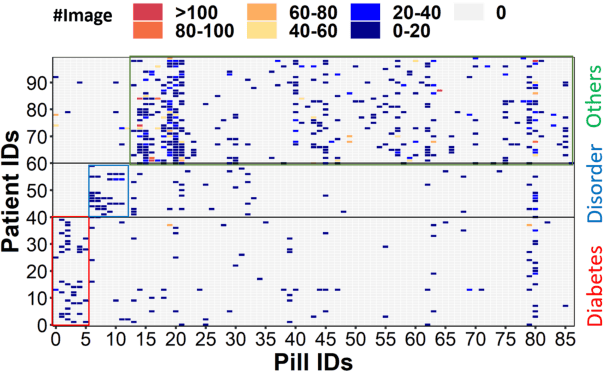

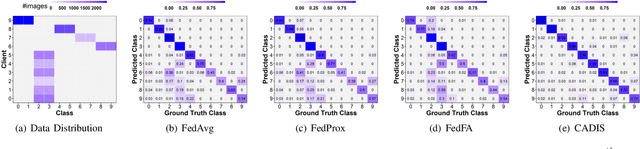
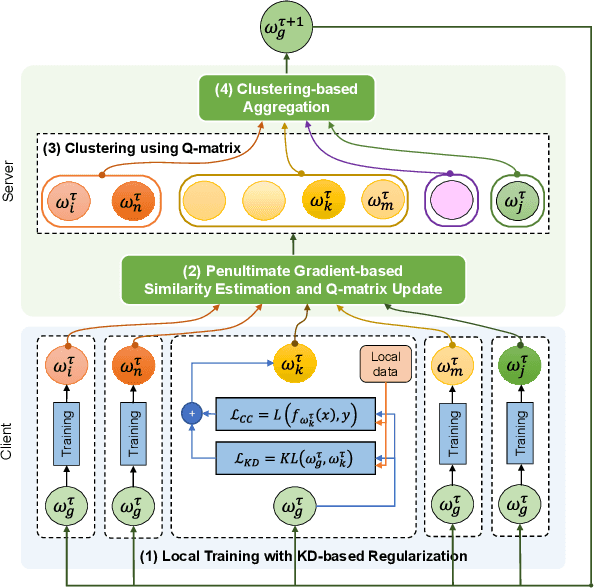
Federated learning enables edge devices to train a global model collaboratively without exposing their data. Despite achieving outstanding advantages in computing efficiency and privacy protection, federated learning faces a significant challenge when dealing with non-IID data, i.e., data generated by clients that are typically not independent and identically distributed. In this paper, we tackle a new type of Non-IID data, called cluster-skewed non-IID, discovered in actual data sets. The cluster-skewed non-IID is a phenomenon in which clients can be grouped into clusters with similar data distributions. By performing an in-depth analysis of the behavior of a classification model's penultimate layer, we introduce a metric that quantifies the similarity between two clients' data distributions without violating their privacy. We then propose an aggregation scheme that guarantees equality between clusters. In addition, we offer a novel local training regularization based on the knowledge-distillation technique that reduces the overfitting problem at clients and dramatically boosts the training scheme's performance. We theoretically prove the superiority of the proposed aggregation over the benchmark FedAvg. Extensive experimental results on both standard public datasets and our in-house real-world dataset demonstrate that the proposed approach improves accuracy by up to 16% compared to the FedAvg algorithm.
FedDRL: Deep Reinforcement Learning-based Adaptive Aggregation for Non-IID Data in Federated Learning
Aug 04, 2022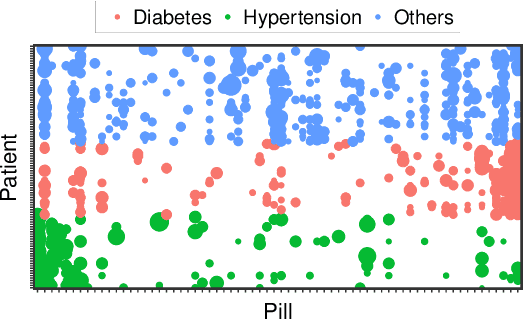

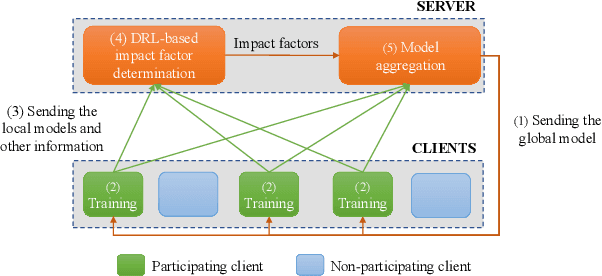
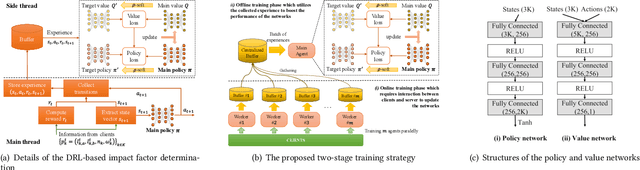
The uneven distribution of local data across different edge devices (clients) results in slow model training and accuracy reduction in federated learning. Naive federated learning (FL) strategy and most alternative solutions attempted to achieve more fairness by weighted aggregating deep learning models across clients. This work introduces a novel non-IID type encountered in real-world datasets, namely cluster-skew, in which groups of clients have local data with similar distributions, causing the global model to converge to an over-fitted solution. To deal with non-IID data, particularly the cluster-skewed data, we propose FedDRL, a novel FL model that employs deep reinforcement learning to adaptively determine each client's impact factor (which will be used as the weights in the aggregation process). Extensive experiments on a suite of federated datasets confirm that the proposed FedDRL improves favorably against FedAvg and FedProx methods, e.g., up to 4.05% and 2.17% on average for the CIFAR-100 dataset, respectively.