 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-FedUL: A Training-Free Federated Unlearning with Provable Skew Resilience
May 28, 2024Federated learning (FL) has recently emerged as a compelling machine learning paradigm, prioritizing the protection of privacy for training data. The increasing demand to address issues such as ``the right to be forgotten'' and combat data poisoning attacks highlights the importance of techniques, known as \textit{unlearning}, which facilitate the removal of specific training data from trained FL models. Despite numerous unlearning methods proposed for centralized learning, they often prove inapplicable to FL due to fundamental differences in the operation of the two learning paradigms. Consequently, unlearning in FL remains in its early stages, presenting several challenges. Many existing unlearning solutions in FL require a costly retraining process, which can be burdensome for clients. Moreover, these methods are primarily validated through experiments, lacking theoretical assurances. In this study, we introduce Fast-FedUL, a tailored unlearning method for FL, which eliminates the need for retraining entirely. Through meticulous analysis of the target client's influence on the global model in each round, we develop an algorithm to systematically remove the impact of the target client from the trained model. In addition to presenting empirical findings, we offer a theoretical analysis delineating the upper bound of our unlearned model and the exact retrained model (the one obtained through retraining using untargeted clients). Experimental results with backdoor attack scenarios indicate that Fast-FedUL effectively removes almost all traces of the target client, while retaining the knowledge of untargeted clients (obtaining a high accuracy of up to 98\% on the main task). Significantly, Fast-FedUL attains the lowest time complexity, providing a speed that is 1000 times faster than retraining. Our source code is publicly available at \url{https://github.com/thanhtrunghuynh93/fastFedUL}.
CADIS: Handling Cluster-skewed Non-IID Data in Federated Learning with Clustered Aggregation and Knowledge DIStilled Regularization
Feb 21, 2023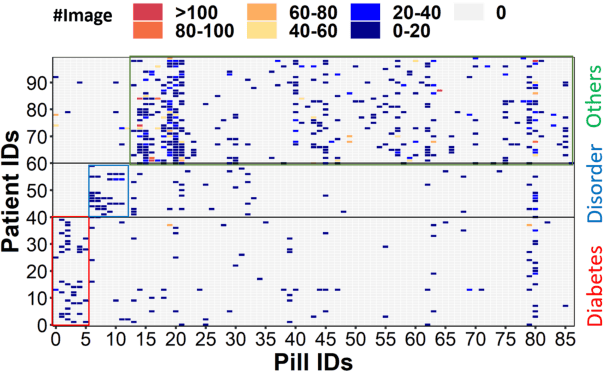

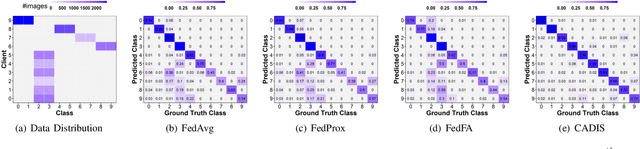
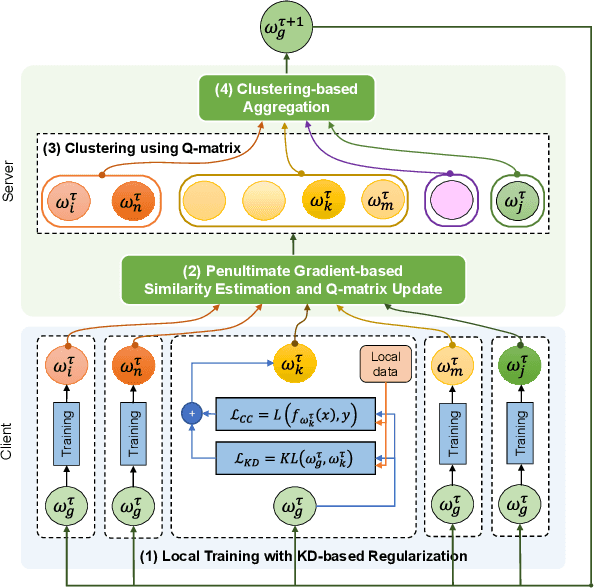
Federated learning enables edge devices to train a global model collaboratively without exposing their data. Despite achieving outstanding advantages in computing efficiency and privacy protection, federated learning faces a significant challenge when dealing with non-IID data, i.e., data generated by clients that are typically not independent and identically distributed. In this paper, we tackle a new type of Non-IID data, called cluster-skewed non-IID, discovered in actual data sets. The cluster-skewed non-IID is a phenomenon in which clients can be grouped into clusters with similar data distributions. By performing an in-depth analysis of the behavior of a classification model's penultimate layer, we introduce a metric that quantifies the similarity between two clients' data distributions without violating their privacy. We then propose an aggregation scheme that guarantees equality between clusters. In addition, we offer a novel local training regularization based on the knowledge-distillation technique that reduces the overfitting problem at clients and dramatically boosts the training scheme's performance. We theoretically prove the superiority of the proposed aggregation over the benchmark FedAvg. Extensive experimental results on both standard public datasets and our in-house real-world dataset demonstrate that the proposed approach improves accuracy by up to 16% compared to the FedAvg algorithm.